






进程调度源码分析之CFS:
在文章开始之前想要说明一下,文中内容主要参考《奔跑吧Linux内核》入门篇及卷一部分,源码的注释部分参考了gitte上大神的源码注释(Zhe Qiao/linux 5.0注释)链接如下:https://gitee.com/residual_nozzle_on_dust/linux5-0-comments/tree/master
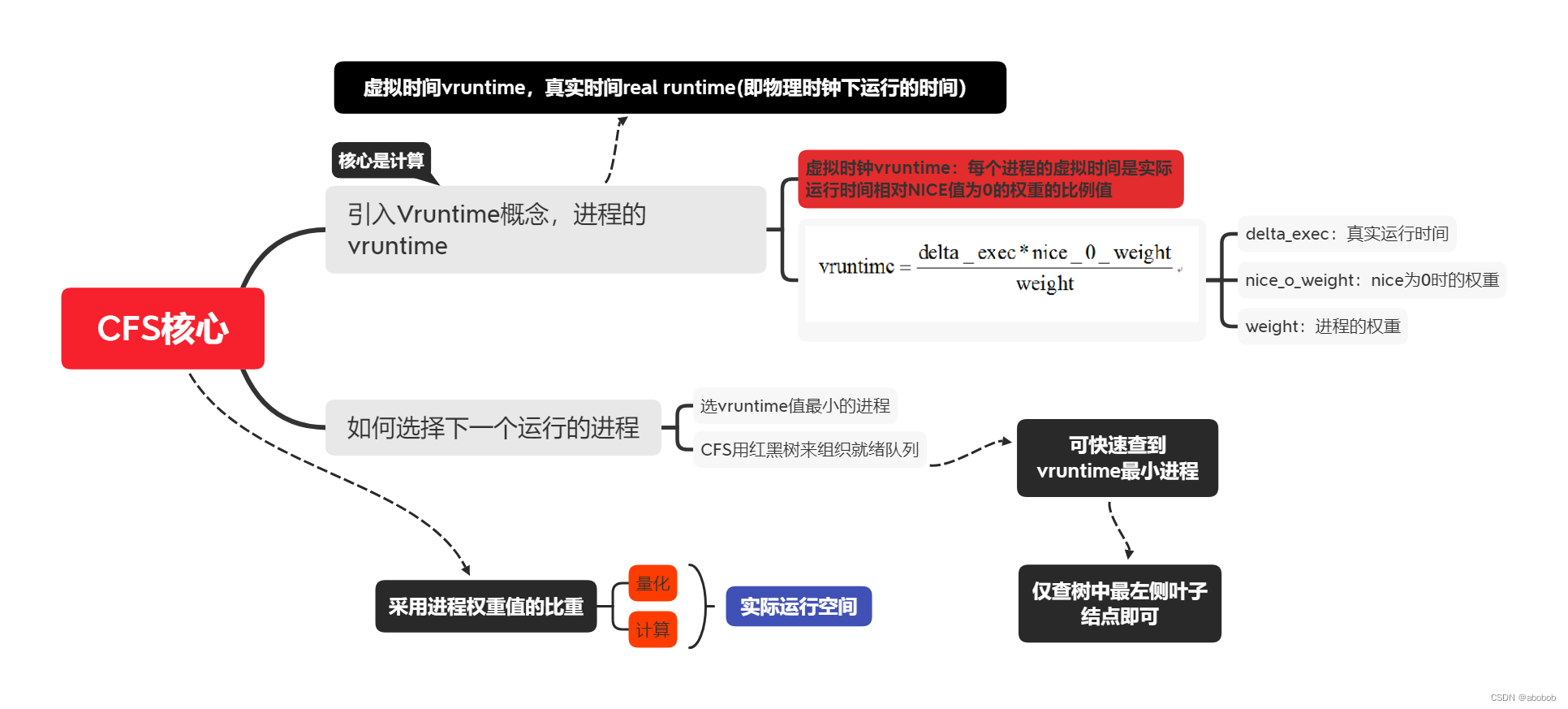
1.1、算法思想:
1.1.1、O(1)的缺陷:
O(1)调度器在处理 交互式进程时依然存在问题,交互式场景下导致交互式进程反应缓慢。故引入CFS完全公平算法。
1.1.2、CFS调度算法的思想:
CFS抛弃了以往的算法:
- 使用固定时间片;
- 固定调度周期;
采用了进程权重值的比重来计算实际运行时间;
理想状态下每个进程都能获得相同的时间片,并且同时运行在CPU上,但实际上一个CPU同一时刻运行的进程只能有一个。也就是说,当一个进程占用CPU时,其他进程就必须等待。CFS为了实现公平,必须惩罚当前正在运行的进程,以使那些正在等待的进程下次被调度。
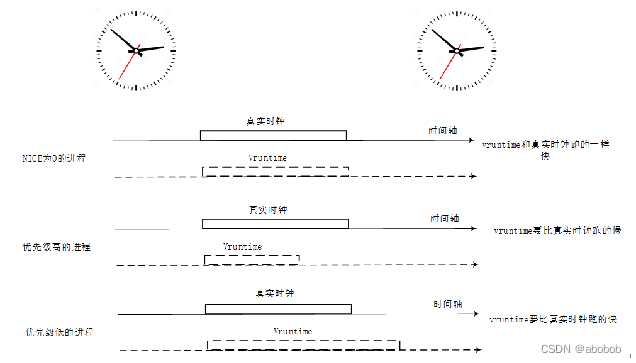
为了实现这种公平,便引入虚拟时间(vruntime)、真实时间(real runtime)的概念。
- 虚拟时间:实际运行时间相对NICE值为0的权重的比例值;
- 真实时间:物理时钟下运行的时间;
1.1.3:虚拟时间及选择下一个进程:
- 虚拟运行时间是通过进程的实际运行时间和进程的权重(weight)计算出来的。
- vruntime计算公式:
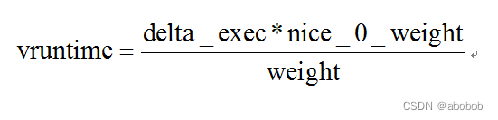
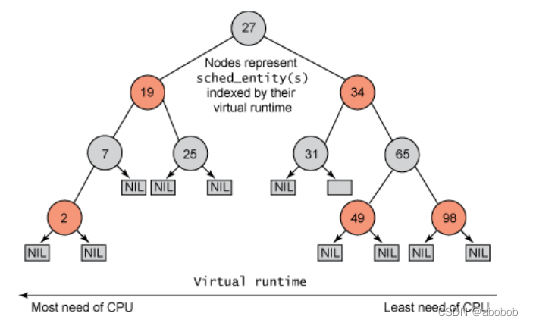
- CFS中的就绪队列是一棵以vruntime为键值的红黑树,虚拟时间越小的进程越靠近整个红黑树的最左端。因此,调度器每次选择位于红黑树最左端的那个进程,该进程的vruntime最小;
1.2、源码分析:
1.2.1、 load_weight():
负荷权重用struct load_weight数据结构来表示, 保存着进程权重值weight。定义在/include/linux/sched.h中,具体内容如下:
struct load_weight {
unsigned long weight;//weight是调度实体的权重;
u32 inv_weight;//inverse weight,权重的一个中间计算结果;
};
load_weight()函数内置在通用的调度实体sched_entity结构体中
struct sched_entity {
/* For load-balancing: */
struct load_weight load;//内置了load_weight结构用于保存当前调度实体的权重
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
struct sched_statistics statistics;
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth;
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
/* cached value of my_q->h_nr_running */
unsigned long runnable_weight;
#endif
#ifdef CONFIG_SMP
struct sched_avg avg;
#endif
};
1.2.2、涉及到的结构体:
- task_struct;
- sched_entity:调度实体,描述进程作为一个2调度实体参与调度所需的所有信息;
- rq:CPU通用的就绪队列,包括CPU就绪队列数据结构cfs_rq、实时进程调度器就绪队列rt_rq、实时调度器就绪队列dl_rq;
- cfs_rq:CPU就绪队列数据结构;
1.2.3、CFS调度算法的schedule()函数源码:
在2.6版本之后采用CFS算法,其schedule()函数在/kernel/sched/core.c目录下。schedule()函数主体是一个while循环,具体代码注释如下:
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;//指向当前进程的task_struct指针
sched_submit_work(tsk);
do {
preempt_disable();//关闭内核抢占
__schedule();//核心实现
sched_preempt_enable_no_resched();//打开内核抢占
} while (need_resched());
}
EXPORT_SYMBOL(schedule);

其中的核心实现被包含在内部函数__schedule()函数中,其作用是让调度器选择和切换到一个合适进程并运行。调度的时机可分为以下几种:
- 在阻塞操作中,如使用互斥量(mutex)、信号量(semaphore)、等待队列;
- 在中断返回前和系统调用返回用户空间时,检查TIF NEED RESCHED标志位以判断是否需要调度。
- 将要被唤醒的进程不会马上调用 shedule(), 而是==会被添加到 CFS 就绪队列,==设置了TIF NEED RESCHED 标志位。
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();//获取当前CPU
rq = cpu_rq(cpu);//由当前CPU获取数据结构rq
prev = rq->curr;//prev指向当前进程,当调度结束就指向前一个进程
schedule_debug(prev);//判断当前进程是否处于atomic(包含硬件中断上下文、软中断上下文等)上下文,若处于atomic,说明是一个bug
if (sched_feat(HRTICK))
hrtick_clear(rq);
local_irq_disable();//关闭本地cpu中断
rcu_note_context_switch(preempt);
/*
* Make sure that signal_pending_state()->signal_pending() below
* can't be reordered with __set_current_state(TASK_INTERRUPTIBLE)
* done by the caller to avoid the race with signal_wake_up().
*
* The membarrier system call requires a full memory barrier
* after coming from user-space, before storing to rq->curr.
*/
rq_lock(rq, &rf);//申请一个自旋锁
smp_mb__after_spinlock();
/* Promote REQ to ACT */
rq->clock_update_flags <<= 1;
update_rq_clock(rq);
switch_count = &prev->nivcsw;
if (!preempt && prev->state) {//preempt判断本次调度是否为抢占调度,prev_state判断当前进程运行状态,为0说明当前进程处于运行状态.判断是否是主动调度
if (signal_pending_state(prev->state, prev)) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);//把当前进程移出就绪队列
prev->on_rq = 0;
if (prev->in_iowait) {
atomic_inc(&rq->nr_iowait);
delayacct_blkio_start();
}
/*
* If a worker went to sleep, notify and ask workqueue
* whether it wants to wake up a task to maintain
* concurrency.
*/
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev);
if (to_wakeup)
try_to_wake_up_local(to_wakeup, &rf);
}
}
switch_count = &prev->nvcsw;
}
next = pick_next_task(rq, prev, &rf);//让调度器从就绪队列选一个最合适调度的进程next
clear_tsk_need_resched(prev);//清理当前进程的TIF_NEED_RESCHED标志位,表示接下来它不会被调度
clear_preempt_need_resched();
if (likely(prev != next)) {//如果当前进程不是选择的进程说明可以进行调度了
rq->nr_switches++;
rq->curr = next;
/*
* The membarrier system call requires each architecture
* to have a full memory barrier after updating
* rq->curr, before returning to user-space.
*
* Here are the schemes providing that barrier on the
* various architectures:
* - mm ? switch_mm() : mmdrop() for x86, s390, sparc, PowerPC.
* switch_mm() rely on membarrier_arch_switch_mm() on PowerPC.
* - finish_lock_switch() for weakly-ordered
* architectures where spin_unlock is a full barrier,
* - switch_to() for arm64 (weakly-ordered, spin_unlock
* is a RELEASE barrier),
*/
++*switch_count;
trace_sched_switch(preempt, prev, next);
/* Also unlocks the rq: */
rq = context_switch(rq, prev, next, &rf);//调用此函数切换到next进程
} else {
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
rq_unlock_irq(rq, &rf);
}
balance_callback(rq);
}
__schedule()函数的参数是 preempt,它是bool类型变量,用于表示本次调度是否为抢占。__schedule()函数调用 pick next task()让调度器从就绪队列中选择一个最合适的进程next,调用 context switch()函数切换到 next进程。
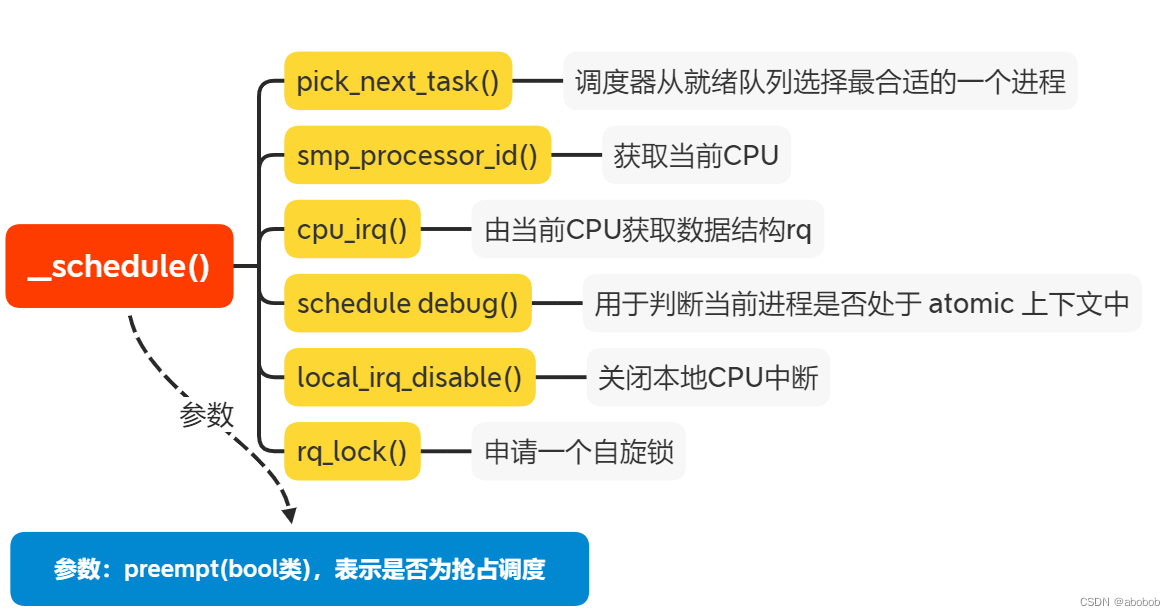
这里面通过next = pick_next_task(rq, prev, &rf);语句让调度器从就绪队列选一个最合适调度的进程;我们看一下pick_next_task()函数
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
/*
* Optimization: we know that if all tasks are in the fair class we can
* call that function directly, but only if the @prev task wasn't of a
* higher scheduling class, because otherwise those loose the
* opportunity to pull in more work from other CPUs.
*/
if (likely((prev->sched_class == &idle_sched_class ||
prev->sched_class == &fair_sched_class) &&//如果当前进程prev调度类是cfs调度类
rq->nr_running == rq->cfs.h_nr_running)) {//并且该CPU就绪队列进程数等于cfs就绪队列进程数,说明该cpu就绪队列只有普通进程,否则需要遍历整个调度类
p = fair_sched_class.pick_next_task(rq, prev, rf);//普通调度类选进程
if (unlikely(p == RETRY_TASK))
goto again;
/* Assumes fair_sched_class->next == idle_sched_class */
if (unlikely(!p))
p = idle_sched_class.pick_next_task(rq, prev, rf);//idle调度类选进程
return p;
}
again:
for_each_class(class) {//遍历整个调度类,按优先级从高到低
p = class->pick_next_task(rq, prev, rf);//选择合适进程
if (p) {
if (unlikely(p == RETRY_TASK))
goto again;
return p;
}
}
/* The idle class should always have a runnable task: */
BUG();
}
限于篇幅以及时间,关于CFS的介绍只能写这么多。本章节先是简单的介绍了一下CFS调度并给出了我对CFS核心理解的思维导图,再是关于其源码的部分摘录和分析,由于要实现CFS涉及到很多函数和结构体以及大量的思想方法,所以本章节只贴出了三个主要部分(schedule()函数、__schedule()、pick_next_task())。CFS中所涉及的东西太多太多,我们达不到绝对意义上的公平,但可以通过各种方法来接近完全公平,像极了我们不断向理想靠近的过程。















 1222
1222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









