







排序算法
二分查找
歪个楼,二分不是排序算法,但是需要在有序数据的情况下使用。
最主要记一下有left,right和mid三个位置用来缩小边界。
核心代码:
假设在升序数组nums中寻找target,有就返回true,没有就返回false
//终止条件,注意定义的是左闭右闭还是左闭右开
//左闭右闭:left和right都是数组中能取到值的下标,终止条件left>right
//左闭右开:left是能取值的下标,但是right不是,终止条件left>=right
while(left<=right){
//就是(left+right)/2,以下写法是为了避免数据量过大导致溢出
int mid = left+(right-left)/2;
if(nums[mid]>target){
right = mid -1;
}else if(nums[mid]<target){
left = mid +1;
}else{
return true;
}
}
return false;
面试真题:
第一种:给有序数组和目标值的题目好做,反正长度不长模拟一下就可以了。
第二种:最多比较多少次?二分查找的复杂度是O(logn),套公式做。
假设数组有n个元素,设比较的次数为count,count = log n(以2为底)
如果count是整数那就是要比较的最多次数,如果是小数就只取整数部分再加1。
在有128个元素的数组中二分查找一个数,需要比较的次数最多不超过?
count = log 128 = 7,最多比较7次一定能查到某个数。
冒泡排序
以升序为例,从前往后每轮依次将此时最大的元素放到最后,每轮确定一个元素称为一轮冒泡,重复该行为知道数组有序。
核心代码:
//每轮确定最小的数放在前面
for(int i = 0;i<nums.length;i++){
//j=i+1就是在减少比较次数
for(int j = i+1;j<nums.length;j++){
if(nums[j]<nums[i]){
int tep = nums[i];
nums[i] = nums[j];
nums[j] = tep;
}
}
}
如果数组本来就有序,用以上代码会做很多次无意义的操作,因此可以用一个布尔变量记录数组原来是否有序——无序在判断时一定会有元素要发生位置上的变动,有序不会有元素要改变位置。
//可以优化冒泡次数:
for(int i = 0;i<nums.length;i++){
// 用一个布尔类型记载是否有元素发生改变,如果本来是有序的,有序则不会发生改变,就只要一轮冒泡即可。
boolean changed = false;
for(int j = i+1;j<nums.length;j++){
if(nums[j]<nums[i]){
int tep = nums[i];
nums[i] = nums[j];
nums[j] = tep;
changed = true;
}
}
if(!changed)
break;
}
我比较习惯每次把最小的放前面,以下写一下每轮把最大的放后面的思路:
优化比较次数:
其实还可以每次把最大的元素放在最后,每轮确定最大的元素位置,同时记载当前轮次冒泡中最后一次发生交换的位置 last,此时last后面都是已经有序的元素。所以下轮冒泡中可以从0开始,到 last 结束。
优化冒泡次数:
当 last =0时,证明当前轮冒泡没有发生交换,证明数组已经有序。
放一个把大的放后面的gif:
选择排序
将数组分为已排序部分和未排序部分,每次选择最小的数放在数组前面(也就是已排序部分),重复以上操作直到数组遍历结束。
选择核心代码:
int[] a = {5,3,7,2,1,9,8,4};
//选择排序
//i 代表有序部分的结尾下标
for(int i = 0 ;i< a.length ;i++){
int smallestIndex = i;
//smallestIndex 选取无序部分当前轮次最小的元素,j用于遍历无序部分
for(int j = smallestIndex+1;j<a.length; j++){
if(a[j] < a[smallestIndex]){
smallestIndex = j;
}
}
//交换该轮有序部分的最后一个元素和无序部分获得的最小值
//如果smallestIndex和进循环之前初始化的不一样,证明有比当前位置更小的元素,需要进行交换
if(smallestIndex != i){
int tep = a[i];
a[i] = a[smallestIndex];
a[smallestIndex] = tep;
}
}
过程:
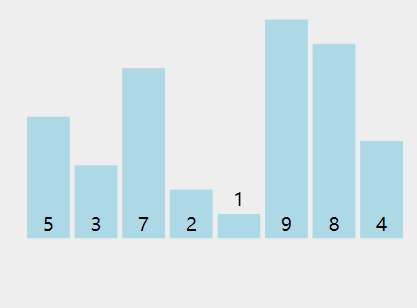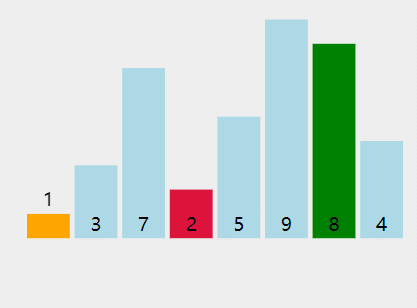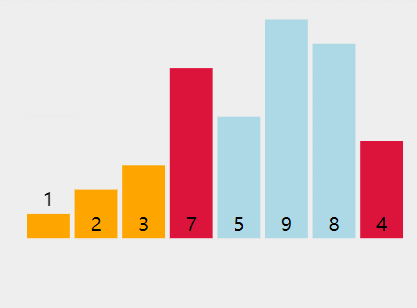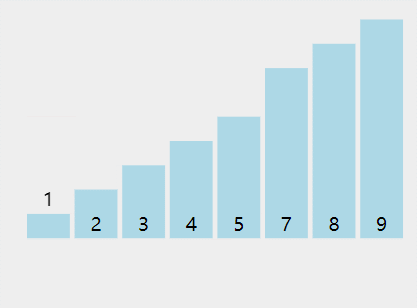
结果:

看选择的概念和冒泡好像哦,它主要的区别:元素交换在内循环还是外循环里。
冒泡核心代码里每轮冒泡里元素都是两两交换,如果后面的元素比前面的元素大就会发生交换。
选择排序是每轮排序里选择未排序部分的最小的元素放进已排序部分,元素交换在一轮里只会进行一次或者零次。
二者进行比较如下:
主要是三点:时间复杂度,算法稳定性,更适合的使用场景。
1.时间复杂度都是O(n^2)
2.一般情况下选择排序快于冒泡排序,因为交换的次数更少。
3.选择排序是不稳定排序,元素的相对位置顺序可能更改;冒泡排序是稳定排序,元素的相对位置没有改变。
4.如果集合本来就很有序了,由于冒泡中有是否发生改变的判断能够在元素已经有序时及时退出,而选择排序一定会选择那么多轮次,所以此时使用冒泡排序会更好。
插入排序
同样是分作有序部分和无序部分,每次从无序部分取一个元素,在有序部分的正确位置插入,重复以上操作直到数组有序。
核心代码:
int[] a = {9,3,7,2,5,8,1,4};
//插入排序
for(int i = 1;i<a.length;i++){
int num = a[i]; //记载要插入的值
//用于在有序部分中从后向前遍历找插入位置
int j = i-1;
for(;j>=0;j--){
//如果a[j]比要插入的值要大,当前元素后移——是移动元素而不是交换元素
if(a[j]>num){
a[j+1] = a[j];
}else break; //否则就是插入位置
}
a[j+1] = num; //插入有序部分
}
过程:前面之前遮住了所以重新开始了一下。
结果:

分有序部分和无序部分,选择排序和插入排序有点像,二者的区别在于:
选择排序还是交换元素,而插入排序是元素后移(移动)后再插入。
选择排序选的是无序部分最小 的元素进行交换,插入排序是选择无序部分的第一个元素去插入有序部分。
二者比较:
1.时间复杂度:都是O(n^2)
2.插入排序中如果有序部分的元素值比要插入的元素要小时会直接break,所以和冒泡一样,在数组基本有序的时候,冒泡排序和插入排序都优于选择排序。
3.插入排序是稳定排序算法,选择排序是非稳定算法。
希尔排序:插入排序的改进算法
插入排序中,如果大元素在前面会导致要移动多轮才能到自己该在的位置,为了改正这个缺点,有了希尔排序。
主要要记一下希尔排序通过间隙分组进行插入排序,而且这间隙会越来越小。
不知道间隙咋选可以去找一下,比如间隙队列:N/2,N/4,…1
举个例子:太长了所以只录了两轮:
掌握思路即可,这些排序算法的动画都可以去网站看:
可视化排序算法 Visualgo.net
有希尔排序的 Data Structure Visualizations
快速排序
每轮排序选择一个基准pivot进行分区,比基准小的元素放在一个分区,比基准大的元素放在另一个分区,最后基准点位置和维护比基准点小的边界位置的 i 元素进行互换,这轮排序后基准点元素就是最终的位置。
1.单边循环快排
每次选择最右元素作为pivot,先定交换后的pivot位置,然后用递归往左右分区继续重复操作。
核心代码:
public static void quick(int[] a,int left,int right){
if(right<=left) //边界,分区只有一个元素就终止递归
return;
int p = partition(a,left,right); //获取交换后的pivot位置
quick(a,left,p-1); //左分区
quick(a,p+1,right); //右分区
}
public static int partition(int[] a,int left,int right){
int pivot = a[right]; //取最右边的元素作为基准点
int i = left; //用i表示分区中比pivot小的元素的边界,也是最后要和pivot交换的元素位置
for(int j = left;j<right;j++){
if(a[j]<pivot){ //元素比基准点元素小,要把它放到左边
int tep = a[j];
a[j] = a[i];
a[i] = tep;
i++; //分区位置i递增
}
}
//最后i和pivot元素互换
//可以加i!=right进行优化
int tep = a[i];
a[i] = pivot;
a[right] = tep;
System.out.println(Arrays.toString(a));
return i; //返回更新的pivot
}
2.双边循环快排
每次选择最左元素作为基准点,有 i,j 两个指针,j 从右往左找比基准点小的元素,i 从左往右找比基准点大的元素,然后 i , j 互换,重复这个过程直到 i , j 相交,最后pivot和 j 交换位置即可。
核心代码:
public static void quick(int[] a ,int left ,int right){
if(left>=right)
return;
int p = partiotion(a,left,right);
quick(a,left,p-1);
quick(a,p+1,right);
}
public static int partiotion(int[] a ,int left, int right){
int pivot = a[left];
int i = left,j = right;
while(i<j){
//j从右往左找小的
while(i<j && a[j]>pivot)
j--;
//i从左往右找大的
//<= :避免基准点最开始就被换走了,还有后面出现和基准点相等的元素i就不动了
while (i<j && a[i]<=pivot)
i++;
//找到了就交换
int tep = a[i];
a[i] = a[j];
a[j] = tep;
}
//交换i和pivot的元素
int tep = a[j];
a[j] = pivot;
a[left] = tep;
return j;
}
注意这里最后的元素交换最好是换 j 。
//先j后i
//j从右往左找小的
while(i<j && a[j]>pivot)
j--;
//i从左往右找大的
while (i<j && a[i]<=pivot)
i++;
还有i , j 的先后顺序会决定最后i,j相交的时候会停在分区的那个位置,先i再j会停在右分区的第一个元素,先j再i会停在左分区的最后一个元素。很明显pivot是要和左分区的最后一个元素交换的,所以出了while循环之后,如果是先i后j的交换和返回pivot位置是j-1,先j再i的交换和返回pivot位置就是j。
每个i和j的操作里都有i<j的判断条件:避免交换元素的时候选取了已经交换好的元素,以 i 从左向右找时为例,假设 i 后面 j 前面 没有比pivot大的元素,i本来不该再动了,那么如果没有 i<j 的话, i会一直向后直到取到j后面比pivot大的元素,那么整个逻辑就乱套了。
总结双边循环快排的细节:
1.i<j
2. 基准点选最左边
3. 先 j 再 i
4. a[i] <= pivot
特点:
1.时间复杂度:O(nlogn),最坏时间复杂度:O(n^2)——比如都是重复元素的情况下。
2.属于不稳定排序
掌握要求:
冒泡排序和选择排序代码要能手写。快排的代码能手写。
其他排序算法要能阐述实现思路,也有可能给数组让推导第几趟排序后的结果。
推导的时候注意有一些能够直接推:
1.用选择排序,每次都是选无序部分最小的元素放在前面(以从小到大为例)。
2.用插入排序,每次都是选无序部分第一个元素插入进有序部分。















 368
368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









