






摘要:根据我们的思考,用户的兴趣按照时间维度可以划分为即时兴趣、近期兴趣和长期兴趣。用户的行为是用户兴趣的采样表达,用户 session 级别的行为是用户即时兴趣的表达,代表用户即时兴趣;而近期行为则是近期兴趣的采样,代表用户近期兴趣;长期行为数据则更全面的刻画用户的长期兴趣。关于用户即时兴趣和近期兴趣的建模我们有其他的工作介绍,本文重点介绍我们在用户长期行为建模上的思考。
在用户长期行为建模上,由于用户长期行为数据较多,序列长度较长,而工业级搜索/推荐/广告系统的在线实时打分服务往往有很强的时间约束和吞吐限制,导致用户即时兴趣和近期兴趣建模中广泛使用的 Target Attention 类模型[1,2,3] 由于自身计算复杂度的原因难以直接应用到用户长期行为建模中。解决用户长期行为建模的问题,目前两阶段范式[5,6]的建模方法是一种比较经典的方法,其第一阶段通过训练一个检索模型从原始用户长期行为中搜索 Top-K 与候选商品相关的用户子序列行为,第二阶段预估模型利用 Target Attention 从第一阶段产出的跟候选商品相关的用户序列数据中跟精准的抽取与候选商品相关的兴趣表达,从而实现高效地从用户长期行为序列中抽取用户的长期兴趣。然而两阶段范式也存在一些问题,由于其不是端到端的模型,建模模型和预估模型目标很难保证强一致性,同时也很依赖检索模型准度和复杂的设计。那我们能否换一个思路,重新设计 Attention 算子,使得 Target Attention 也能直接应用到用户长期行为建模中,让模型训练和推理是对用户长期行为的建模是端到端对,保证检索模型和预估模型目标的强一致性呢?在本文中我们提出了一种 Efficient Target Attention(ETA)模型,设计了新的 Target Attention 算子,通过 Hash 函数实现以低成本的位运算来大大降低 Attention 的计算复杂度,从而实现端到端地对用户长期行为进行建模。
Efficient Target Attention(ETA)模型于 2021 年初已推全成为淘宝首页信息流推荐的排序主模型,线上 A/B 测试相比原先两阶段的主模型 CTR 和 GMV 都得到显著的提升,并且至今仍是淘宝首页信息流推荐用户长期兴趣建模的主要模块。
论文下载链接:https://arxiv.org/abs/2209.12212
分享嘉宾|陈启伟 阿里巴巴 算法专家
内容来源|作者投稿
出品平台|DataFunTalk
01
背景
1. Target Attention 与用户序列建模
Target Attention 基于候选商品对用户历史行为进行搜索,过滤行为中的噪声,抽取用户兴趣,在电商搜索/推荐/广告场景中广泛应用,效果显著。如业界典型的 DIN[1]/DIEN[2]/BST[3] 等工作的核心框架都是 Target Attention。
工业级搜索/推荐/广告系统为了保障用户浏览推荐系统时丝滑的体验,其在线实时打分服务往往有很强的时间约束和吞吐限制,打分服务要在数十毫秒内对数千的候选集进行 CTR/CVR 等预估打分,淘宝首页信息排序模型在流量高峰期每秒处理打分请求高达十万+,对打分模型的吞吐和时延要求比较高。在目前 RTP 服务的架构下,在线 CTR 预估服务需要对每个打分请求完成特征的查询、加工和模型计算等几个串行的过程,整个过程涉及在线存储、通信、计算等资源需求。相对商品侧特征数量查询和加工的开销与候选打分商品数成正比,用户序列是 User 侧特征,在一次打分请求只需要查询和加工一次,在一次打分请求中占整体特征的比例也比较低,即使引入更长的行为序列对整个模型特征查询和加工的开销的比例提升也比较少;而 Target Attention 模型基于候选商品对用户历史行为进行精细搜索,计算开销几乎随着用户行为序列长度线性增长,时间复杂度为 O(BLD),其中 B 为候选打分商品数,L 为序列长度,D 为单次计算的复杂度,限制了模型对超长序列建模,即便是非常仔细的系统优化以及设计后 DIN/DIEN/BST 等模型能在线也仅能处理到 100 左右的序列长度[4]。
既然 Target Attention 的计算复杂度与序列的长度有关,有一些思路是先对长期行为序列做一些信息压缩,比如通过 Memory network 等方法,先将大量的用户行为压缩成为几个固定大小的兴趣 memory[4]。然而一方面有限的兴趣 memory 向量维度难以完整的记录用户原始的行为信息,信息的抽象个归纳过程中存在信息损失,另一方面单个兴趣槽因为融合了大量的行为而存在大量的噪声,难以再与候选商品进行同一个向量空间下的 attention 来准确候选商品建模与候选商品之间的相关兴趣。这类方法往往难以取得理想的效果[5]。
既然预先将大量的用户行为压缩成为几个固定大小的兴趣的方法存在较大的信息损失,难以逼近直接进行 Target Attention 的效果,我们还是要从原始行为角度出发来抽取用户的长期兴趣。然而从原始行为出发进行 Target Attention 又由于计算复杂度高限制其在工业级搜索/推荐/广告系统应用。那我们能否重新设计 Target Attention,解决 Target Attention 本身的问题,使其能应用到长序列中。
2. 重新思考 Target Attention
回顾一下 Target Attention 的计算公式:
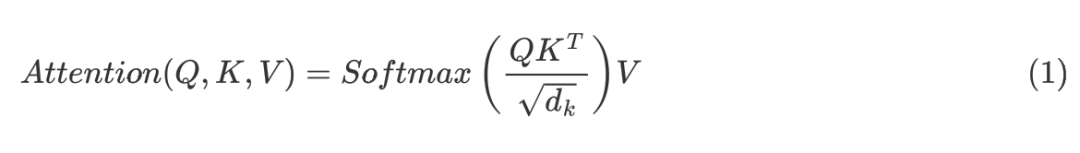
经过 Softmax 之后,目标商品和行为序列商品计算的 Attention Score 中,值小的会转化为趋近于 0,而值大的才起作用。这就意味着,Q*KT 中,与 Q 相近的 K 才需要被考虑,而不相近的可以近似被忽略。因此如果我们将原来直接对整个序列进行 Attention 转化为:先从序列中高效检索 TopK 个相似商品,再对这 TopK 个商品进行精细 Target Attention,则可以大大降低 Attention 的浮点数计算量。那现在的问题是,我们要如何实现从序列中高效检索出与目标商品相似的 TopK 个相似商品呢?
3. 现有检索方法及问题
目前在排序模型中对用户超长行为序列进行 TopK 快速检索的方法主要可以分为两类,一类是 Approximated Nearest Neighbor Search(ANN),代表工作如 SIM Soft[5],另一类是结构化属性倒排索引,代表工作如 SIM Hard[5]、UBR4CTR[6]。
Approximated Nearest Neighbor Search(ANN)是一种近似检索,需要预先构建检索引擎,注重检索效率,通常应用于亿规模的候选集检索,比如推荐系统的召回引擎。常见的检索方法如:层次聚类、Product Quantization(PQ)、Hierarchical Navigable Small World (HNSW) 等。如 SIM Soft 中采用与 CTR 预估任务解耦的预训练的 Embedding 来构建 ANN 的索引,这种方式由于检索任务和 CTR 任务并非端到端训练的,预训练任务和 CTR 任务存在一定的 Gap,导致检索任务检索出来的 TopK 不完全是 CTR 任务所需要的真实 TopK。排序问题中 Target Attention 需要的是在用户成千上万历史行为上轻量级、精准检索,不需要检索性能达到亿规模的性能。
结构化属性倒排索引的方法在商品推荐场景通过是使用商品的类目体系离线构建倒排索引,如构建 key1-key2-value 的索引,key1 是用户 ID,key2 是类目 ID,value 是同类目的子序列。根据待打分的 User 和目标商品类目,检索出对应的同类目子序列。但是这种人工设计的结构化属性与点击率/转化率的预估目标有较大的 Gap。另外,类似内容推荐、短视频推荐没有商品推荐中比较规范的类目结构化属性,这种方式通用性也会比较差。
那是有办法克服 ANN 和结构化属性倒排索引的缺点,设计一种高效的 Target Attention,让模型训练和推理时对行为序列的精准检索与模型端到端,保存检索单元与任务建模目标的强一致?
02
Efficient Target Attention Net
1. Multi-Round LSH Attention & SimHash

图1 Multi-Round LSH Attention
两个向量可以在一个二分类的球面上多次旋转投影,越相似的向量在多次旋转投影中落到同一个分类面的概率就越大。
Locality-sensitive hashing (LSH) 是一种高维向量空间快速检索 K 近邻的方法。通常两个向量越相似,则可以以越高的概率获得相同的hash映射。由于概率存在一定的误差,通过 Multi-Round LSH 进行多轮 Hash,即可减少误差,提升精准度。(精准检索)
在 LSH 函数的设计上,我们采用了只有两个 Hash 桶的Hash函数,如图1所示。只有两个 Hash 桶的 Hash 函数 Hash 的结果取值是 0 或 1 的二进制位,而进行 Multi-Round LSH 的结果是一个二进制编码,这恰恰正是 SimHash,此时两个二进制编码的相似度可以用 HanmingDistance 度量。两个二进制 Hash 签名的 HanmingDistance 的计算是两个两个二进制数的异或运算和异或结果 1 的计数,二进制的运算效率要远远高于两个浮点数向量的内积。(高效检索)
最后将Dot-Product Attention转化为LSH Attention, HashQ=SimHash(Q)、HashK=SimHash(K),将 Attention 中 Query 通过昂贵的内积运算对 Keys 检索的过程转化为高效的二进制运算。(端到端检索)

2. Efficient Target Attention
图 2 是 Efficient Target Attention Net(ETA-Net) 的模型结构图,ETA-Net将用户侧和商品侧信息作为输入,预测用户 u 对商品 i 的点击率。ETA-Net 包含两个主要的部分:ETA 和 BaseModel,ETA 部分建模用户超长行为序列,BaseModel 建模其他特征。BaseModel 将用户特征、商品特征、Context 特征和经过 Target Attention 建模的用户近期短行为序列,以及经过 ETA 处理的用户超长行为序列 Concat 再一起,并经过多层 MLP。
ETA 首先通过 SimHash 算法为打分商品和用户历史行为生成 Hash 签名,之后通过HanmingDistance 为每个从中挑选出最相似的 TopK 个和对应的,最后再利用进行标准的 Target Attention。
ETA 算法的计算过程可以形式化表示为:

其中,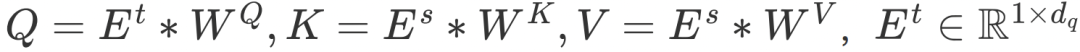 是待打分商品的 Embedding 向量,
是待打分商品的 Embedding 向量,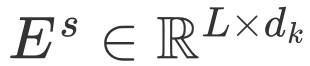 是用户历史行为的 Embedding 向量,
是用户历史行为的 Embedding 向量,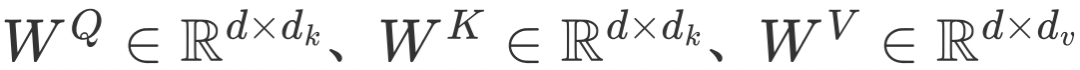 分别是线性投影矩阵。
分别是线性投影矩阵。
需要强调的是 Hash 函数是作用在 Q 和 K ,而非 Et 和 Es。

图2 ETA模型结构图
(1)End-to-end Learning
现有的两阶段方法中,检索模型和 CTR 模型是单独训练的,两个任务信息存在一定的 Gap,导致检索模型检索出来的 TopK 不完全是 CTR 任务所需要的真实 TopK,从而损害了最终的性能。而在 ETA-Net 中 ETA 和 BaseModel 整个是端到端训练和更新了,SimHash 算法不涉及任何可训练参数,直接对 Attention 的和进行 Hash 签名,随着 Attention 部分的训练和更新,对应和的 SimHash 签名也会进行更新,整个模型是保障一致性的。
(2)复杂度分析
Target Attention模型的计算复杂度主要来源于两块:一块是 Q=Et*WQ,K=Es*WK,V=Es*Wv,另一块是 Q*K 和 A*V 的计算。另外 Target Attention 有一个特性,一次打分请求通常是对应用户的 B 个候选商品进行打分,Q 是 Item 侧特征,需要进行 B 次运算,而 K 和 V 是 User 侧的特征,在与 Q 进行交叉之前只需要进行 1 次运算,在与 Q 进行交叉之后计算代价会膨胀 B 倍。
用Nc表示候选打分商品数,L 表示序列长度,K 表示 topK 的子序列长度,d 表示向量的维度,dp表示线性投影后的维度,M 表示平均一次打分请求从倒排索引出 SubKey 的个数,各个模型的计算复杂度对比如表 1 所示:
表1 不同算法的模型计算复杂度

表2 不同算法的检索引擎复杂度和带宽传输商品数
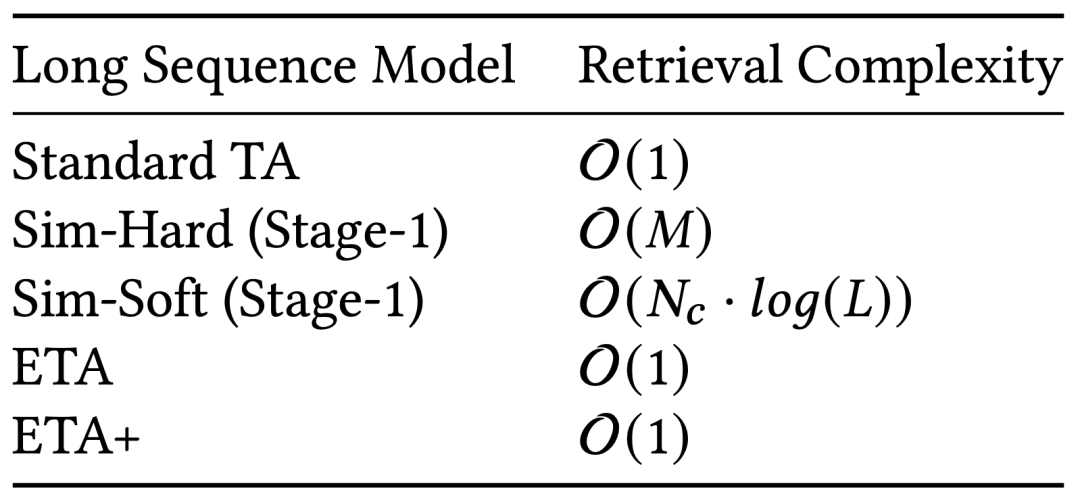
表 1 对比了不同算法的模型上的时间复杂度,其中 SIM Hard 和 Soft 过早让 Item 侧的特征与 User 侧的用户行为序列交叉,导致 K 和 V 的计算复杂度增加了M和Nc倍。ETA 在 Q 和 K 的计算中需要增加SimHash签名的计算,其计算代价通常小于 SIM Hard K 和 V 的计算代价。ETA+ 优化是具体实现上对 ETA 进行的优化,可以省去 SimHash 签名的计算过程。
03
工业实现
ETA-Net 的系统架构如图3所示,模型训练在 AOP 上完成,在线部署在 RTP 上。
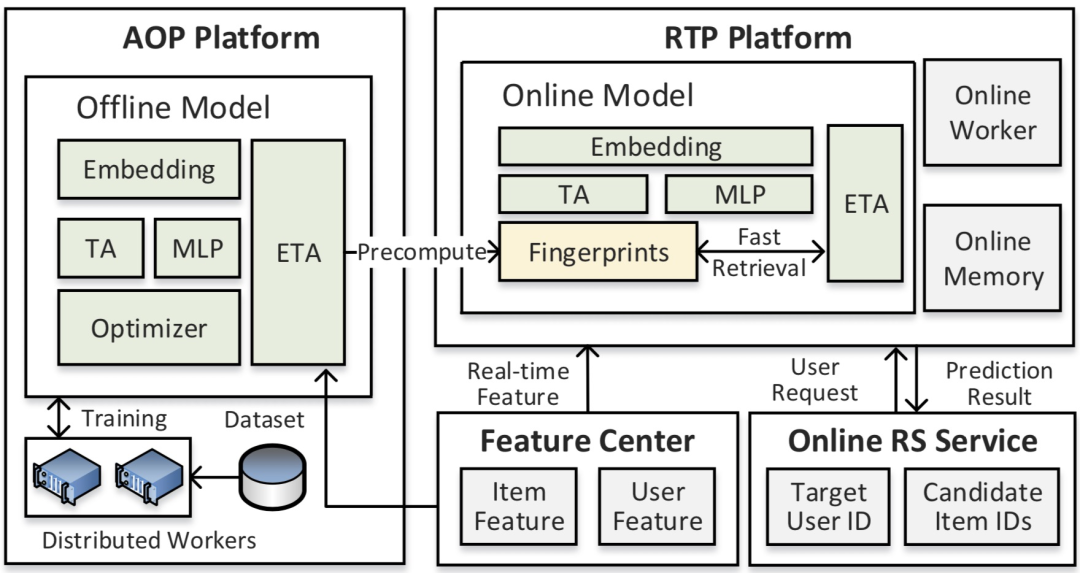
图3 ETA训练和推理的系统架构图
在训练阶段,目前 AOP 平台主要在 Hippo 的混部 CPU 集群上训练,CPU 天然对位运行有友好。在 ETA 模型结构确定之后,我们针对模型的 ETA 模块进行了 OP Fusion 等优化,大大提高了 ETA 模块的执行效率和降低内存带宽。
在线部署时,我们与 RTP 和 GPU 团队同学合作对模型在线推理能力进一步优化,进一步降低计算复杂度和内存复杂度。
预先计算 SimHash 签名,节省在线推理时 SimHash 签名的计算过程。SimHash 生成和的 Fingerprint 的过程可以通过 Offline2Online 的方式在构建模型索引时对 Item 表预选计算并存储在 Embedding lookup table 中,把生成 Fingerprint 的过程从计算转化为在内存查表,大大减少计算复杂度。
使用 Int64 来存储二进制签名。对于具有 m 位的二进制指纹,我们可以使用 log(m) 位的整数来表示它[7,8]。在我们的在线环境中,待计算相似度的向量为 128 个 float32,生成的 Fingerprint 用 4 个 int64 表示,只需要扩展 6% 的额外存储。
GPU 定制优化。由 GPU 团队同学针对 ETA 模型对 Tensorflow 的 Xor、TopK 和 Gather 等 OP 进行重写和深度优化,对模型在线推理性能也有相当大的提升。
04
实验
为了验证我们 ETA 模型相比当前 SOTA 模型的有效性,我们在公开数据集和生产数据集上分别进行了对比实验,表 3 显示了各个数据集数据规模具体情况。
表3 公开数据集与生产数据集

我们将 ETA 和以下主流的模型进行对比。
Pooling-based DNN:利用 Avg-Pooling 来将用户近期行为序列编码成固定大小的向量。
DIN:通过 Target Attention 抽取用户的面对不同目标商品时近期兴趣点的变化。
DIN (Long Sequence) :DIN 加上用户长期行为序列的 Avg-Pooling。
SIM:SIM 是一种基于检索引擎的两阶段的超长用户行为建模方案。
UBR4CTR:UBR4CTR 也是一直两阶段的超长用户行为建模方案,通过特征选择模块选取第一阶段查询的 query,并通过 BM25 进行检索返回 TopK 个相似商品。
SIM/UBR4CTR + timeinfo:引入时间间隔属性的 SIM 和 UBR4CTR 方案
表4 公开数据集和生产数据集实验结果
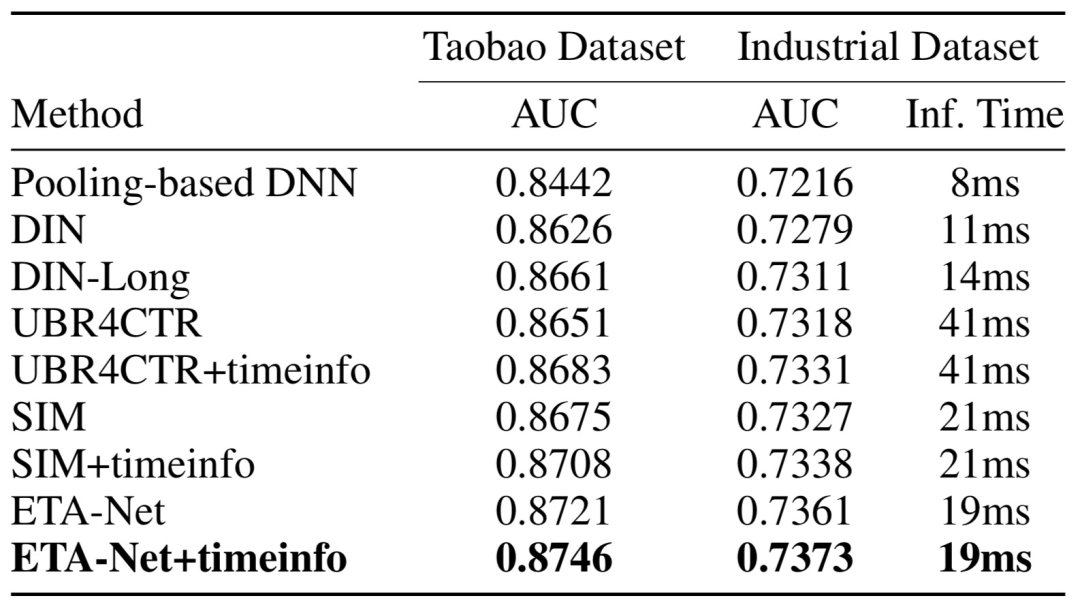
表 4 显示了公开数据集和生产数据集的实验结果。在公开数据集上,与所有基准相比,我们的 ETA 表现最好。DIN 效果明显优于 Avg-Pooling DNN,表明引入 Target Attention 可以大大提升行为序列信息抽取的效果。DIN (Long Sequence) 效果优于 DIN,表明进行超长用户行为序列建模对于 CTR 模型有帮助。
在淘宝首页信息流推荐场景,CTR 模型 AUC 提升 0.1%,可以给每天在线带来百万次的实际点击。在生产数据集上,与所有基准相比,ETA 的表现最好。与 SIM 和 UBR4CTR 相比,我们的 ETA 分别提升了 0.34% 和 0.43%。与 SIM + timeinfo 和 UBR4CTR + timinfo 相比,我们的 ETA + timeinfo 分别提升了 0.35% 和 0.42%。
05
业务效果
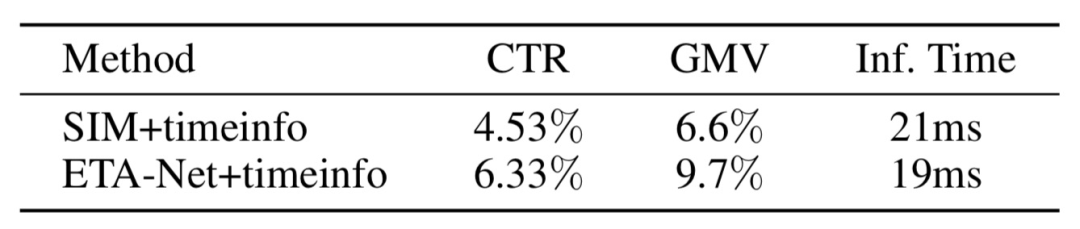
表 5 是 SIM[7] 和 ETA 在淘宝首页信息流推荐的效果,相比上一代主模型 CTR +1.8%,IPV +2.8%,GMV +3.1%。
表5 ETA 模型在线效果
ETA 的工作最早在 2020 年底完成,2021 年在淘宝首页信息流推荐场景全量,成为新一代排序主模型。目前 ETA 模型日常每秒承担 6W+ QPS 的打分请求,双十一峰值打分 QPS 达到了 12W+。
06
总结
本文我们提出了用于 CTR 任务超长用户行为序列建模的 Efficient Target Attention(ETA) 模型。据我们所知,ETA-Net 是第一个能够以端到端的方式对长序列用户数据进行建模并且在大规模推荐任务上具有高成本效益的方法。此外,我们还对 ETA-Net 的工程实现进行更细致的优化,使得 ETA-Net 能部署在淘宝首页信息流推荐场景和推荐平台服务的众多推荐业务上,ETA-Net 成为淘宝首页信息流新一代排序主模型,日常每秒承担 6W+ QPS 的打分请求,双十一峰值打分 QPS 达到了 12W+。
07
引用
[1] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1059-1068.
[2] Zhou G, Mou N, Fan Y, et al. Deep interest evolution network for click-through rate prediction[C]//Proceedings of the AAAI conference on artificial intelligence. 2019, 33(01): 5941-5948.
[3] Chen Q, Zhao H, Li W, et al. Behavior sequence transformer for e-commerce recommendation in alibaba[C]//Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data. 2019: 1-4.
[4] Qi Pi, Weijie Bian, Guorui Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Practice on long sequential user behavior modeling for click-through rate prediction. In KDD. 2671–2679.
[5] Pi Q, Zhou G, Zhang Y, et al. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020: 2685-2692.
[6] Qin J, Zhang W, Wu X, et al. User behavior retrieval for click-through rate prediction[C]//Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2020: 2347-2356.
[7] Charikar M S. Similarity estimation techniques from rounding algorithms[C]//Proceedings of the thiry-fourth annual ACM symposium on Theory of computing. 2002: 380-388.
[8] Manku G S, Jain A, Das Sarma A. Detecting near-duplicates for web crawling[C]//Proceedings of the 16th international conference on World Wide Web. 2007: 141-150.
今天的分享就到这里,谢谢大家。

|分享嘉宾|

陈启伟
阿里巴巴 算法专家
陈启伟,中国科学院大学硕士。淘宝首猜商品推荐算法精排负责人,负责排序算法和算法平台相关的工作。研究领域包括大规模机器学习、推荐系统、自然语言处理等。研究成果发表于KDD/CIKM等会议,其研究工作均落地于实际系统。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









