







关注我们,一起学习~
标题:Scenario-Adaptive and Self-Supervised Model for Multi-Scenario Personalized Recommendation
地址:https://arxiv.org/pdf/2208.11457.pdf
会议:CIKM 2022
公司:阿里
1. 导读
本文关注多场景推荐相关的问题,当然在其他场景也可以有借鉴的地方。这些场景在用户和商品中有部分重叠,而不同场景的分布不同。多场景建模的关键点是有效地最大化整个场景信息的使用,并为多个场景中的用户和商品细粒度地生成自适应表征。多场景建模存在的三个挑战:
(1)在多场景之间缺乏细粒度和解耦的信息迁移控制。
(2) 未充分利用整个空间样本。
(3) 商品的多场景表征解耦问题。
本文提出了一种场景自适应和自监督(SASS)模型来解决上述三个挑战。具体来说,设计了一个具有场景自适应门单元的多层场景自适应迁移(ML-SAT)模块,以非常细粒度和解耦的方式选择和融合从整个场景到单个场景的有效迁移信息。为了充分利用整个空间样本的作用,引入了包括预训练和微调的两阶段训练过程。预训练阶段基于场景监督的对比学习任务,其中训练样本来自标记和未标记的数据空间。该模型在用户端和商品端都是对称创建的,因此可以获得不同场景中商品的不同表示。
2. 问题定义
2.1 多场景匹配问题
场景集合,他们共享特征空间和标签空间。对于场景,训练数据属于特定域的分布,多场景匹配问题可以定义为下式,其中V为候选商品集合,e是在场景中用户和商品的表征向量,sim为相似度函数,最后取前K个商品。
多场景任务可以看成是一个多域学习,具有以下三个特点:
(a)所有场景具有相同的用户/商品类型,并享有共同的特征模式;
(b)所有场景都有相同的学习目标(多个输入和一个目标);
(c)多场景学习的关键点在于场景之间的信息共享和迁移,从而可以同时提高所有场景的性能。
3. 所提方法
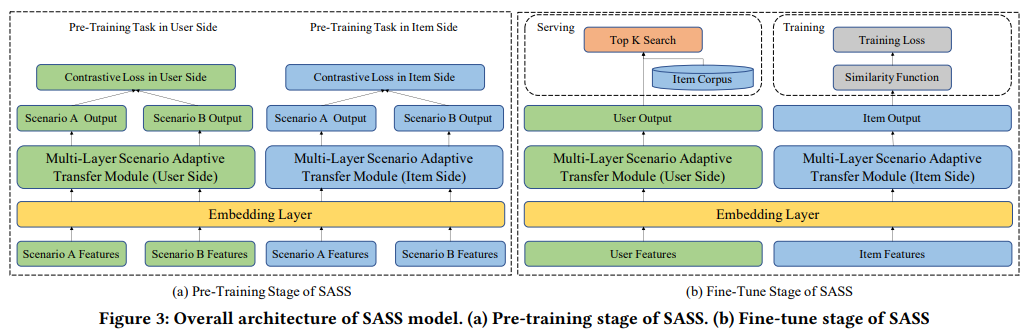
SASS包含两个阶段,预训练阶段和微调阶段。
预训练阶段:本阶段有用户端和商品端预训练任务。这两个任务都具有相同的模型结构。embedding层在两个任务之间共享,预训练阶段基于自监督的对比学习策略。
微调阶段:微调阶段的模型结构利用双双塔框架分别生成用户和商品表征向量。微调阶段的embedding层和网络权重从预训练阶段恢复,以便微调阶段的模型可以重用整个样本空间中训练好的信息。
3.1 基于对比学习的自监督框架
这里采用曝光点击和未点击的数据进行训练,
在用户端,同一用户在不同场景中的行为可以被视为一种数据扩充机制。然后,提出了一种多层场景自适应迁移模块(ML-SAT),用于在不同场景中为同一用户生成不同的表征向量。最后,引入对比损失函数作为优化损失,以最大化不同场景中同一用户的不同潜在表征之间的一致性。如果用户u已访问k个场景,简单地分割这些场景,并将它们组合起来生成 k*(k−1)/2个对比学习样本。
在商品方面,同一商品在不同场景中的曝光和交互也可以被视为数据扩充机制。对于同一商品构建孪生网络和对比损失,和用户端一样,对样本组合进行类似的操作,生成多个样本。
3.1.1 特征组成和embedding层
在用户端,每个训练样本都包含用户画像、场景上下文特征和两组用户场景交叉行为特征,这些特征分别来自两个场景。具体而言,用户画像包含年龄、性别等。场景上下文特征主要包括场景ID。用户场景交叉行为特征包括相应场景中的用户行为序列、类别偏好和用户统计特征。
对于用户行为序列特征,得到交互序列中每个商品的embedding后,通过相应的池化策略得到用户的行为表征。作者利用自注意机制作为池化操作。
在商品侧,商品画像包含商品ID、类别ID、帐户ID等。商品场景交叉特征主要包括相应场景中的商品统计特征。
为了突出场景上下文特征的重要性,引入了单独的辅助网络来建模场景特征,其中x为场景上下文特征,f为多层感知机
3.1.2 ML-SAT
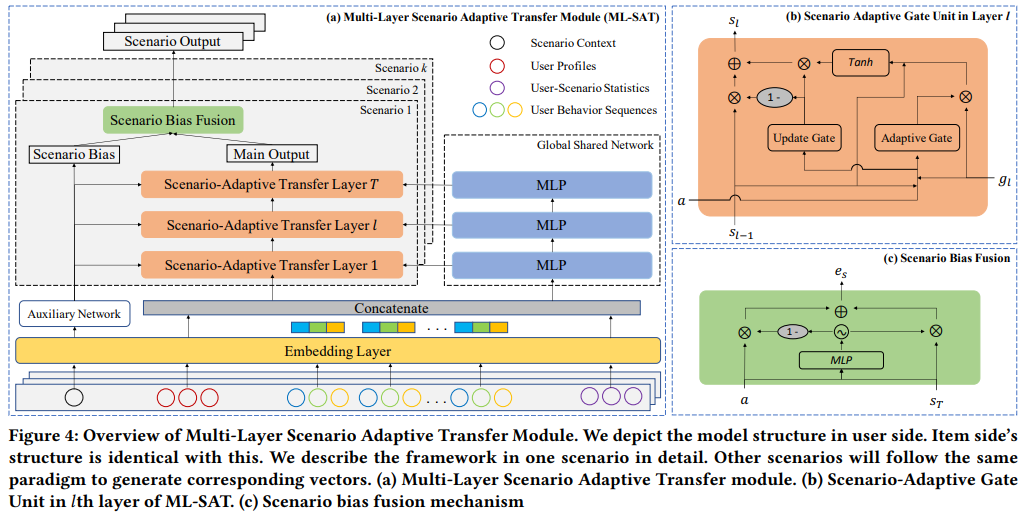
商品侧和用户侧的网络是一样的,所以这里只介绍用户侧的网络。
为了充分利用整个场景信息并规范从整个场景到特定场景的细粒度信息迁移,引入了一个全局共享网络来学习所有场景的信息,并提出了一个多层场景自适应迁移模块(ML-SAT)作为每个单独场景的场景特定网络。全局共享层用所有场景中的数据进行训练,对于场景特定的各个层采用对应场景中的数据训练。
基于GRU,在每个网络层中,设计了一个具有显式门机制的场景自适应门单元,以调节从整个场景到特定场景的细粒度信息迁移。如图4(b)所示,场景自适应门单元可公式化如下,其中表示第层的全局共享层的输出,表示场景网络中第层的输出,W为可学习参数,a为前面场景上下文信息辅助网络的输出。
3.1.3 场景偏置融合
在上述的门控机制后,我们可以得到场景对应的输出,场景上下文特征在区分场景的过程中是很重要的,因此把场景网络的输出a作为偏置将其融入最后的输出表征中,如图4c,公式如下,其中为场景网络输出。
3.1.4 自监督优化目标
对于在相应场景中具有两组场景特定特征的每个训练样本,可以分别获得相同用户或商品的两个输出向量,表示为和。预训练任务的目标是提取不同场景之间的共性和模型修正。因此,采用自监督对比损失作为优化损失。具体而言,对于batch size为N的训练样本, 经过ML-SAT后可以得到2N个向量。以和作为正样本对。其他2(𝑁 − 1)个场景向量被视为负向量。损失函数为下式,
最后的损失为:
3.2 微调阶段
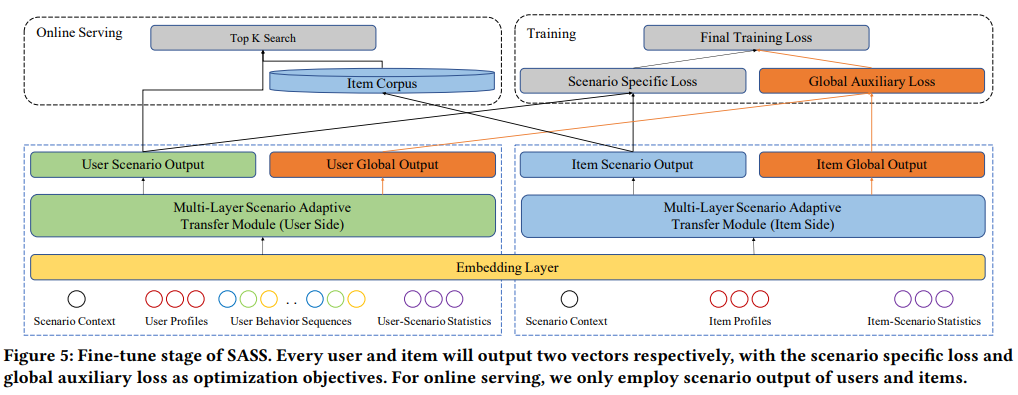
3.2.1 特征和embedding层
微调阶段的训练样本为从目标场景中提取的点击数据。用户一次只能访问一个场景,因此一个训练样本中的特征仅包含单个场景中的特征。用户端特征包括用户画像、场景上下文特征(场景ID)、用户的行为序列、统计特征和目标场景中用户的偏好特征。商品侧特性包含项目画像、场景上下文特性(场景ID)、统计特性和目标场景中项目的偏好特性。然后,如图5所示,用户侧特征和商品侧特征被分别送到embedding层和上层ML-SAT模块中,以在相应场景中为用户和商品生成最终场景特定向量。ML-SAT在微调阶段的embedding层和网络权重是从预训练阶段恢复的。
3.2.2 微调优化目标
微调阶段的最终优化损失是场景特定损失和全局辅助损失的组合。
场景特定损失:与其他匹配任务类似,调整成对损失以优化微调匹配任务。对于一个场景s, 微调阶段的第k个训练样本是一个三元组。u表示用户表征向量,p和n分别表示相应的正商品向量和商品项向量。使用负采样策略从整个候选集中随机抽样负样本。场景特定损失函数定义为下式,
全局辅助损失:在微调阶段,如图5所示全局共享网络为每个样本输出一个表征向量,全局共享网络使用来自所有场景的样本进行训练。因此,输出可以被视为全局视角中的用户或商品表征。在全局范围内对用户和商品的相似性进行建模有利于提升性能。因此,引入了全局辅助损失,定义为下式,
总损失为
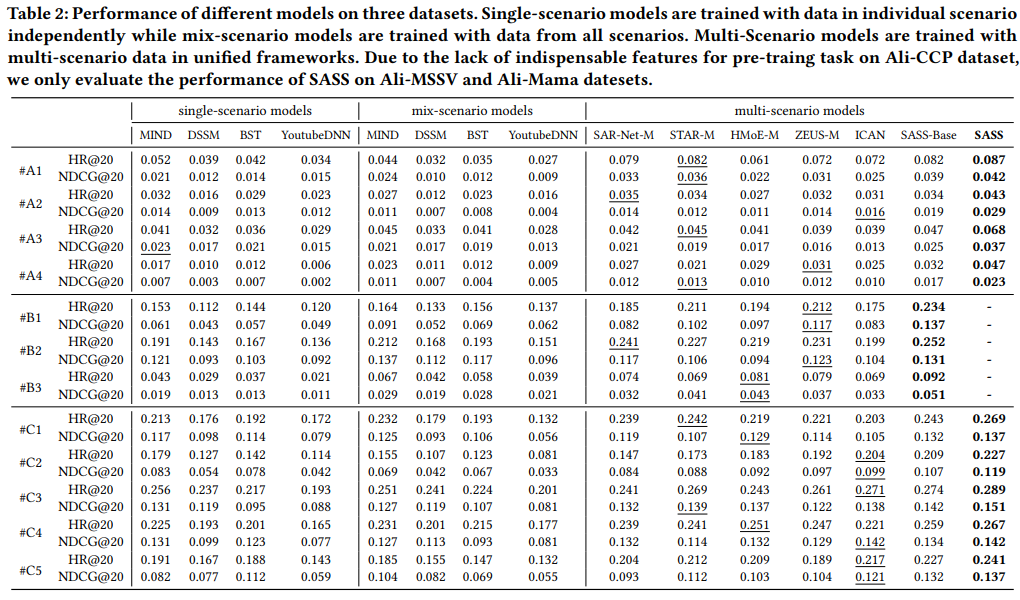
4. 结果















 2794
2794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









