







前言
本篇博客主要讲一些数据库集群的设计方面,应对于各种不同的环境所作出的措施
一、脑裂
1. 脑裂定义
脑裂 (split-brain) 是一种故障状态,通常出现在分布式系统或集群环境中。在这种状态下,集群中的多个节点失去了彼此之间的通信连接,但它们仍然可以独立地访问和操作共享资源(如数据库或文件系统)。由于缺乏协调,这些节点可能会执行冲突的操作,从而导致数据不一致、数据丢失或其他严重问题。
2. 如何防止
脑裂的情况一般都是因为心跳断开导致,然后各个节点各自对共享的数据进行操作导致,由图 :
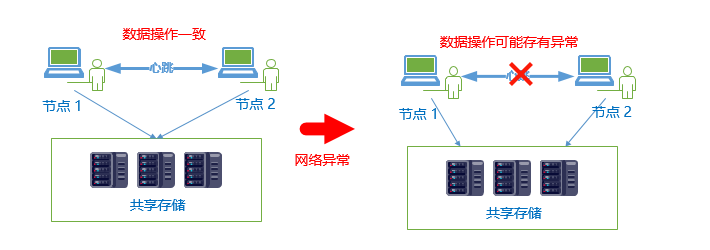
根据脑裂的触发条件,可通过以下方式进行防止 :
- 增加冗余的心跳线,尽量减少脑裂发生机会;
- 启动磁盘锁,发生脑裂的时候协调对资源的控制;
- 设置仲裁机制;
3.数据库防止脑裂
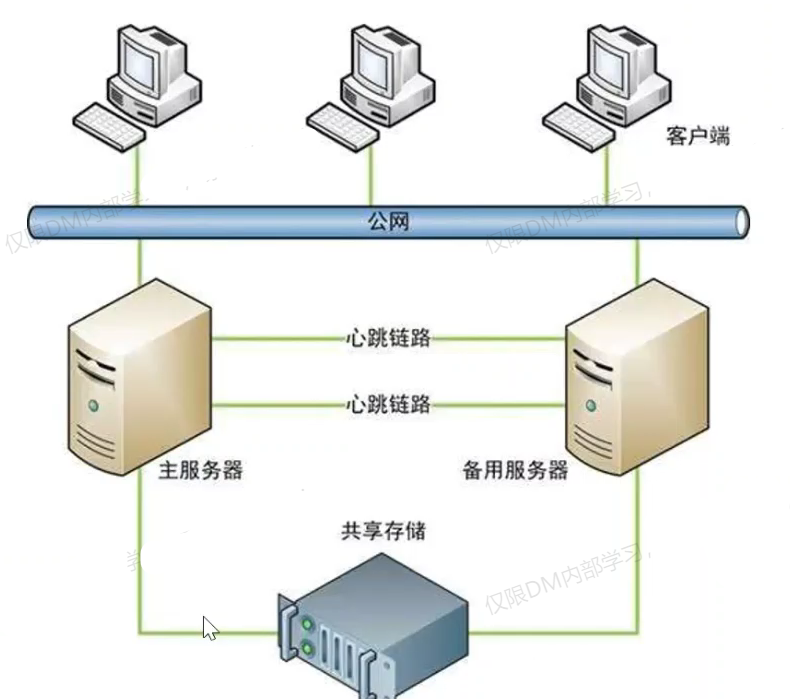
3.1 HA 双机热备防脑裂
HA 服务脑裂主要是主备机会同时向共享存储写入数据,造成严重的数据错乱,DM预防手段如下:
- 建议增加冗余的心跳线;
- 加入互斥机制,dm.ini 中记录主备机器 IP,不允许同时启动数据库实例
3.2 主备集群防脑裂
可能存在脑裂场景:
- 主备服务器心跳出现异常,配置集群为自动切换,且没有监控器
- 人工干预时未确认原主机的活动状态;
应对方式:
- 做对应的网络冗余,使用 AB 模式的 HA 网络;
- 一般建议采用非自动切换模式;
- 自动切换模式,需要部署对应的监控器,一般为单数;
- 人工干预之前必须确认原主机是否处于活动状态,dm.ini 里面设置 ALTER_MODE_STATUS = 0,不允许人工修改数据库模式、状态以及OGUID
3.3 DSC集群防脑裂
-
双节点 :
当内网网卡故障时,系统会执行故障处理,保留节点号小的节点(DM2),节点号大的节点会自杀并踢出集群(DM1),当网络回复时,该服务仍然处于停止状态(DM1),需要人工进行恢复; -
三节点 :
当内网网卡故障时,系统会执行故障处理,DM1 通过网络心跳连接不到其他服务器的时候,会自杀并被踢出集群,当网络回复时,该服务仍然处于停止状态(DM1),需要人工进行恢复;
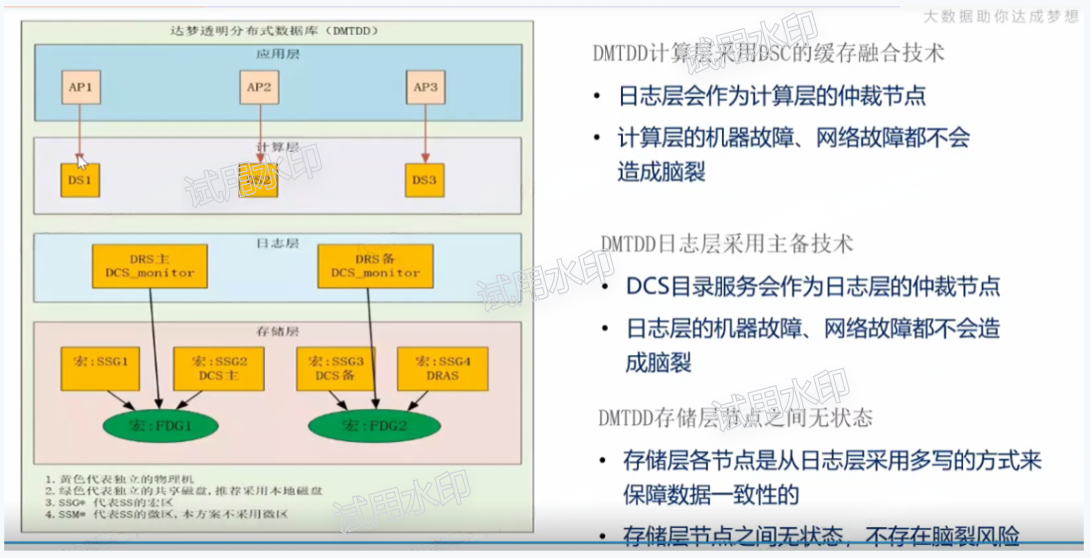
3.4 TDD集群防脑裂















 1517
1517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









