






一.栈
1.栈的概念与结构
栈是一种特殊的线性表,只允许在特定的一端进行插入和删除数据,这一端叫做栈顶,另一端叫做栈底。栈中的数据遵循后入先出的原则(LIFO原则(Last In First Out))。
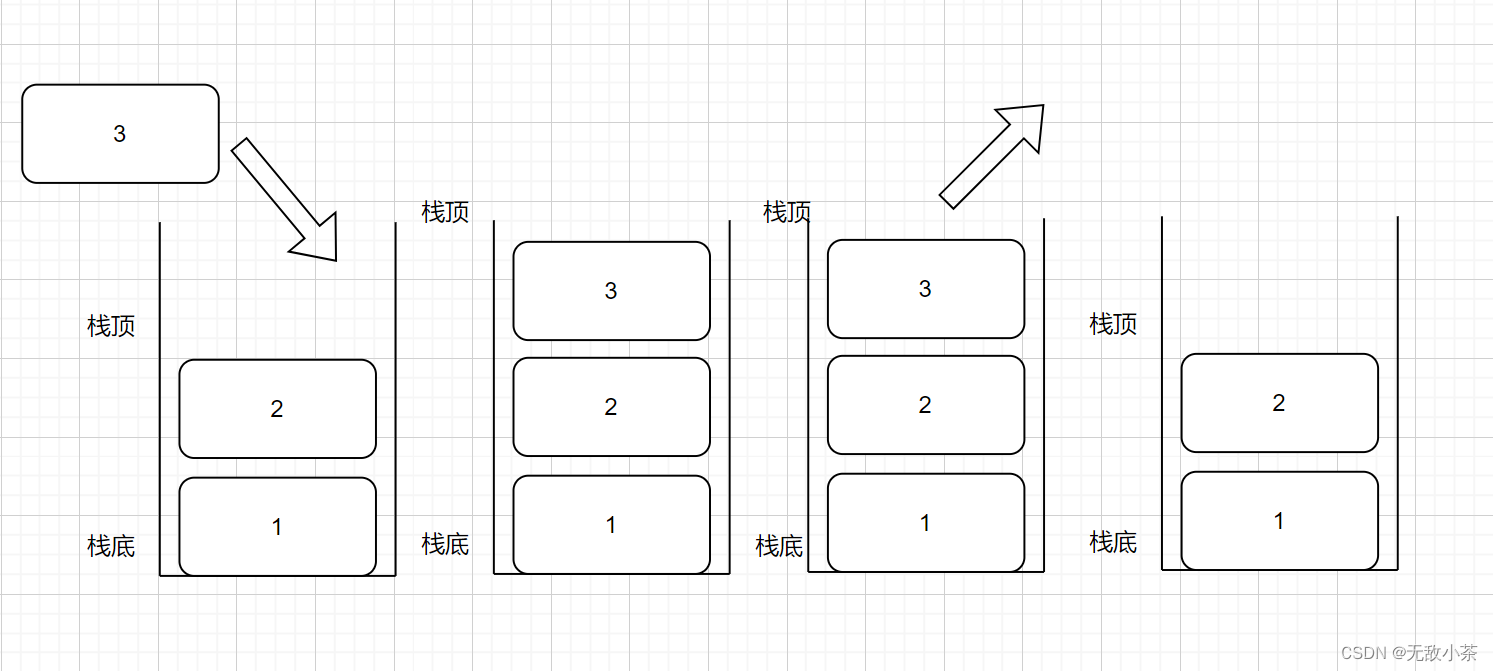
压栈:栈的插入操作 在栈顶完成操作
出栈:栈的删除操作 在栈顶完成操作
那么为了更方便同学们对栈这种数据结构有更深的理解,我们不妨画图演示一下压栈和出栈的过程:
2.栈的实现
那么在了解了栈的结构与概念后,我们不妨根据他的结构来思考一下,如何实现栈呢?根据以往所学的数据结构相关知识,我们可以想到用链表和数组来实现栈。那么谁更胜一筹呢?这个时候我们就会用到一个叫做缓存利用率的问题。那么接下来,我们先来补充相关知识。
关于顺序表和链表,他们之间很大的一个区别就是顺序表的缓存利用率高,而链表的缓存利用率低。我们来看下面这个关于存储器层次结构的图:
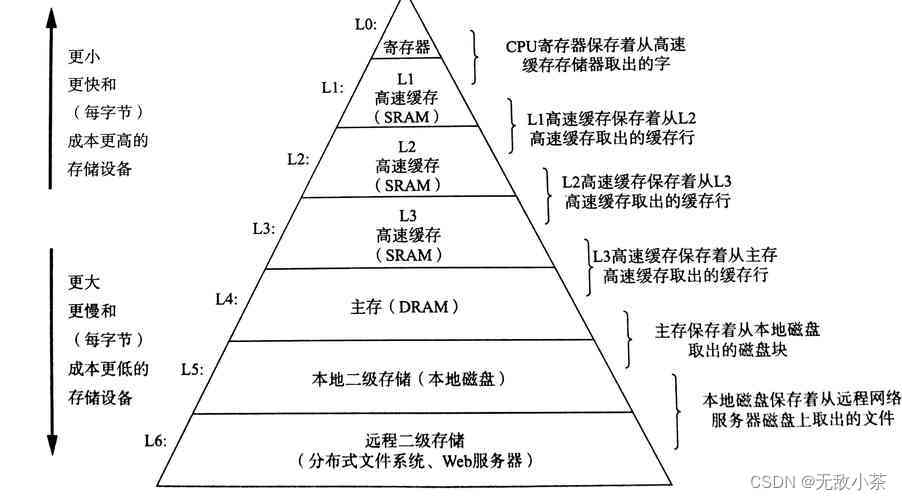
CPU进行访问时,先访问缓存,如果目标对象在缓存,则缓存命中,直接进行访问;如果不在,叫做不命中,此时要把一段连续内存空间的数据从内存加载到缓存,再进行访问。
我们注意,在使用顺序表时,因为顺序表在存储地址上是连续的(物理结构是线性的),避免了频繁加载,因此容易在把数据从内存加载到缓存后进行访问时缓存命中,提高了缓存命中率,我们称其缓存利用率高。
而链表存储地址不连续,缓存利用率低。
以上就是顺序表相较于链表的优势。因此在实现栈的时候,我们优先选择顺序表来完成栈的实现。
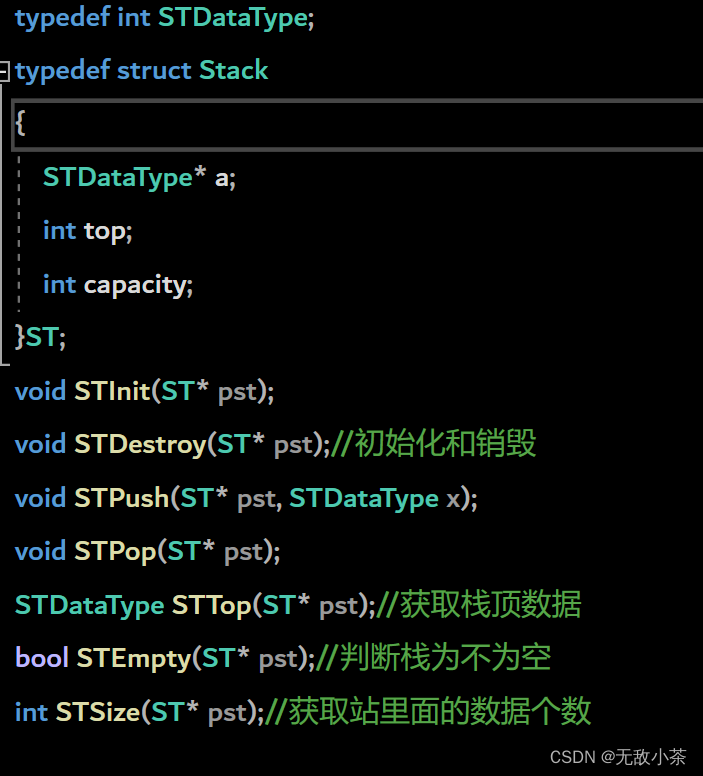
那么与顺序表的操作类似,实现栈大致包含以下几个模块:
栈的声明;(我们采用动态栈 )
栈的初始化;
压栈;
出栈;
获取栈顶元素;
判断是否为空栈;
获取栈中元素的个数;
栈的销毁;
我们还是采用模块化编程的思想,那么话不多说,我们直接上代码来一探究竟:
Stack.h文件:
Stack.c文件:
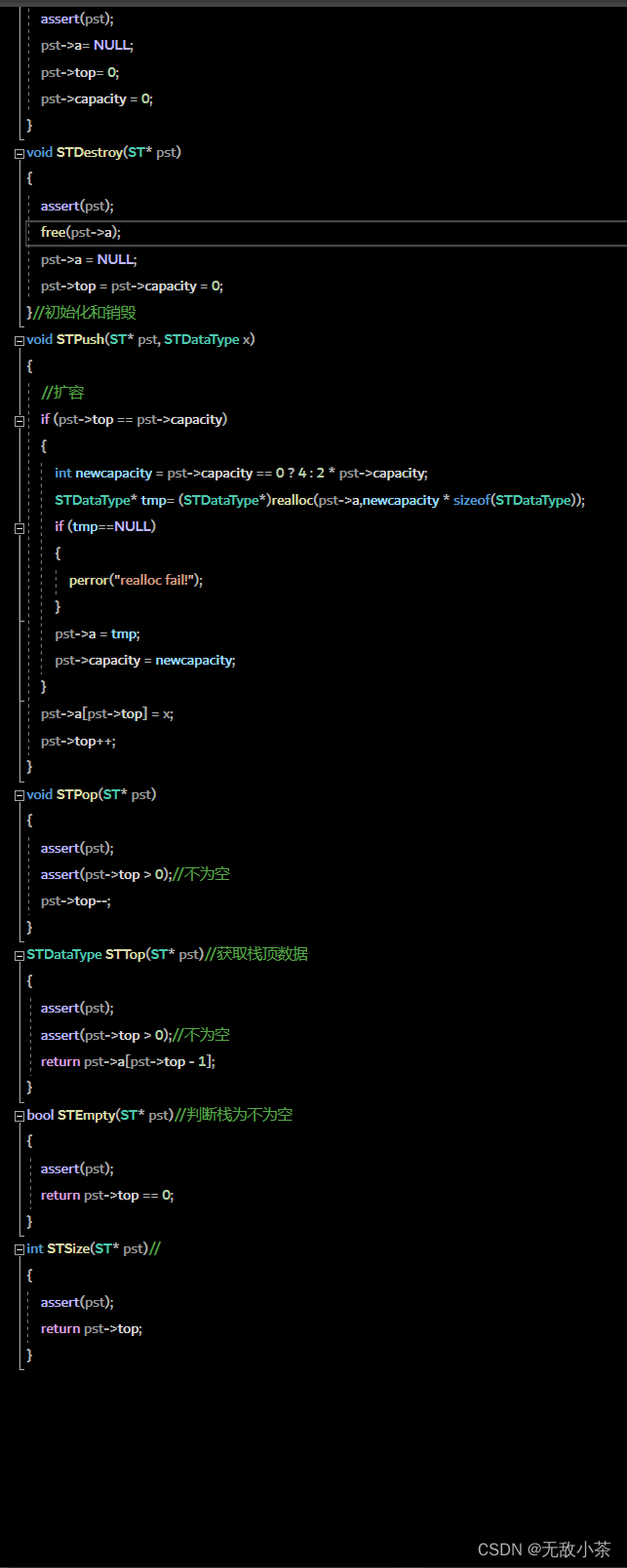
这里我们注意一下,在栈的声明中,我们定义了top=0,实际上,这样定义的话,我们是将top看做了栈顶的下一个元素,也代表元素的下标,也代表栈中元素的个数。
那么关于栈实现的函数我们就定义好了,那么接下来我们就可以运行检验一下了:
Test.c文件:
上面是茶老师给大家举的一个例子,大家可以根据自己的想法来实现栈。
那么今天关于栈的讲解就到这里,相信坚持学习到这里的你一定又收获满满了吧!非常感谢大家对编者的支持,关于本篇文章,如有任何问题,欢迎私信留言!下一期文章,我们将连载有关于队列的知识,提前透露一下,也是干货满满哦!我们下期再见!















 141
141











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









