






作为《阿里妈妈搜索广告CTR模型的“瘦身”之路》的姊妹篇,本文将结合团队发表的 CIKM 2021 两篇论文,详解我们在模型瘦身之路上的延续性思考与实践。姊妹篇已经总结搜推广的模型迭代开始步入“业务发展对算法提效的述求持续高涨与算法提效所依赖的算力红利日益消减”的矛盾深化时期,我们较为坚决地通过系统性的算法优化将模型迭代路径由“资源狂魔的大模型”逐渐转变为“资源友好的小模型”,打破模型迭代的算力瓶颈。数T模型摇身一变几十G模型,轻装上阵之后,多人多场景多模型多版本的“顺畅、高效、敏捷”的迭代节奏又重新回来。欣喜之余我们开始回顾与思考,纵然模型参数规模决定了信息容量和预估上限,但简单粗暴的“参数扩容”如果考虑到资源的投入产出比,那么边际效益会越来越不划算。偌大规模的模型参数必然存在着信息冗余和不利于泛化性表征的部分,这是可以被精巧设计和低碳瘦身的破局点。
前文《三篇SIGIR详解阿里妈妈搜索广告CTR模型演进》中已经对常见的 CTR 模型优化方向按照模型组件的结构特点进行分门别类,可以发现从参数规模的角度来说,相较于 Hidden Layer,Embedding Layer 在大规模离散稀疏特征场景下起到了主导性地位,自然而然模型低碳瘦身的关键也在于此。Embedding Layer 形象来看就是一张二维big table,行方向就是对应 Feature Volume,列方向就是对应 Embedding Dimension,这两个方向的维度共同决定了 Embedding Table 的大小。我们正是从这两个角度分别展开优化,考虑到 Embedding 学习收敛效率较低的特性(直通车场景Embedding Layer需要数月级别数据收敛,Hidden Layer 仅需要数周级别数据收敛),Embedding Layer 的结构设计不宜像 Hidden Layer 一样纷繁复杂。作为整体模型结构大厦的坚实底座,Embedding 优化需要简洁高效且实用,秉持着这一设计原则,下文详细介绍最近的思考与实践,希望对相关工作有所启发。
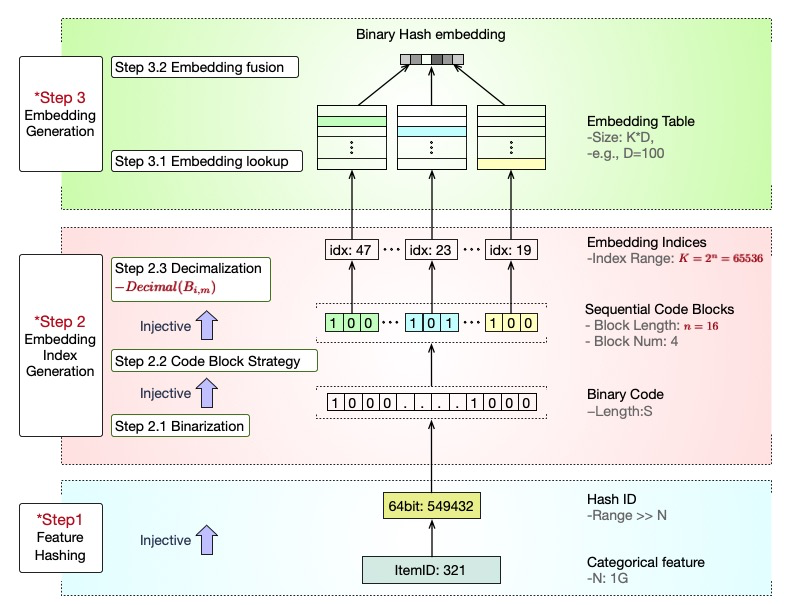
▐ Feature Volume:Binary Code based Hash Embedding
搜推广的模型和感知类的模型(NLP和图像等)有较大的差异,后者模型规模主要由 Hidden Layer 的参数所决定,但是前者基本和特征的规模成正比,所以从 Embedding Layer 的行方向即 Feature Volume 进行优化,会有立竿见影的效果。不同的特征域,值域范围有很大的差异,其中 ID 类的类别特征例如 userid、queryid 和 adid 等往往规模很大,且动态更新非常频繁,也是模型预估精度的基本保障。这一类特征常见的处理思路往往在无冲突表达和有冲突表达之间寻找平衡,背后的取舍就是在于信息表达是独占还是共享。
无冲突表达认为每一个id的独特性需要充分保留,通过参数分布式建设等系统能力的提升将所有id都做到一一映射,以 One Hot 编码方式为代表,这类方法对工程基建要求较高且需要设计复杂的特征准入准出策略来适应特征的分布动态变化,从而模型规模一直维持较为均衡的高水位状态。该方向为了可以进一步压缩 Embedding Table,开始研究更为紧凑的编码方式。其中基于 KD[1] 编码的技术发展最为热闹,包括后面延伸出来的 MCNE[2]、DPQ[3]和MGQE[4] 等技术,核心思想就是引入编码和解码机制将一个大矩阵近似拆成两个小矩阵,从而达到模型压缩的目的。但是这一类方法拆解完的第一个小矩阵可以发现依然采用无冲突的 id 映射表达,这在高维且动态更新的实际环境中,参数规模依然不小且仍然需要复杂的特征更新换代策略,部署维护较为繁琐。
有冲突表达是指在有限的系统能力下牺牲一部分信息独特性,通过设计合理的共享组件使得模型规模保持恒定的低水位状态。冲突的设计分为两种模式,人为和随机。人为冲突设计一般以 id 的频次作为阈值,高于阈值部分依然保持无冲突的一一映射关系,低于阈值部分或者统一冲突到相同默认值、或者设计学习模式让低频和高频id产生关联[5]等。人为冲突模式阈值设置较为讲究,且特征动态准入准出使得表征切换不够平滑。随机冲突一般以 Hashing Trick 技术为典型代表,通过控制“模”长来控制模型规模,为了解决单 Hash[6] 的冲突率较高的问题,后面延伸出来 MultiHash[7] 全局多 Hash、HybridHash[8] 高频无冲突低频多 Hash、QR trick[9] 互补商余法等技术都能够降低冲突率,使得id特征的信息独特性保留完整一些。Hashing Trick 技术因为非参数化数据不依赖,实现起来较为简单,冲突率要是控制到位,模型压缩比和效果保留率之间可以取得不错的平衡。
考虑到系统简洁高效鲁棒性好,我们选用 Hashing Trick 技术路线作为实际算法迭代方向,并在姊妹篇中已经提到我们复现 MultiHash 技术且做了适配升级并开始服务生产。我们进一步思考,现有的 Hashing Trick 都依赖取“模”操作,该操作是产生冲突的主要原因。我们提出一种新颖的基于二进制转化的分组合并操作来升级取模操作,该技术 BH(Binary Code based Hash Embedding)不仅能够做到理论上保持 id 表征的唯一性、大幅度降低冲突率,还能够统一现有 Hashing Trick 的实现方案,并且通过分组合并策略的调整能够适配不同模型压缩比从而适应不同场景的应用需求(例如端上模型等)。实践表明该方法能够获得极高的模型压缩比,依然保持较完整的模型预估效果。
论文详解版请查阅另两篇推文
论文下载:
https://arxiv.org/pdf/2109.02471.pdf
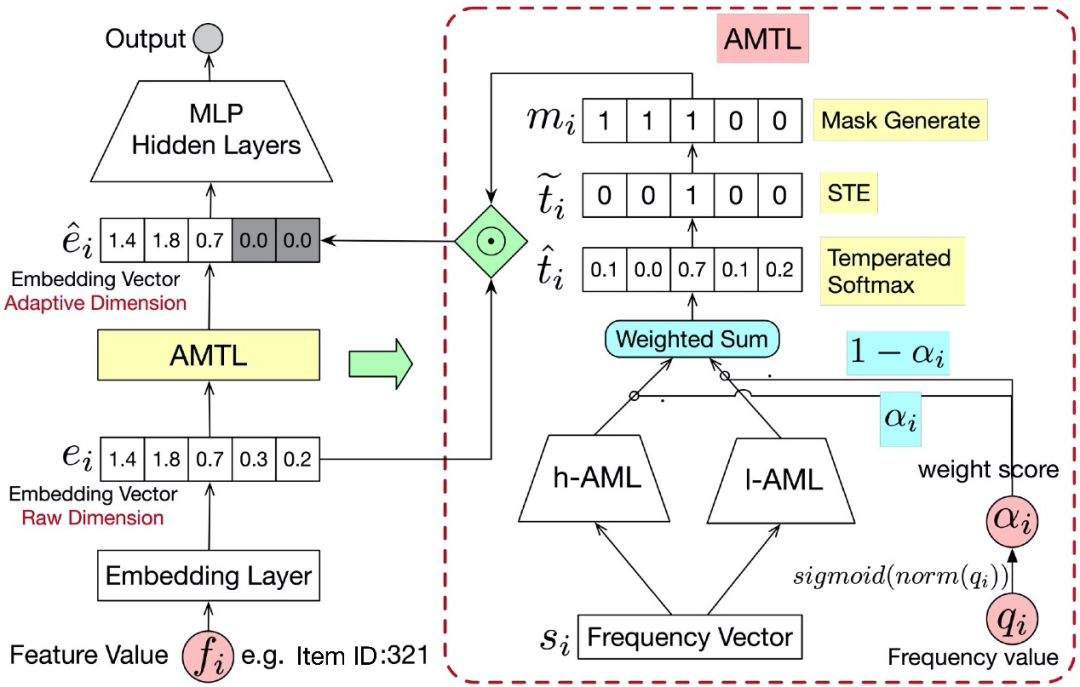
▐ Embedding Dimension:Adaptively-Masked Twins-based Layer
上文提到ID类特征是 Embedding Table 的重中之重,而且因为特征值域范围非常广,亿级别的ID量(userid、queryid、adid等)需要更高维度的Embedding来进行丰富的信息表征,实践中我们会赋予百量级的Dimension。常规 Embedding Dimension 的设置是固定且统一的,对于符合二八定律的ID特征来说(例如前20%的adid贡献了80%的展现)这种设置方案对于大量低展现的id来说不仅浪费存储空间还容易带来过拟合的次优效果。
目前有较多工作开始优化这个问题,我们梳理认为主要分为两类:基于规则和基于 NAS(Neural Architecture Search)。基于规则的方法,例如GroupReduce[10]、Mixed Dimension Embedding[11] 等,根据特征值的频次预先设计几个不同维度的可选项,基本原则就是高频高维度、低频低维度,这类方法过于依赖人工经验和粗暴的选择方式不容易获得最优解;基于NAS的方法,Automated Embedding[12]、NIS[13]、AutoDim[14] 等,依赖一个训练以外的精心设计的超参搜索(不同维度可选项)策略,迭代效率较低且不支持“继承训练”(有别于从头训练)实用性较弱。
针对已有解法存在的改进空间,我们提出一种新颖的端到端自适应的 Embedding Dimension 选择技术 ATML(Adaptively-Masked Twins-based Layer)。在原始Embedding上增加一个掩码转换层,该层引入先验的特征频次信息,借鉴条件计算的建模思想,利用松弛技术将离散维度选择问题转变为可微可导可直接 SGD 训练的高效模式,并且专门设计孪生门控网络有效缓解样本分布不均衡(二八定律)问题,使得模型具备高精度的 Dimension 选择能力;而且 ATML 技术对热启动需求友好,可直接应用在长时间训练到接近收敛状态的 Embedding(实际应用中从头训练Embedding 往往资源和时间成本非常高)。实践表明该技术不仅能够大幅压缩模型规模,在低频ID样本上还能进一步提升泛化性。
论文详解版请查阅另两篇推文
论文下载:
https://arxiv.org/pdf/2108.11513.pdf
▐ 总结与展望
预估模型的低碳瘦身之路具有普惠意义,即使是财力雄厚、工程基建完备的大场景业务算法团队在面临算力瓶颈对技术迭代锁死的窘境时也会做出这个退一步开阔天空的选择。回顾来看,Embedding 优化工作非常苦,主要原因是 Embedding 收敛效率很低,实验探究成本非常高,例如我们 CTR 模型 baseline 采用增量训练模式,导致 Embedding 改动往往需要几个月的训练样本才能支撑一个靠谱的实验结论。天下武功唯快不破,只有敏捷迭代才有稳健的算法输出,随着 Embedding 优化的不断深入,我们在算法和工程层面都沉淀出不少有效加速 Embedding 收敛的技术,期待后续有机会再和大家分享讨论。
参考文献
[1] Learning K-way D-dimensional Discrete Codes for Compact Embedding Representations
[2] Multi-Hot Compact Network Embedding
[3] Differentiable Product Quantization for End-to-End Embedding Compression
[4] Learning Multi-granular Quantized Embeddings for Large-Vocab Categorical Features in Recommender Systems
[5] Beyond User Embedding Matrix - Learning to Hash for Modeling Large-Scale Users in Recommendation
[6] Feature hashing for large scale multitask learning
[7] Hash Embeddings for Efficient Word Representations
[8] Model Size Reduction Using Frequency Based Double Hashing for Recommender Systems
[9] Compositional Embeddings Using Complementary Partitions for Memory-Efficient Recommendation Systems
[10] GroupReduce- Block-Wise Low-Rank Approximation for Neural Language Model Shrinking
[11] Mixed Dimension Embedding with Application to Memory-Efficient Recommendation Systems
[12] Automated Embedding Size Search in Deep Recommender Systems
[13] Neural Input Search for Large Scale Recommendation Models
[14] AutoDim- Field-aware Embedding Dimension Search in Recommender Systems
END

欢迎关注「阿里妈妈技术」,了解更多~

疯狂暗示↓↓↓↓↓↓↓















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









