







赛博·新闻
1、DeepSeek开源五连发
DeepSeek在本周(2025年2月24日~2月28日)连续五天发布了多个核心技术开源项目,覆盖大模型训练、推理优化、通信库及分布式文件系统等领域。
1.2月24日:FlashMLA
- 功能:针对英伟达Hopper架构GPU优化的高效MLA(多头潜在注意力)解码内核,专为处理可变长度序列设计,提升大模型推理效率。
- 性能:在H800 GPU上,内存带宽可达3000GB/s,计算性能达580TFLOPS;采用KV压缩、动态序列处理等技术,减少内存占用。
2.2月25日:DeepEP通信库
- 功能:首个用于MoE(混合专家)模型训练和推理的开源专家并行(EP)通信库,支持高吞吐、低延迟通信。
- 特性:优化全对全(All-to-All)通信,支持FP8低精度计算,通过计算-通信重叠降低延迟,适用于大规模集群训练。
3.2月26日:DeepGEMM
- 功能:高效FP8通用矩阵乘法(GEMM)库,支持密集模型和MoE架构的矩阵运算。
- 性能:在英伟达Hopper GPU上实现1350+TFLOPS的FP8性能,核心代码仅约300行,但性能超越专家调优的内核。
4.2月27日:并行优化策略
- DualPipe:双向流水线并行算法,通过前向与反向计算阶段的重叠减少设备空闲时间,提升训练效率。
- EPLB:专家并行负载均衡器,优化计算资源分配,平衡专家复制的分布。
- Profile-data:公开训练和推理框架的性能分析数据,帮助开发者优化通信与计算重叠策略。
5.2月28日:3FS文件系统
- 功能:高性能并行文件系统,利用SSD和RDMA网络带宽,解决AI训练和推理中的存储瓶颈。
- 性能:在180节点集群中实现6.6TiB/s的聚合读取吞吐量,支持数据准备、检查点保存、推理KVCache等多种负载。

2、OpenAI发布最大最贵的模型GPT-4.5
本周五(2月28日),OpenAI新发布的GPT-4.5模型,与之前的版本相比,GPT-4.5在多个方面进行了改进,包括但不限于更广泛的知识面、减少幻觉现象、提高对用户意图的理解及增强情绪智能等。GPT-4.5支持联网搜索,并能够处理文件和图片上传,还可以使用Canvas来进行写作和编程。不过,目前GPT-4.5还不支持多模态功能,如语音模式、视频和屏幕共享。GPT-4.5主要通过「无监督学习」(就是自己从大量数据中学习)变得更聪明,而不是像OpenAI o1或者DeepSeek R1那样专注于推理能力。简单说,GPT-4.5知道的更多,而o1系列更会思考。API价格方面,因GPT-4.5计算量极大,成本高昂,价格涨到了75美元/百万tokens,是GPT-4o的30倍,更是DeepSeek的280倍。
3、Claude 3.7 Sonnet重磅发布
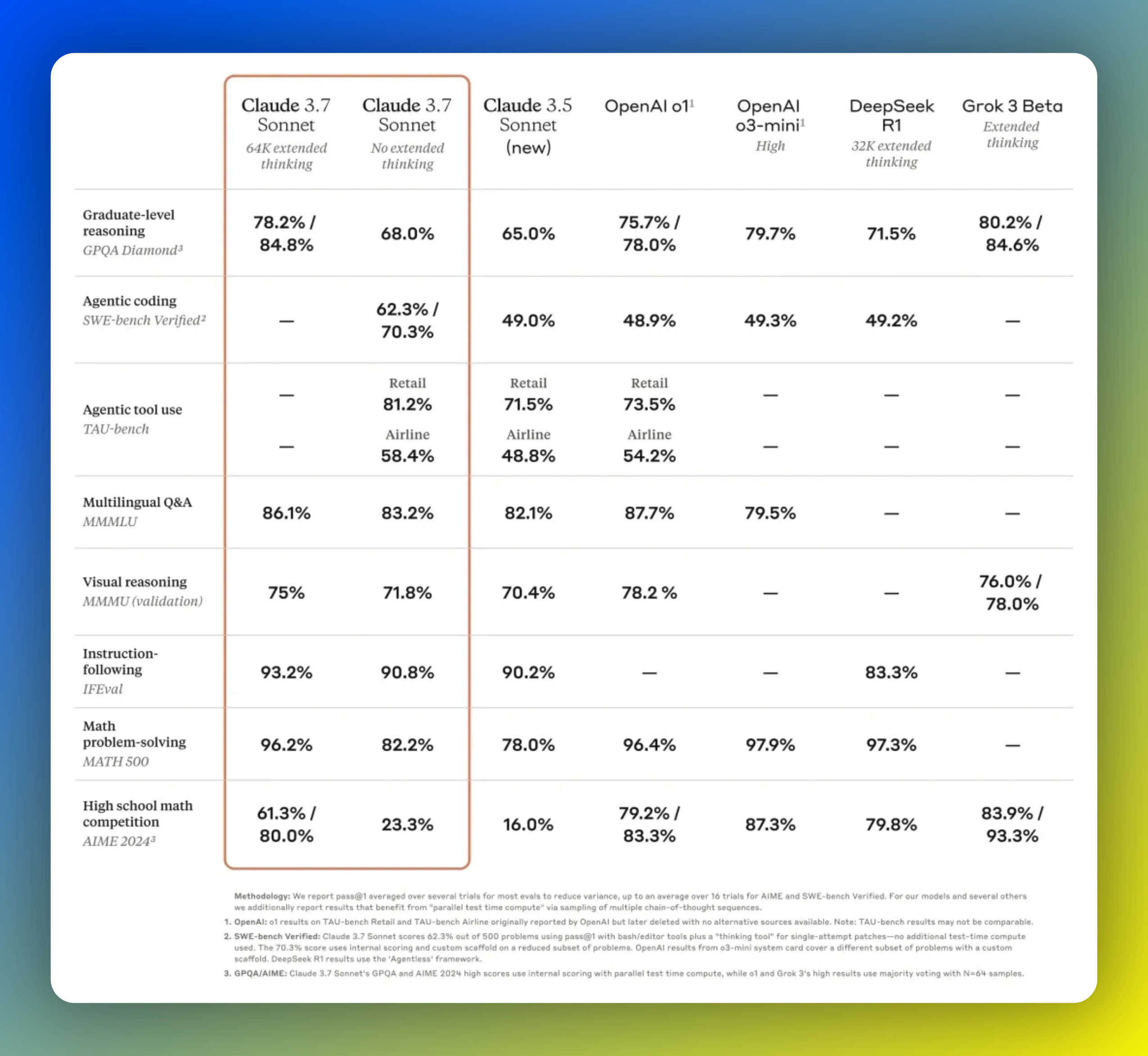
本周二(2月25日),Anthropic正式发布的Claude 3.7 Sonnet模型及其配套的智能编程助手Claude Code。Claude 3.7 Sonnet是全球首个采用混合推理方式的AI模型,能够在快速响应与深度自我反思之间切换,尤其擅长解决数学、物理及编程等领域的复杂问题。同时推出的Claude Code则专注于提高开发者的编码效率,能够直接理解并操作代码库,执行测试驱动开发、调试以及大规模代码重构等任务。Claude 3.7 Sonnet已经向所有用户和开发者推出,但只有付费购买Anthropic高级服务的用户才能获得完整的推理功能。免费用户则可使用标准版Claude 3.7 Sonnet。在定价方面,Claude 3.7 Sonnet每百万输入token收费3美元(约相当于处理75万个单词,比《指环王》全系列还多),每百万输出令牌收费15美元。
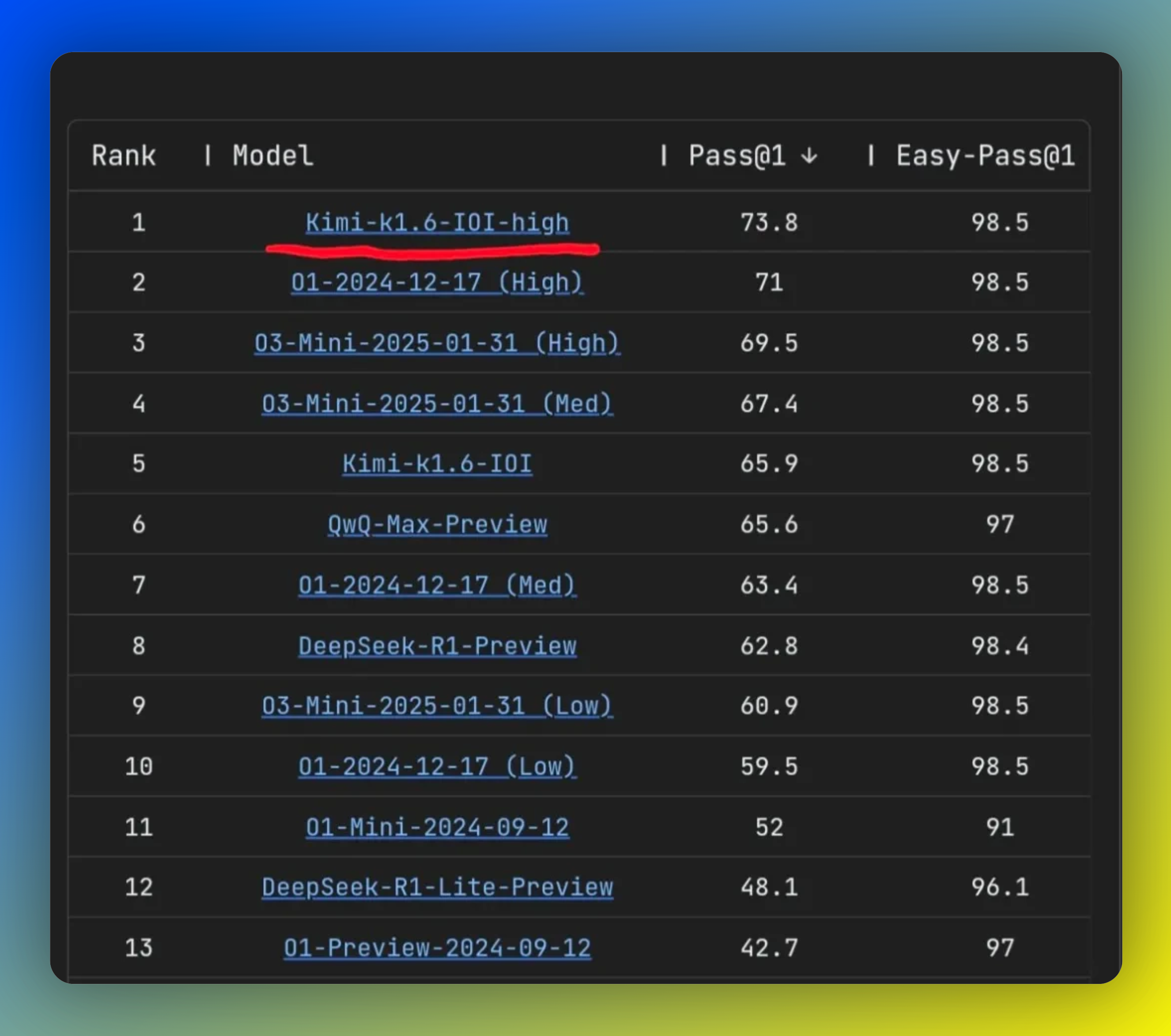
4、Kimi新模型k1.6曝光,代码生成能力超越o3-mini
月之暗面旗下Kimi的最新模型k1.6曝光。据全球动态基准测试平台LiveCode Bench显示,k1.6登上测试榜榜首。具体显示,k1.6-high在多项代码生成基准测试中超越OpenAIo3-mini、o1和通义QwQ-Max等多款模型。成绩公布后,月之暗面研究员FloodSung在其个人社交账号表示,榜单中的k1.6是一个基于k1.5持续训练代码能力的特定版本,目前k1.6还在不断训练并提升性能。
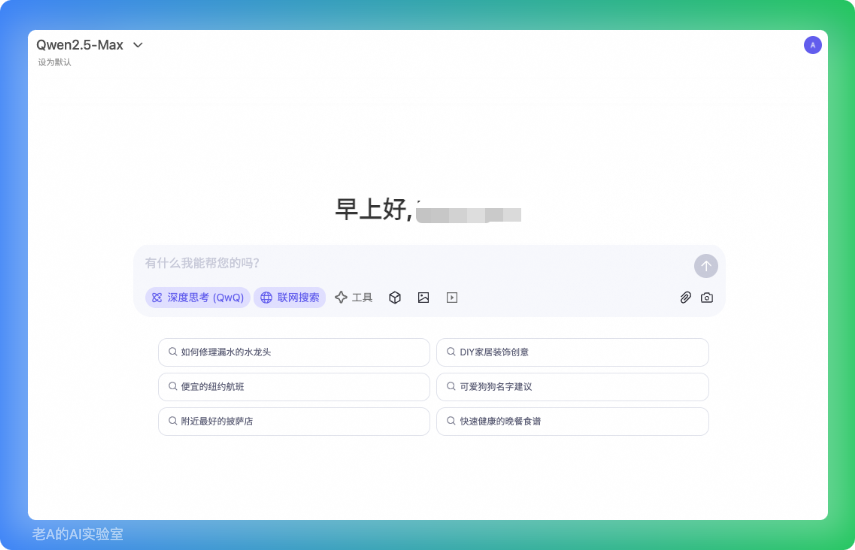
5、阿里千问上线深度思考模型
本周,阿里通义千问上线深度思考模型,基于QwQ-Max-Preview,即将开源,支持本地部署,Android/iOSAPP同步发布,左上角选Qwen2.5-Max,点上深度思考,里面模型用的就是QwQ-Max-Preview。
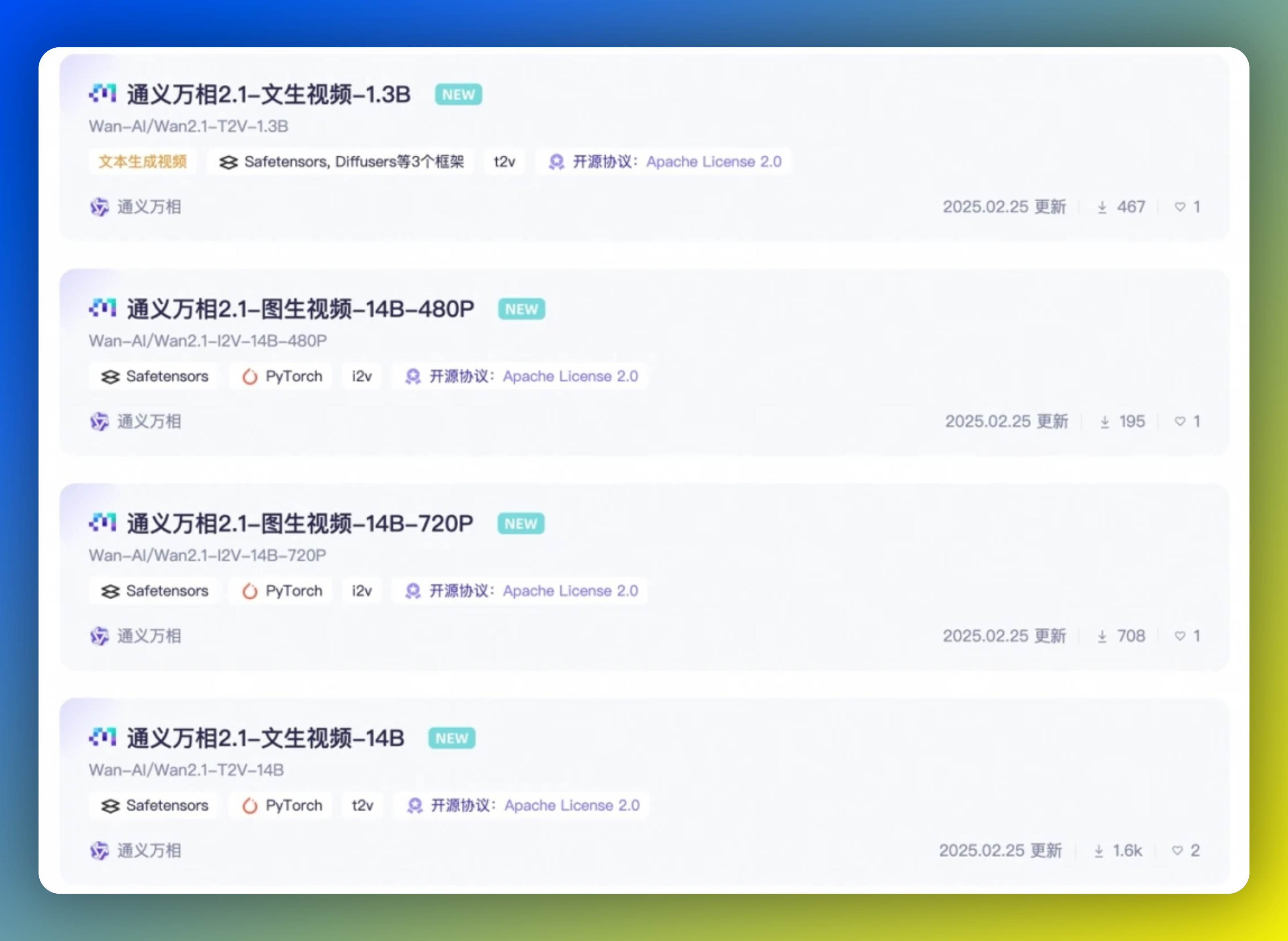
6、阿里开源视频生成模型万相2.1模型
本周二晚(2月25日),阿里巴巴宣布全面开源旗下视频生成模型万相2.1模型。此版本包括了两个不同规模(1.3B和14B)的文本转视频模型以及两个14B的图像转视频模型。14B万相模型在指令遵循、复杂运动生成、物理建模、文字视频生成等方面表现突出。在评测集VBench中,万相2.1以总分86.22%的成绩大幅超越Sora、Luma、Pika等国内外模型,稳居榜首位置。1.3B版本测试结果不仅超过了更大尺寸的开源模型,甚至还接近部分闭源模型,同时能在消费级显卡运行,仅需8.2GB显存就可以生成高质量视频,适用于二次模型开发和学术研究。值得注意的是,万相2.1还是首个具备支持中文文字生成能力,且同时支持中英文文字特效生成的视频生成模型。
- GitHub:https://github.com/Wan-Video
- HuggingFace:https://huggingface.co/Wan-AI
- 魔搭社区:https://modelscope.cn/organization/Wan-AI
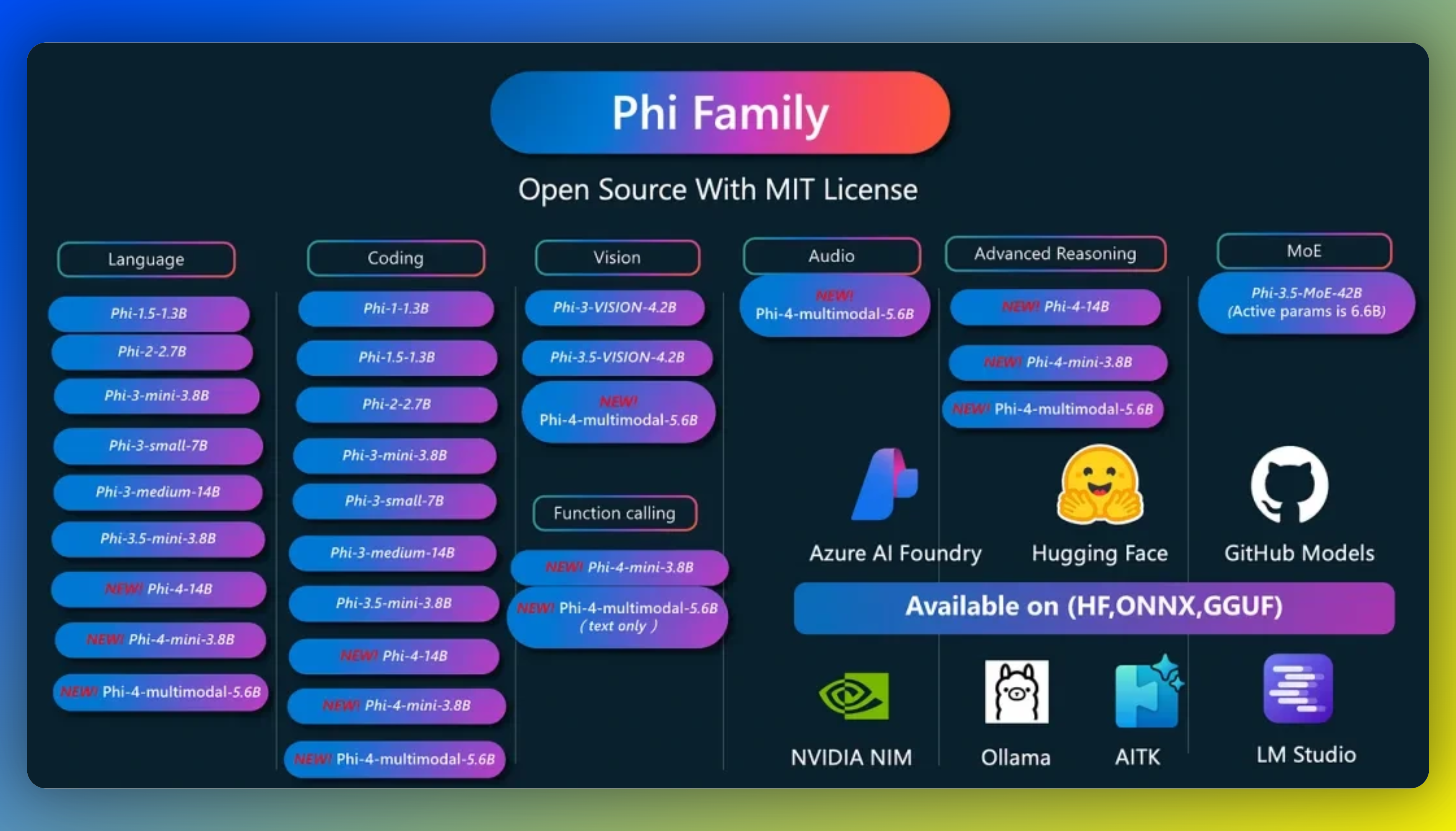
7、微软Phi-4家族成员上新
微软近日推出了两款全新的小型语言模型(SLM)——Phi-4-multimodal和Phi-4-mini。Phi-4-multimodal是一个拥有56亿参数的多模态模型,其最大特点是采用了「混合LoRAs技术」(Low-Rank Adaptations,低秩适应),能够同时处理语音、视觉和文本信息。用户可以在智能手机、汽车等本地设备上运行该模型,或者开发轻量级企业应用,如多语言金融服务应用等。另一款新模型Phi-4-mini拥有38亿参数,基于密集解码器架构,支持处理长达12.8万个标记的序列。微软表示,尽管体积小巧,该模型在文本任务方面的表现依然优于许多更大的模型,包括推理、数学、编程、指令跟随和函数调用等能力。在基准测试方面,Phi-4-multimodal在语音问答任务上与Gemini-2.0-Flash和GPT-4o-realtime-preview相比存在一定差距。不过,在数学和科学推理、光学字符识别(OCR)以及视觉科学推理方面,该模型的表现已超过了包括Gemini-2.0-FlashLite和Claude-3.5-Sonnet在内的多款大模型。
赛博·洞见
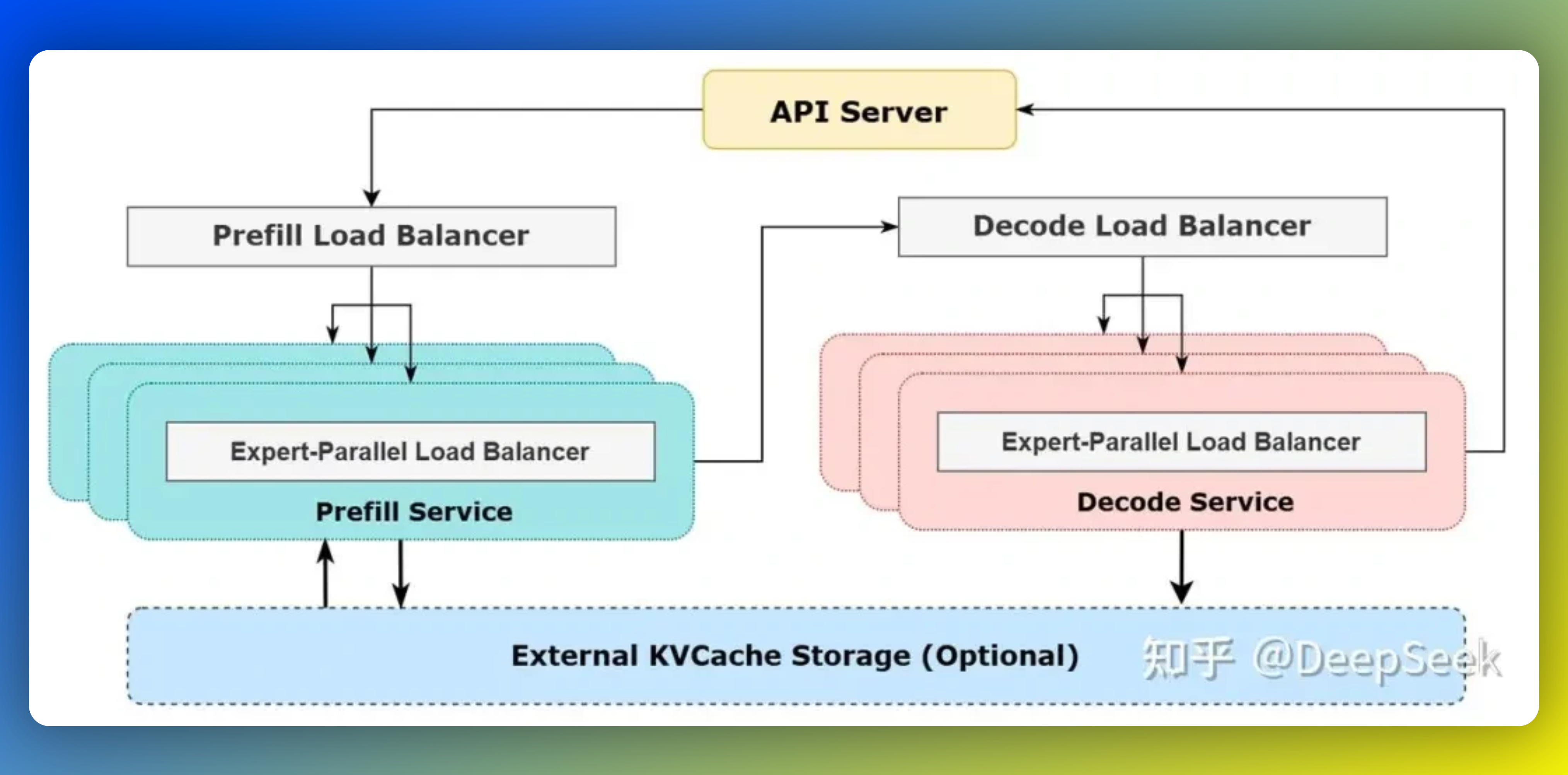
1、DeepSeek模型的成本利润率到底有多高?
文章通过官方渠道首次公开了DeepSeek-V3/R1模型的推理系统优化细节及成本利润率信息。为了提高吞吐量和降低延迟,DeepSeek采用了大规模跨节点专家并行(EP)技术,并通过计算通信重叠、负载均衡等手段进一步提升性能。此外,还分享了线上服务的实际统计数据,包括使用H800GPU进行推理服务的具体情况以及成本与收入之间的关系。根据官方测算,在特定条件下,DeepSeek模型的成本利润率可达到545%。
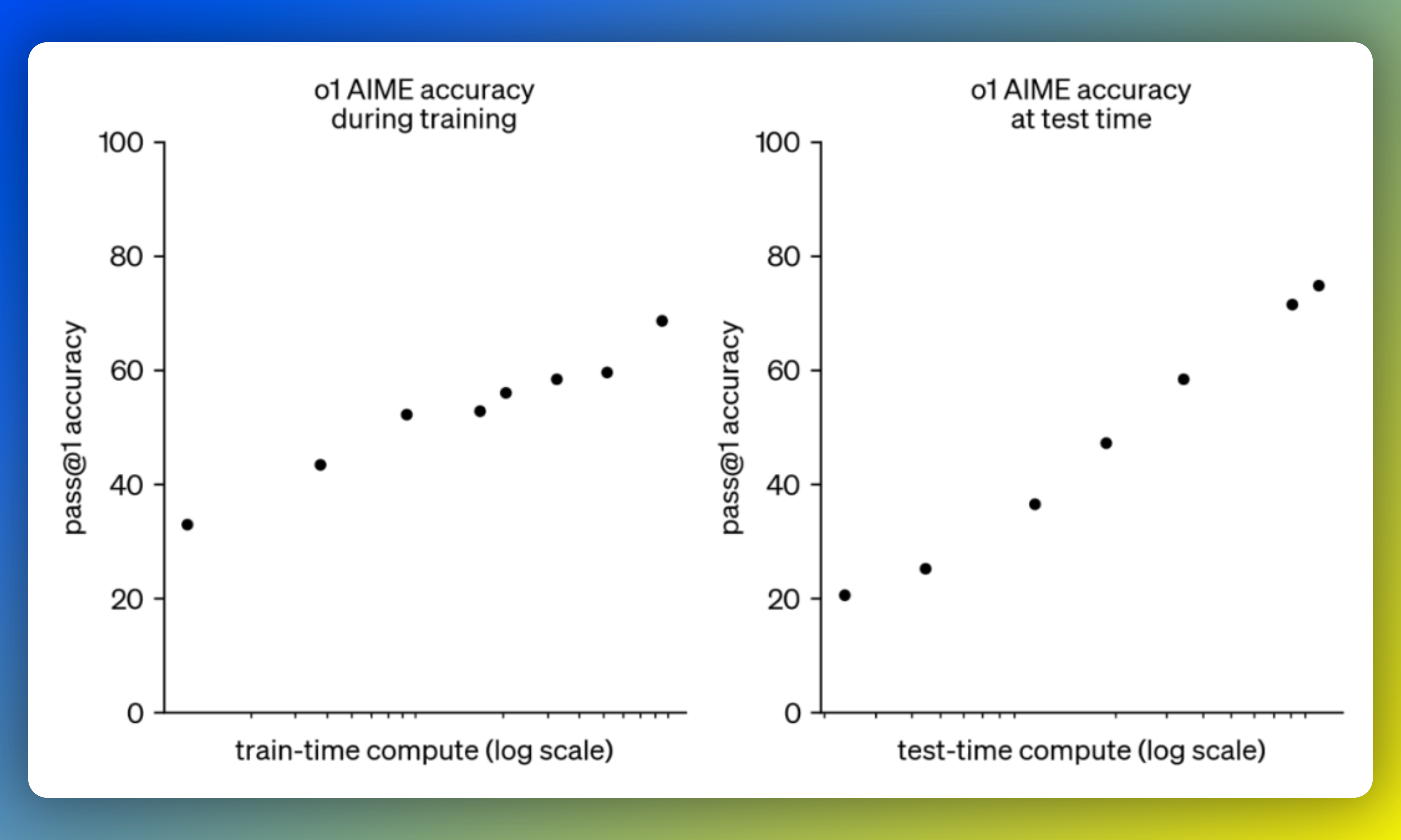
2、人工智能新世代:Claude3.7和Grok3
文章介绍了最新一代AI模型Claude3.7和Grok3,这些模型在训练计算能力和推理能力上都有了巨大飞跃。通过具体示例展示了这些模型在处理复杂任务如编程、创建交互式体验等方面的能力。同时,文章讨论了两大扩展法则对AI性能的影响,并指出随着模型规模扩大及技术进步,AI不仅能够加速现有工作流程,还能成为真正的智力伙伴,帮助人们解锁新的能力。
3、2小时思想碰撞,10000字深度思考:人类会被AI淘汰吗?
文章基于腾讯科技与腾讯研究院联合发起的《AGI之路系列直播》第二期内容,邀请专家刘永谋和陈永伟深入探讨了AI技术普及带来的“技术平权”及其潜在影响。两位专家指出,虽然AI降低了使用门槛,促进了机会平等,但同时也可能加剧资源分配不均的问题。此外,他们还讨论了AI对文科教育的重要性以及如何避免人类因过度依赖技术而失去自身特质等问题。最后,文章强调了正确看待技术发展的重要性,呼吁人们警惕“技术恐惧”。
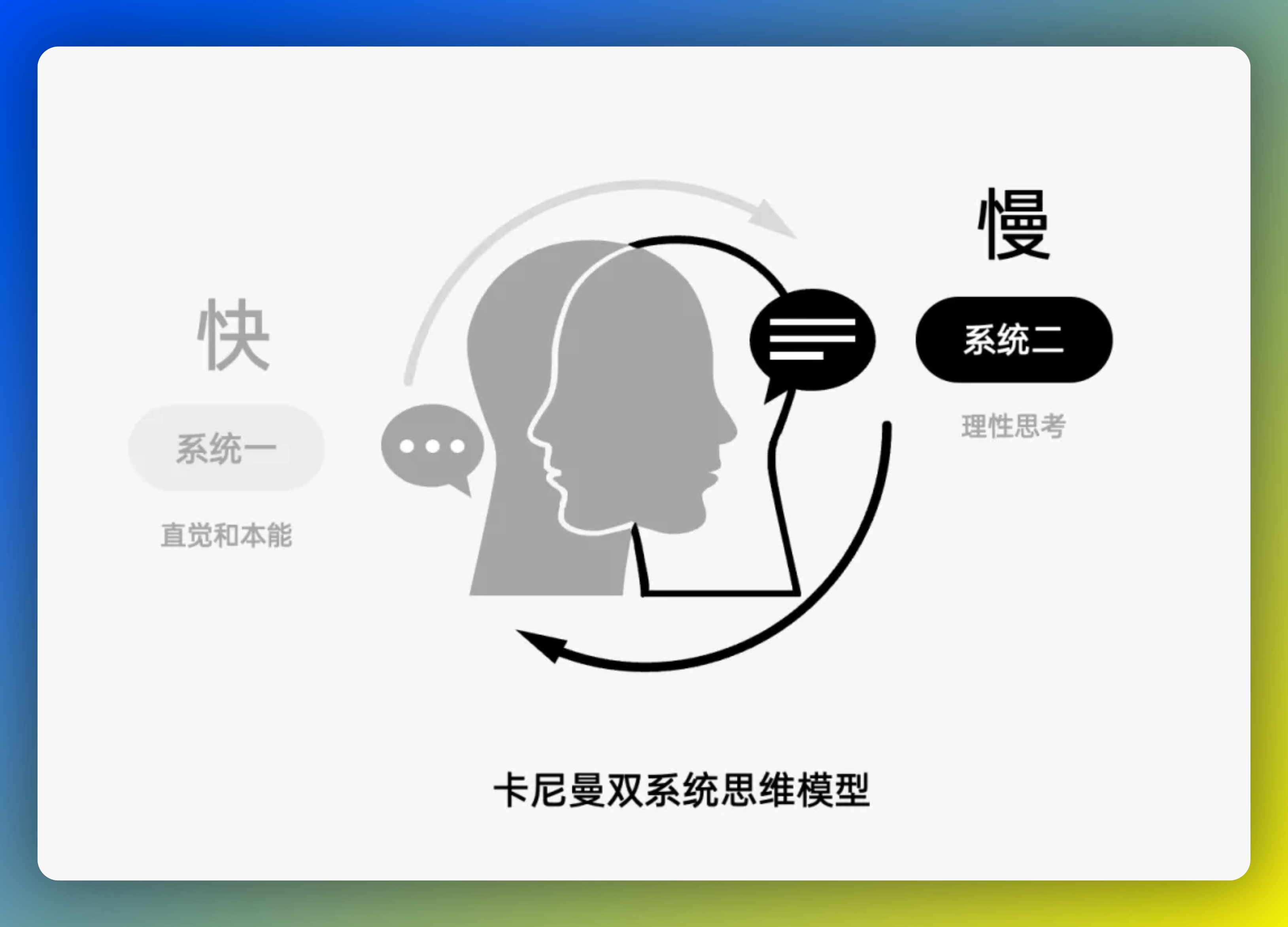
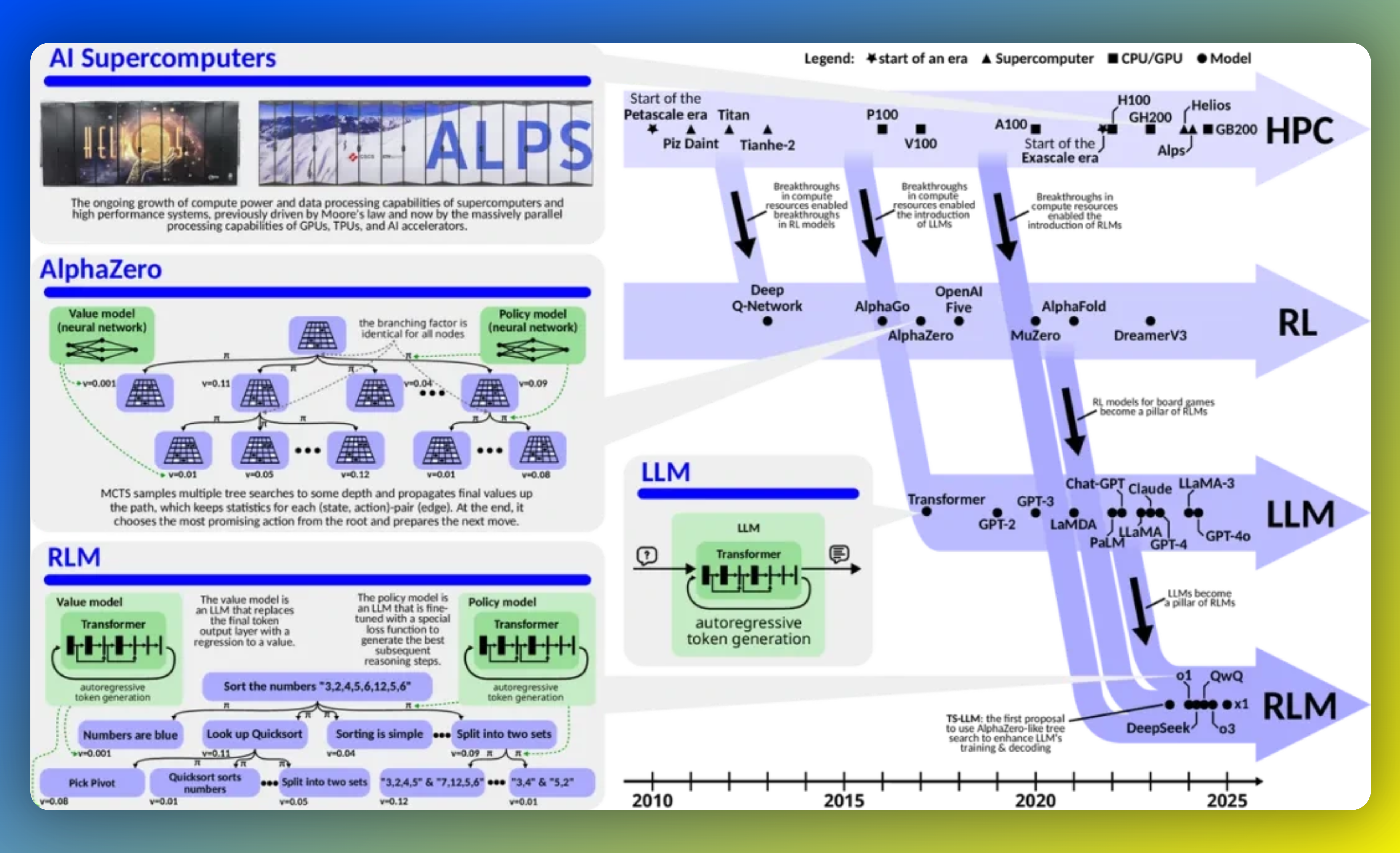
4、推理模型创新大爆发,DeepSeek、千问、O3背后的基础技术科普
随着2025年推理语言模型(RLM)的大规模发展,包括OpenAI O1、DeepSeek等在内的多个模型相继问世。本文基于苏黎世联邦理工学院学者发布的论文《Reasoning Language Models:ABlueprint》,对RLM进行了全面介绍。首先概述了RLM融合大型语言模型(LLM)的知识广度、强化学习(RL)的探索深度以及高性能计算(HPC)的支持,实现从直觉式预测到系统化问题解决的转变。接着详细解析了RLM的基本架构与核心流程,包括推理、训练和数据生成三大环节,并区分了隐式推理与显式推理两种机制的特点。最后,文章还探讨了如何设计RLM模型及构建过程中的有效经验分享,为研究者提供了宝贵的参考信息。
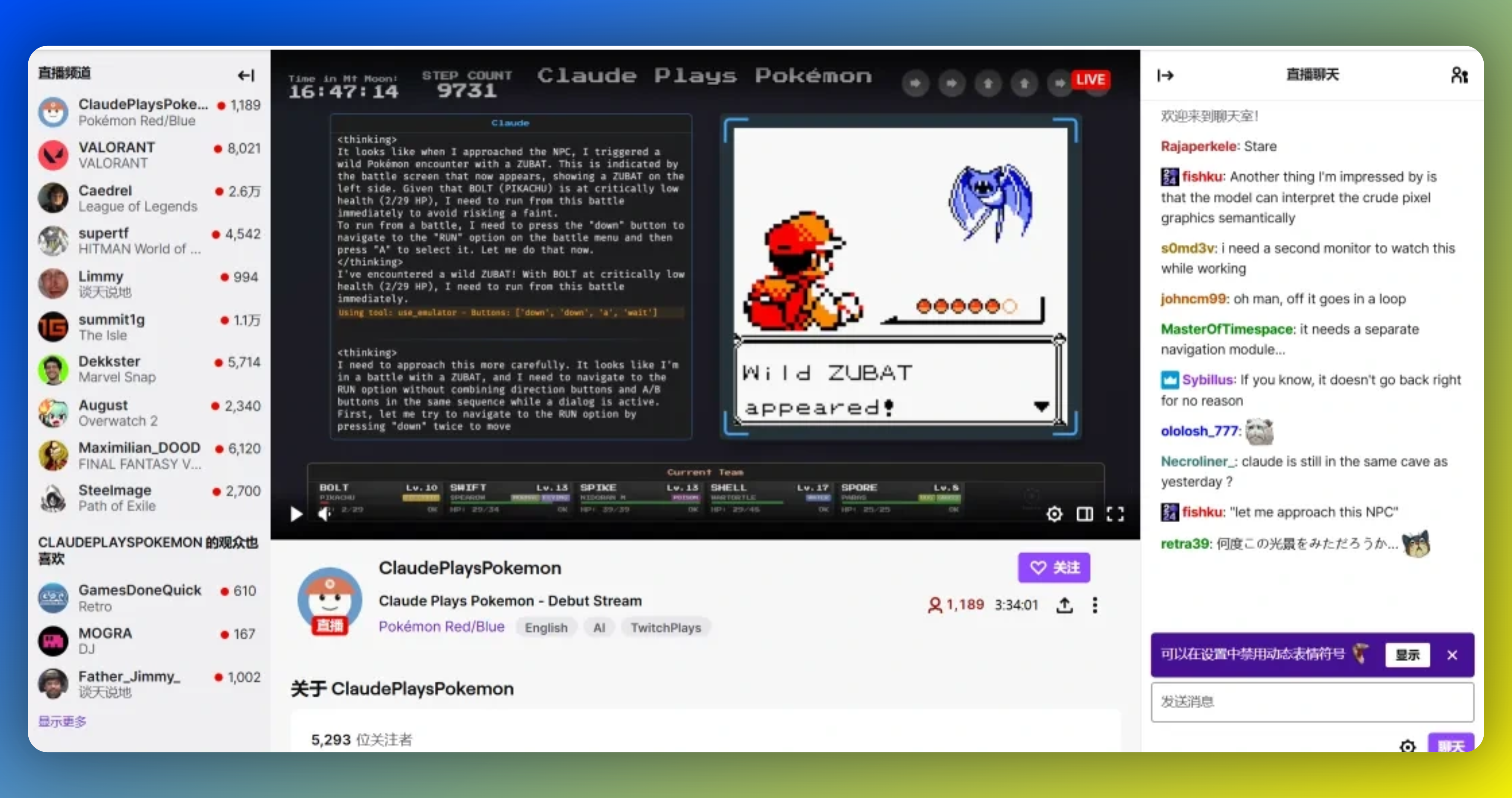
5、Claude3.7爆肝宝可梦:最强AI代练出道,连斩三馆主!程序员集体围观
Anthropic公司的AI模型Claude 3.7 Sonnet通过Twitch直播平台挑战1996年的GameBoy游戏《宝可梦・红》,展示了其强大的学习和适应能力。从初代版本无法走出新手村到3.7版本能够击败多个馆主,Claude的进步令人瞩目。该AI配备了像素级视觉解析、记忆外接硬盘、物理外设操控以及扩展思考模式等先进技术,使其能够在复杂的游戏环境中表现出色。直播过程中,Claude不仅展现了呆萌的一面,如给杰尼龟起名为“TSUNMAI”,也有高光时刻,例如发现隐藏道具并精准计算经验值。Anthropic的研究员表示,《宝可梦》是测试AI通用智能的理想环境,因为它涉及导航、战斗和资源管理等多个方面。此外,Claude 3.7 Sonnet还在编程任务上表现出色,比人类快45分钟完成代码编写。
6、Anthropic投资人最新分享:对垂直AI落地的十个判断
文章基于Bessemer投资机构的观点,深入讨论了垂直AI软件在未来的重要性及其潜在市场价值。通过分析多个垂直AI公司的案例,如EvenUp、SubtleMedical等,文章提出了十项关于垂直AI落地的关键策略,包括从客户实际需求出发设计产品、无缝融入现有工作流程以构建护城河、寻找生产力受限领域的落地机会、展示效率提升的价值、探索新的服务交付与定价方式、针对被忽视的工作流程进行优化、满足特定客户的复杂需求、利用多模态技术建立壁垒、关注模型堆栈的模块化和可扩展性以及重视高质量而非大量数据的重要性。这些策略为垂直AI公司提供了宝贵的指导方向。

7、DeepSeek荣光下:落寞的“六小龙”
随着DeepSeek的爆火,中国的大模型创业公司“六小龙”(包括零一万物、月之暗面、MiniMax等)所面临着巨大的困境。尽管这些公司在技术上有所突破,但与DeepSeek相比,在市场影响力、用户增长以及融资方面均处于劣势。文章强调了即使是在技术领先的情况下,如果不能有效转化为商业价值,企业也可能难以维持长期发展。通过对比不同企业的战略选择,展示了开放合作(如开源)可能是打破现有格局的有效途径之一。文章还提到,由于高昂的研发成本和技术人才稀缺,大模型公司的生存和发展面临严峻考验。此外,文中指出,未来可能只有少数几家大模型企业能够独立存活下来,而当前的竞争格局正在加速这一过程。

赛博·工具
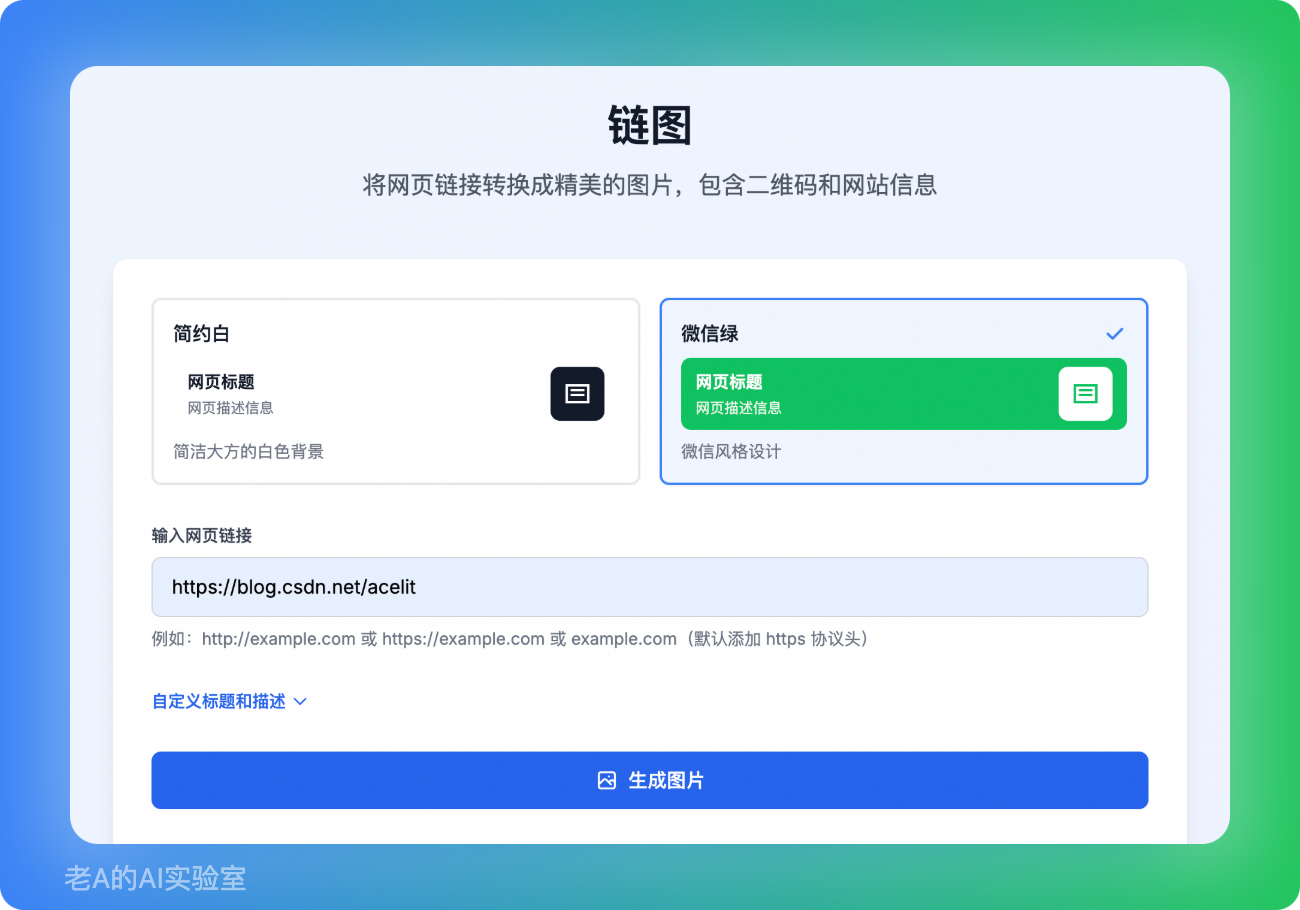
1、链图
一个开源的在线工具,将网址转成一张包含二维码、网站标题和简介的图片。
2、SHOTSLEEK截图美化
上传图片给截图添加背景让截图更美观。
3、svgrepo
提供超过50w个开源许可的SVG矢量图标和图标的平台,用户可以搜索、探索、编辑和分享这些资源,适用于商业项目,且始终免费,无需担心遇到付费内容。
赛博·资源
1、从DeepSeek爆火看25年AI行业发展(关注公众号【产品老A】回复【从DeepSeek爆火看25年AI行业发展】下载)
作者科技播客“屠龙之术”主播庄明浩,报告探讨了2025年AI行业的发展现状,尤其是DeepSeek模型的迅速崛起及其对行业的深远影响。报告指出,DeepSeek之所以能够爆火,关键在于其开源、低成本的特点,以及在推理模型上的显著进步。它象征着一种新的叙事正在形成,即通过强化学习和后训练提升AI性能,而非依赖于昂贵且效率逐渐降低的预训练方法。报告还讨论了AI行业中几个重要趋势:万物皆可Agent的理念扩展,强调推理模型在搜索、代码等具体场景中的应用;大模型技术范式的转变,从单纯的规模扩展转向注重成本效益和技术实际应用效果。此外,报告也关注到AI领域的竞争格局,包括战略投资与并购的重要性,并提出了关于未来产品形态、市场定位及商业模式的思考,特别是在如何构建“护城河”方面,如通过产品执行、用户运营等手段来增强竞争力。最终,报告以Deepseek的成功为例,暗示了开放合作可能比封闭竞争更能推动行业发展。

2、扣子平台智能体与AI应用数据分析报告
特工宇宙发布的扣子Coze平台智能体与AI应用数据分析报告,报告显示,截至2025年2月5日,coze平台已发布约39.2万个项目,其中智能体约38.2万个、AI应用约9500个、模板83个。平台创作者约19.3万,涵盖官方开发者、潜力开发者和社区活跃用户。从项目数据来看,不同类别的项目数量分布广泛,如角色类有92,000个、效率工具类70,000个。在各类项目排名中,不同创作者的作品表现各异。例如,总对话次数前十的智能体里,“猜人物”达4.1亿次对话;AI应用中,“豆包小说漫画推”使用次数达250K。模板方面,优质项目经官方审核成为模板供用户下载学习,创作者可获分成,如“短视频链接转爆款文案”复制量居全站第一。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











