







OLAP中数据存储的问题
OLAP 需要队列进行选择,行式存储按行存数据,使用索引加快对数据的查找(索引包括聚集索引(表记录的排列顺序与索引的排列顺序一致)和非聚簇索引(非聚集索引指定了表中记录的逻辑顺序,但记录的物理顺序和索引的顺序不一致))。这种方式对按列的存储和检索不是很高效,查询某一列数据需要将所有行的数据扫描一次,而且对统计分析也不友好。
列式存储原理
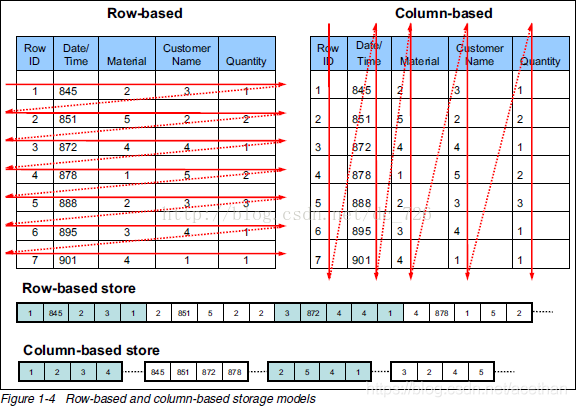
若使用列式存储可以只用扫描出需要的列,行、列存储的对比。
文件格式
parquet 文件格式:
如下图所示:parquet file = header + block * N + footer
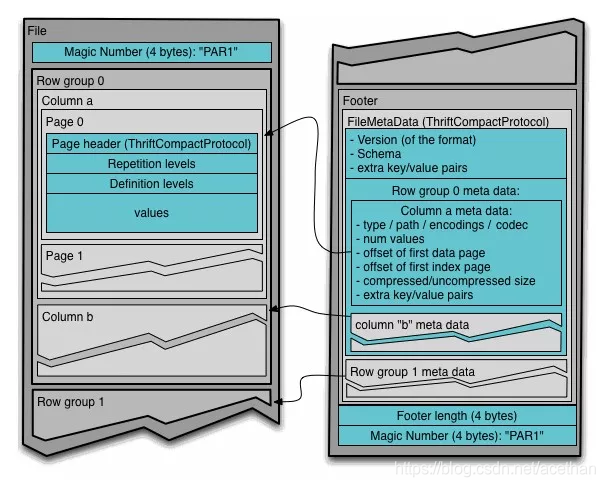
header :
block :
转换成层次图如下
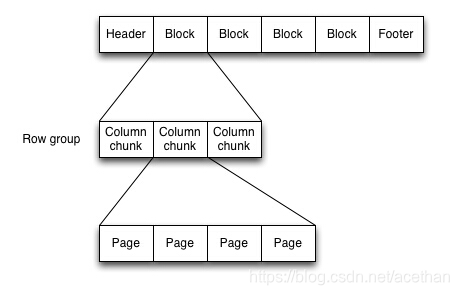
其中
行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,Parquet读写的时候会将整个行组缓存在内存中,所以如果每一个行组的大小是由内存大的小决定的。
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。不同的列块可能使用不同的算法进行压缩。
页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
footer:
文件中所有的metadata都存在于footer中。footer中的metadata包含了格式的
- 版本信息
- schema信息
- key-value paris
- 所有block中的metadata信息。
footer中最后两个字段为一个以4个字节长度的footer的metadata,以及同header中包含的一样的PAR1。
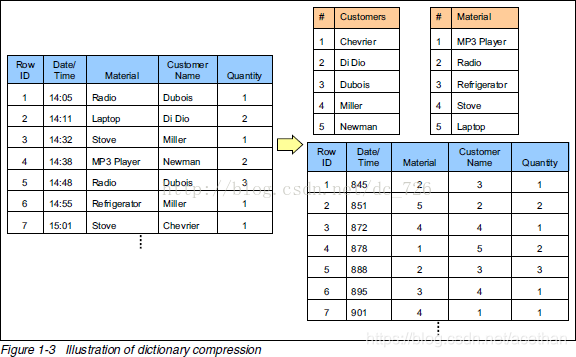
字典页
在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页,但是在后面的版本中增加。通过字典页可以压缩数据,原理如下图。http协议也用到了这种数据压缩方式。
列式存储查询数据
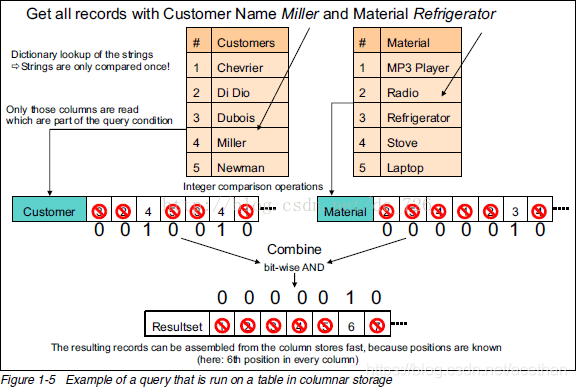
特点
- 映射下推
- 谓词下推
总结
行、列存储对比:
行式存储-优点
Ø 数据被保存在一起
Ø INSERT/UPDATE容易
Ø 查询时只有涉及到的列会被读取
列式存储-优点
Ø 投影(projection)很高效
Ø 任何列都能作为索引
行式存储-缺点
Ø 选择(Selection)时即使只涉及某几列,所有数据也都会被读取
列式存储-缺点
Ø 选择完成时,被选择的列要重新组装
Ø INSERT/UPDATE比较麻烦
参考:
官网:https://parquet.apache.org/
parquet 工具: https://github.com/wesleypeck/parquet-tools
blog:https://mp.weixin.qq.com/s/r0N8LOTmONAgoqFklznhgg















 3697
3697











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









