






一、什么是Elastic Search
Elastic Search 是一个基于 Lucene 库的开源分布式搜索和分析引擎。它提供了一个分布式、多租户的全文搜索引擎,具有 RESTful API,能够以接近实时的速度存储、搜索和分析大量的数据。
二、倒排索引和正向索引
2.1.1:正向索引
在说倒排索引前我们先来看看什么是正向索引?例如给下表(tb_goods)中的id创建索引:
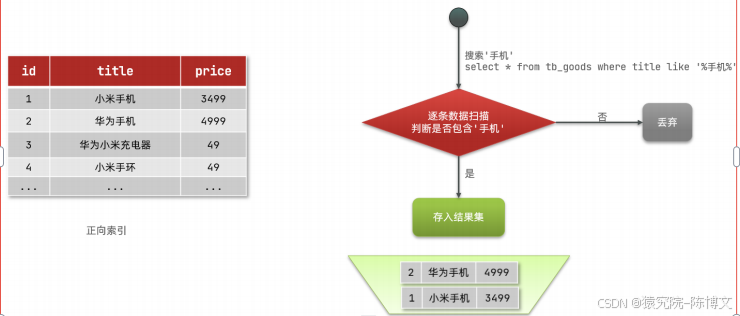
- 用户搜索数据,条件是title符合"%手机%"
- 逐行获取数据,比如id为1的数据
-
判断数据中的 title 是否符合用户搜索条件
-
如果符合则放入结果集,不符合则丢弃。重复上述操作
2.1.2:倒排索引
1.定义:
倒排索引(Inverted Index)是一种索引数据结构,它是搜索引擎中最常用的数据结构之一。与传统的正向索引不同,倒排索引是从单词(或术语)到文档的映射。在正向索引中,是文档指向它所包含的单词;而在倒排索引中,是单词指向包含它的文档列表。
①:倒排索引中的一些概念
- 文档( Document ):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息
-
词条( Term ):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
-
将每一个文档的数据利用算法分词,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建索引,例如hash表结构索引

③:倒排索引的搜索流程:
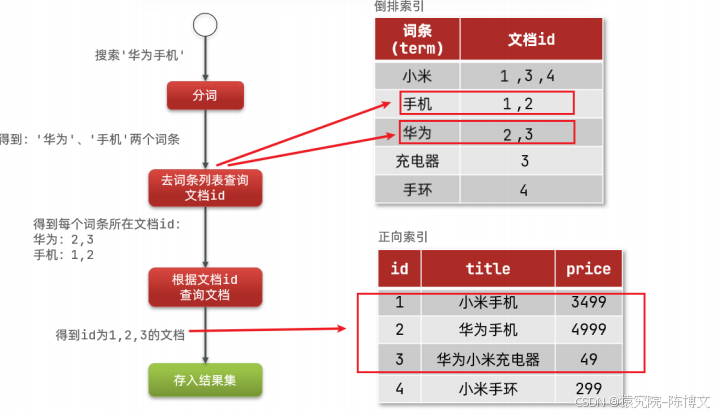
- 用户输入条件"华为手机"进行搜索。
- 对用户输入内容分词,得到词条:华为、手机。
- 拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
- 拿着文档id到正向索引中查找具体文档。
- 优点:
- 直观性:正向索引的结构比较直观,它以文档为中心进行构建。对于每个文档,记录该文档包含的词汇信息。例如,在一个简单的文档管理系统中,有文档 A、B、C,文档 A 包含词汇 “苹果”“红色”,文档 B 包含词汇 “香蕉”“黄色”,文档 C 包含词汇 “橙子”“橙色”。这种从文档到词汇的映射方式很容易理解,就像一个文档清单,每个文档后面跟着它所涉及的内容。
- 适合文档内容存储和展示:在需要展示文档内容细节的场景中非常有用。比如在一些电子书阅读平台,当用户打开一本书(一个文档)时,可以方便地获取这本书的文本内容、章节信息等,这些信息可以基于正向索引来存储和提取。因为正向索引主要关注文档本身,所以可以很好地支持对文档内部信息的维护和展示。
- 易于更新文档内容:当需要对某个文档的内容进行更新时,比如添加新的词汇或者修改文档中的某个词汇,在正向索引中操作相对简单。还是以文档管理系统为例,如果要在文档 A 中添加一个新的词汇 “甜味”,只需要在文档 A 对应的索引记录中添加这个词汇即可。
2.缺点:
1.搜索效率低:在进行关键词搜索时效率较低。如果要查找包含某个特定词汇(如 “红色”)的所有文档,使用正向索引就需要遍历所有的文档,检查每个文档中的词汇列表是否包含目标词汇。在数据量较大的情况下,这种全文档遍历的方式会消耗大量的时间和计算资源。例如,在一个包含数百万文档的大型知识库中,使用正向索引来搜索一个常见词汇可能会导致非常长的响应时间。
2.不适合复杂搜索操作:对于复杂的搜索操作,如布尔搜索(例如查找同时包含 “红色” 和 “苹果” 的文档)或者短语搜索(如查找包含 “红色苹果” 这个短语的文档),正向索引很难有效地支持。因为它没有提供词汇之间关联以及词汇在文档中位置关系的有效信息,要实现这些复杂搜索,可能需要对每个文档进行深度的文本分析,这会使搜索过程变得非常复杂和缓慢。
2.2.1:倒排索引的优缺点:
优点:
- 高效的搜索性能
- 倒排索引最大的优势在于其搜索效率。当用户进行关键词搜索时,系统可以直接通过倒排索引快速定位包含该关键词的文档。例如,在一个包含海量新闻文章的数据库中,用户想要查找包含 “人工智能” 这个关键词的文章。倒排索引可以直接找到对应的文档列表,而无需遍历所有文章的内容。这是因为倒排索引是从词汇到文档的映射,使得搜索过程能够快速聚焦在相关文档上,大大减少了搜索时间。
- 对于复杂的搜索操作,如布尔搜索(例如查找包含 “人工智能” 且不包含 “区块链” 的文章)和短语搜索(如查找包含 “人工智能算法” 这个短语的文章)也能高效处理。在布尔搜索中,通过对不同词汇的倒排表进行逻辑运算(如交集、差集等)来快速得到结果;在短语搜索中,可以利用词汇在文档中的位置信息来确定短语是否存在,从而快速筛选出符合要求的文档。
- 支持模糊搜索和相关度排序
- 倒排索引便于进行模糊搜索。例如,在一个产品搜索引擎中,用户可能会输入拼写错误的关键词,如 “camerra”(正确为 “camera”)。倒排索引可以通过一些模糊匹配算法(如编辑距离算法)来找到可能匹配的词汇及其对应的文档。
- 同时,还可以基于词汇在文档中的出现频率、位置等信息来对搜索结果进行相关度排序。比如,在一个学术文献数据库中,若用户搜索 “量子力学”,那些多次提及该词汇并且词汇出现在标题、摘要等重要位置的文献可以排在更前面,从而为用户提供更有价值的搜索结果。
缺点:
- 索引构建和维护成本高
- 构建倒排索引需要对原始文本进行复杂的预处理,包括分词(将文本分割成单词或术语)、去除停用词(如 “的”“是”“在” 等对语义表达不重要的词)、词干提取(将单词转换为其基本形式,如 “running” 转换为 “run”)等操作。这些预处理步骤会消耗大量的计算资源和时间。例如,在构建一个大型图书馆藏书的倒排索引时,对每一本书的内容进行分词和其他预处理操作可能需要很长的时间。
- 并且,当文档内容发生更新(如修改、删除文档)时,需要及时更新倒排索引。如果文档更新频繁,维护倒排索引的成本会很高。比如,在一个实时新闻网站中,新闻内容不断更新,这就需要频繁地更新倒排索引,以确保搜索结果的准确性。
- 占用存储空间大
- 倒排索引通常需要存储大量的信息,包括词汇表中的所有词汇、每个词汇对应的倒排表(包含文档编号、词汇在文档中的位置和频率等信息)。随着文档数量和词汇量的增加,倒排索引占用的存储空间会迅速增长。例如,在一个处理海量网页的搜索引擎中,为了存储网页内容对应的倒排索引,需要大量的磁盘空间来保存词汇表和倒排表的信息。
三、为什么要创建倒排索引库
倒排索引之所以被创建,是因为它在全文检索中提供了极高的效率。
传统的正向索引(正排索引)是按照文档来组织词汇的,这意味着要查找一个词汇在哪些文档中出现,需要逐个检查每个文档。
而倒排索引则是按照词汇来组织文档的,它将每个词汇映射到包含该词汇的所有文档的列表,这样可以直接通过词汇快速找到相关文档,大大减少了搜索时间。
四、倒排索引的查询过程
过程:
当用户发起搜索请求时,Elasticsearch会根据查询条件在倒排索引中查找匹配的文档。以关键词查询为例,查询过程如下:
解析查询:将用户输入的查询字符串解析为关键词列表。
查找词典:在倒排索引的词典中查找每个关键词,获取对应的倒排列表。
合并结果:根据倒排列表合并结果,生成匹配文档的列表。
计算评分:对匹配的文档进行相关性评分,排序后返回给用户。

















 3045
3045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









