









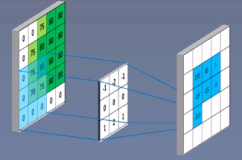
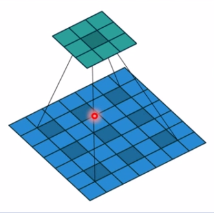
卷积运算:卷积核在输入信号(图像)上滑动,相应位置上进行乘加。
卷积核:又称为滤波器,过滤器,可认为是某种模式,某种特征
卷积过程类似于用一个模板去图像上寻找与它相似的区域,与卷积核模式越相似,激活值越高,从而实现特征提取。

AlexNet卷积核可视化,发现卷积核学习到是边缘、条纹、色彩这一些细节模式,这也印证了卷积核是某种特征提取器,而具体是哪一种特征、哪一种学习器完全是由模型决定的。

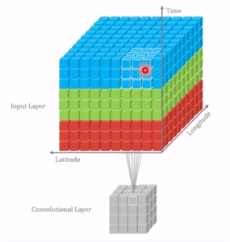
卷积维度:一般情况下,卷积核在几个维度上滑动,就是几维卷积。以下分别是一维卷积、二维卷积、三维卷积
nn.Conv2d(in_channels,out_channels,kernel_size,stride=1,padding=0,dilation=1,groups=1,bias=True,padding_mode="zeros")
功能:对多个二维信号进行二维卷积
主要参数:
- in_channels:输入通道数
- out_channels:输出通道数,等价于卷积核个数
- kernel_size:卷积核尺寸
- stride:步长
- padding:填充个数
- dilation:空洞卷积大小
- groups:分组卷积设置(分组卷积的组数)
- bias:偏置
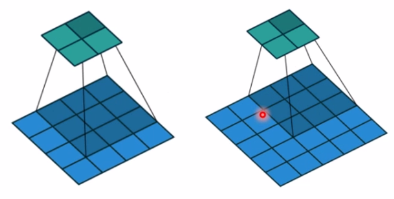
左边步长为1,右边步长为2
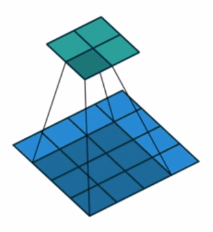
padding:右边图片加入了padding,保证输入、输出的尺寸不变

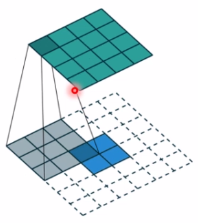
空洞卷积示意图,空洞卷积常用于图像分割任务,主要重要是为了提高感受野,即我们输出图像的一个像素可以看到前面图像更大的一个区域。
AlexNet卷积示意图

分组卷积就类似于如上AlexNet中将卷积分成两组,两组处理数据过程中是相互独立的,直到最后的FC层才组合起来。
图像经过卷积后是如何变化的?
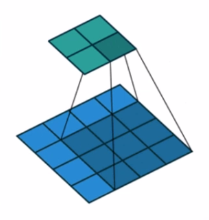
尺寸计算(简化版):![]()
如上:输入尺寸为4,kernel size为3,步长为1,则为(4-3)/1 +1 = 2
完整版:
![]()
为什么三维的张量实现的是二维的卷积,现通过如下示意图说明:

上面是一个RGB图像,三维的通道的二维图像,然后创建3个二维的卷积核,这3个二维的卷积核分别会对应每个通道进行卷积,三个通道的输出值进行相加,最后加上一个偏置,最后得到feature map的一个像素值。
从上可以看出一个卷积核只在一个二维度上卷积滑动,它只在两个维度上进行滑动,所以它只是二维的卷积。为什么它是3d的张量,这是因为输入有多个通道,它有多个二维的信号,多个二维图像,所以它才会有三维张量,三维的卷积核。因此,虽然它是三维卷积核,但是它却是执行的二维卷积。
转置卷积 Transpose Convolution
转置卷积又称为反卷积(Deconvolution)(不常用该名)和部分跨越卷积(Fractionally-strided Convolution),用于对图像进行上采样(UpSample),常用于图像分割任务中。
为什么称为转置卷积?
假设现有输入图像尺寸为4*4,卷积核为3*3,padding=0,stride=1
矩阵乘法实现正常卷积的操作:首先将图像拉成向量形式,即为16*1的二维矩阵,卷积核会变成4*16的矩阵
,其中4位输出特征的总个数,16位3*3增加0变成的,输出特征图为
,最后对输出特征图进行reshape即可得到2*2的特征图。
转置卷积操作:转置卷积实际上是一个上采样,即输入尺寸比较小,经过转置卷积后,会得到一个更大的图像。
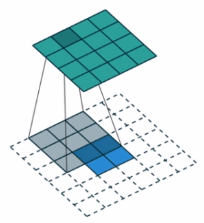

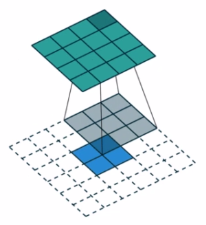
假设图像输入尺寸为2*2,卷积核尺寸为3*3,padding=0,stride=1
现将该图像拉成一个向量为,卷积核变为
,然后输出为
,最后reshape即可得到4*4的特征图。
我们可以发现正常卷积核为4*16,而转置卷积核为16*4,这两在形状上恰恰为转置关系(权值不同),所以称为转置卷积。又因为权值不同,所以转置卷积是不可逆的。
nn.ConvTranspose2d(in_channels,out_channels,kernel_size,stride=1,padding=0,output_padding=0,groups=1,bias=True,dilation=1,padding_mode="zeros")
- in_channels:输入通道数
- out_channels:输出通道数
- kernel_size:卷积核尺寸
- stride:步长
- padding:填充个数
- dilation:空洞卷积大小
- groups:分组卷积设置
- bias:偏置
转置卷积尺寸计算:
简化版:![]()
完整版:![]()
转置卷积后,会有棋盘效应,关于棋盘效应可查看文章《Deconvolution and Checkerboard Artifacts》
池化、线性、激活函数层
池化层 Pooling Layer
池化运算:对信号进行“收集”并“总结”,类似水池收集水资源,因而得名池化层。
“收集”:将信号由多变少,图像的尺寸由大变小的一个过程
“总结”方法:最大值、平均值
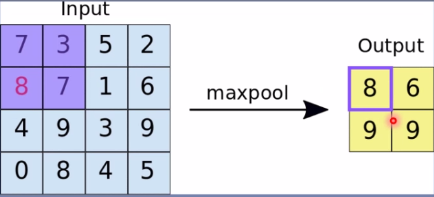
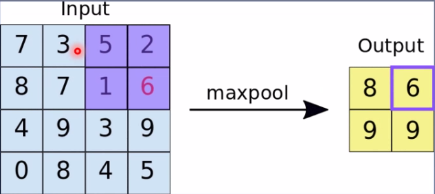

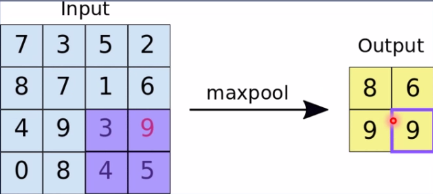
由上可看出,左边4*4的图像经过池化变为2*2的图像,其中用一个像素值去表示四个像素值,即为总结。

pytorch提供的池化方法
nn.MaxPool2d(kernel_size,stride=None,padding=0,dilation=1,return_indices=False,ceil_mode=False)
功能:对二维信号(图像)进行最大值池化
主要参数:
- kernel_size:池化核尺寸
- stride:步长
- padding:填充个数
- dilation:池化核间隔大小
- ceil_mode:尺寸向上取整
- return_indices:记录池化像素索引(位置),通常在最大值反池化时使用
最大值反池化,在最大值反池化时,将最大值放在具体什么位置呢?即可根据return_indices的索引进行放置。

池化操作可以进行冗余信息的剔除,以及减小后续的计算量。
nn.AvgPool2d(kernel_size,stride=None,padding=0,ceil_mode=False,count_include_pad=True,divisor_override=None)
功能:对二维信号(图像)进行平均池化
主要参数:
- kernel_size:池化核尺寸
- stride:步长
- padding:填充个数
- ceil_mode:尺寸向上取整
- count_include_pad:填充值用于计算
- divisor_override:除法因子
nn.MaxUnpool2d(kernel_size,stride=None,padding=0)
forward(self,input,indices,output_size=None)
功能:对二维信号(图像)进行最大值池化上采样
主要参数:
- kernel_size:池化核尺寸
- stride:步长
- padding:填充个数
线性层
线性层又称为全连接层,其每个神经元与上一层所有神经元相连实现对前一层的线性组合,线性变换

nn.Linear(in_features,out_features,bias=True)
功能:对一维信号(向量)进行线性组合
主要参数:
in_features:输入结点数
out_features:输出结点数
bias:是否需要偏置
计算公式:
激活函数层
激活函数对特征进行非线性变换,赋予多层神经网络具有深度的意义。若无激活函数层进行非线性变换,无论我们有多少层隐藏层,最后都等价于一层网络。

X
out
由于矩阵乘法的结合性,其中
,因此可看出一个三层的全连接层等价于于一层的线性层。
nn.Sigmoid
计算公式:
梯度公式:
特性:
- 输出值在(0,1),符合概率
- 导数范围是[0.0.25],易导致梯度消失
- 输出为非0均值,破坏数据分布

nn.tanh 双曲正切函数
计算公式:
梯度公式:
特性:
- 输出值在(-1,1),数据符合0均值
- 导数范围是(0,1),易导致梯度消失

nn.ReLU 修正线性单元
计算公式:
梯度公式:
特性:
- 输出值均为正数,负半轴导致死神经元
- 导数是1,缓解梯度消失,但易引发梯度爆炸

改善上诉缺点
nn.LeakReLU
- negative_slope:负半轴斜率
nn.PReLU
- init:可学习斜率
nn.RReLU
- lower:均匀分布下限
- upper:均匀分布上限
















 3220
3220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









