






李余诚
本文为国家级大创的部分研究成果,如有合作需要,请联系作者!
严禁盗用本文研究成果,违者必究!
2 单帧点云重建部分
2.1 多线结构光中心线提取
2.1.1 线结构光条特性
理想情况下,激光器投射出的线结构光光条截面的光强呈现高斯分布的特点,但是由于实际测量情况下,现场环境的干扰、激光器的质量以及被测物体表面材质等因素的影响,使得实际采集获得图像的光条如图2-1(a)所示,该光条某一个截面上的像素灰度值分布情况如 图2-1(b)所示,可以看出,越靠近光条中心处灰度值增加越迅速,并且中心处存在多个极值点,远离光条的两边灰度值近乎为零,整体灰度值分布近似呈现高斯分布的特点[2]。
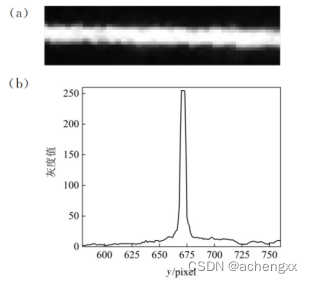
图2-1 激光光条及截面灰度值分布情况
(a)原始光条(放大)(b)光条截面像素灰度值分布
2.1.2 形态学操作与二值化
首先,先对原图进行双边滤波处理,再对处理后的图像进行轮廓查找,寻取出最大轮廓作为图像的前景,剩余部分作为图像背景,将背景部分全部设置成黑色,效果如图2-2所示:

图2-2 原图与前后景分离对比图
(a)原图(b)前后景分离后的图
下面对前景背景分离后的彩色图进行基于高斯加权均值的自适应二值化处理。
(1)转换颜色空间:将RGB图像转为灰度图像;
(2)确定权重:根据高斯加权公式,确定图像中每个像素点的权重;
(3)计算加权平均值:将确定好的权重应用到图像数据上,计算每个像素点邻域内的加权平均值。这里使用的邻域大小(即blockSize参数)可以根据需要进行调整;
(4)确定阈值:根据计算得到的加权平均值和给定的常数C(用于从均值中减去以得到阈值),确定每个像素点的阈值;
(5)二值化:根据确定的阈值对图像进行二值化处理。即,如果像素点的值大于或等于阈值,则将其设置为白色(或最大值maxval);否则,将其设置为黑色(或0)。
处理得到的自适应二值化结果如图2-3所示。

图2-3 自适应二值化处理图
针对阈值分割后获得的自适应二值化光条,本文还对其进行了形态学闭运算处理,弥合二值化光条较窄的间断和细长的沟壑、消除小的孔洞,并对其轮廓进行适当的平滑处理。
形态学闭运算是对图像进行先膨胀后腐蚀的一种图像处理技术,其数学模型为
![]()
式中,A为待处理图像,B为形态学运算的结构元素。
形态学膨胀可表示为:
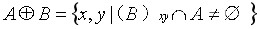
形态学腐蚀即为:
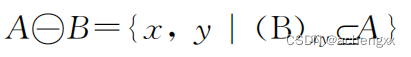
对二值化光条图像进行形态学闭运算处理,得到的结果如图2-4所示。
图2-4 形态学闭操作处理图
将处理后的二值化图像作为掩码,与上面前景背景分离后彩色图对应的灰度图进行图像位与运算,得到线结构光亚像素中心提取前的预处理灰度图,如图2-5所示。
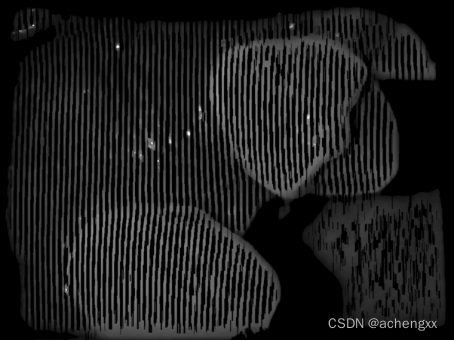
图2-5 中心线提取前的预处理灰度图
2.1.3 线结构光亚像素中心提取
本文采用基于线性插值的极值法进行线结构光亚像素中心提取。极值法是一种基于灰度分布函数的线结构光中心提取方法。其原理是通过遍历光条图像的每一行,找到每一行中灰度值最大的像素点(即极值点),将极值点的位置作为光条在该行的中心位置。极值法简单直观,计算量小,适用于实时性要求较高的应用场景。
其数学模型描述如下:
设图像为I,其中每个像素点(x,y)的灰度值为I(x,y)。我们关注图像的某一行y=k,其中k为常数。该行上的灰度值分布可以表示为一个一维函数f(x)=I(x,k)。
极值点定义:如果存在一个点x0,使得对于所有在x0附近的点x(即x在x0的某个邻域内,都有f(x)≤f(x0)(或f(x)≥f(x0)),则称x0为函数f(x)的局部极大值点(或局部极小值点)。在线结构光中心提取中,我们关注的是局部极大值点。
 具体实施方法如下:
具体实施方法如下:
首先用下述公式对预处理后的灰度图进行卷积,提取峰值特征[3]
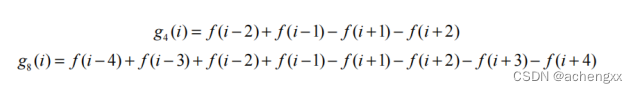 然后我们在卷积后图像中遇到符号变化的位置上通过线性插值来估计峰值中心的位置(图2-6)。这样,就得到了峰值中心位置的亚像素精度估计值。
然后我们在卷积后图像中遇到符号变化的位置上通过线性插值来估计峰值中心的位置(图2-6)。这样,就得到了峰值中心位置的亚像素精度估计值。
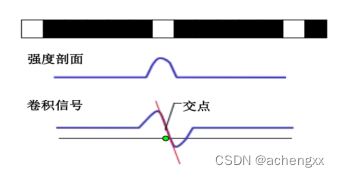
图2-6 基于线性插值的极值法原理图

图2-7 全局结构光亚像素中心提取效果图
2.2 多线结构光光平面匹配
2.2.1 多线结构光光平面匹配技术难点
单线结构光测量系统模型包含一个用于采集图像的相机和一个单线结构光发射器,系统构成较为简单。测量过程中,结构光映射到物体表面,相机获取物体表面调 制的具有一定分布的激光条纹,并提取激光条纹的中心点像素坐标,利用激光三角测量法计算得到中心点对应的三维空间坐标。单线结构光重建系统只有一条结构光条纹,相机一次采集图像,只能获取该条激光条纹中心点对应的三维空间坐标。这种扫描方式使系统采集数据速度较慢,效率较低。因此,本项目采用的是基于多线结构光的三维测量系统[4]。
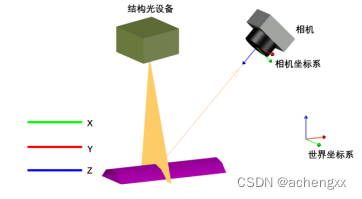
图2-8 单线结构光系统模型
多线结构光可以简单理解成单线结构光系统中线结构光数量的扩充,理论上来讲,可以将线结构光扩充至任意条,只要在相机的视域中能发现即可。但是,带来的问题是由于在三角测量中需要利用结构光平面来确定激光条纹中心点的三维空间坐标,多个光平面就会有多个光平面方程。对于一幅激光条纹中心点图像,由于物体表面形态各异,使被物体表面调制的多条激光条纹相互交错,导致难以辨别图像上的一个激光条纹中心点所属的实际光平面。
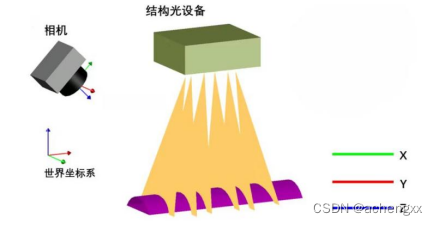
图2-9 单目多线结构光系统模型
本项目创新性的提出了一种基于彩色编码的单目多线结构光光平面匹配方法。克服了以下几项技术缺点:
1)多线结构光经过物体表面调制后,激光条纹相互交错,难以判断图像中的激光条纹中心点所属的实际光平面;
2)利用双目立体视觉的方法进行光平面匹配,需要使用两个相机,设备成本较大,且匹配运算量巨大、鲁棒性较差;
3)现有的颜色编码激光条纹方案,根据不同的激光颜色辨别光平面。虽然只使用了一个摄像机,但此方法对物体表面要求较高,尤其当线数较多且分布密集时,激光条纹存在颜色串扰、镜面反射、光干涉、易被物体表面颜色湮没等问题。
2.2.2 多线结构光光平面匹配技术具体实施方法
1)终端生成多线结构光投影图案。投影图案中结构光线数为8的正整数倍。线结构光的颜色编码方式为:8条激光线为一个周期,每个周期中含有绿色(用0标记此颜色)和蓝色(用1标记此颜色)两种颜色的线条,并按照“00001111”或“11110000”的顺序进行排列。在相邻的激光线之间,有黑暗的部分将它们彼此分开。激光线之间被予以相同大小的间隔,且各激光线之间相互平行。投影图案按此周期循环重复,以形成多线结构光的RGB编码模式。多线结构光RGB编码公式如下:

其中,L为图案中一个周期内x方向的长度,I(x)的值为0表示绿色,为1表示蓝色。
 图2-10 多线结构光投影图案
图2-10 多线结构光投影图案
2)终端输出图案至投影仪,投影仪将多线结构光图案投影到待测物体表面。相机采集待测物体表面图片,并将图片输出至终端。
3)终端对相机采集的图片进行激光中心线提取。此处常采用极值法、灰度重心法、Steger算法等方法进行激光中心线提取,具体方法选择不做限制。
4)针对提取到的激光线中心点,记其总数目为N、每个点灰度值大小为f(x,y)。寻找每一个激光线中心点左右两边最邻近的、灰度值大小为0.9*f(x,y)的像素点坐标,分别记其为(xL,yL)和(xR,yR)。通过这两个坐标作差得到该激光线中心点所在激光条纹光带的粗略宽度di。将图中所求全部di取均值,即可得全图平均激光条纹光带宽度d(d取与其最接近的奇数)。具体为:
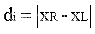
5)终端对相机采集得到的图片进行RGB颜色空间到HSV颜色空间的转换。以d*d大小的高斯权重矩阵为卷积核,在H颜色通道对每一行所提取到的激光线中心点依次进行卷积。以每个激光线中心点卷积后得到的H颜色通道值为纵坐标,其在该行激光线中心点的顺序索引为横坐标,构建针对每一行的“H通道值—顺序索引”波形图。
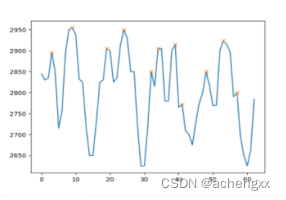
图2-11 “H通道值—顺序索引”波形图
6)对每一行构建的“H通道值—顺序索引”波形图进行波峰波谷检测,并利用相邻周期的顺序索引差值应为8,对所求所有波峰波谷进行筛选。最终得到的波峰为投影图案中每周期第二或第三条蓝色激光线所在位置,它代表着四条相邻蓝色激光线投影到待测物体上蓝色色调最显著的地方;得到的波峰为投影图案中每周期第二或第三条绿色激光线所在位置,它代表着四条相邻绿色激光线投影到待测物体上绿色色调最显著的地方。
7)判断波峰波谷处对应的具体光平面编号。在波形图上选取波峰左右两侧各两个邻近点,删除其中H通道值最小的一个点,将剩下的三个点连同波峰点共同组成一个四点判断列表。该四点判断列表对应着投影图案中,每周期中的四条相邻蓝色激光线。其中波峰点在四点判断列表中所在的索引,即对应着其在四条相邻蓝色激光线中所在的索引。再结合此波峰点在采集照片中所在大致位置,判断其属于投影图案中的第几周期,进而求得其在全图激光线中的具体编号。波谷点的具体光平面编号判断方法同理。

图2-12 波峰波谷处关键激光线编号图
8)根据现有的波峰波谷点的光平面编号结果,对图中剩余激光线中心点进行编号。剩余激光线中心点编号方法采用顺序编号,即已知某一激光线中心点光平面编号为j,则其右侧最邻近的一个激光线中心点光平面编号为j+1。

图2-13 全局激光线编号图
9)利用激光线的连续性,过滤噪声点和错误编号点,并将错误编号点重新编号。
2.3 多线结构光单帧点云重建
根据本文1.3部分标定得到的MATLAB参数文件,从中对每个文件中的每个数据集单元进行索引后,提取出单元内的6×1标定参数(分别记为Ai,i=1,2...6)。采用5次拟合公式对数据进行拟合,求出目标像素点的三维坐标(x,y,z),其中(u,v)为提取为中心点的像素点的坐标:
x = A1∗v5+A2∗v4+A3∗v3+A4∗v2+A5∗v1+A6
y,z同理。
将所得三维坐标集进行处理后生成点云文件,即为口扫过程中每一帧对应的点云图像(如图2-14所示)。
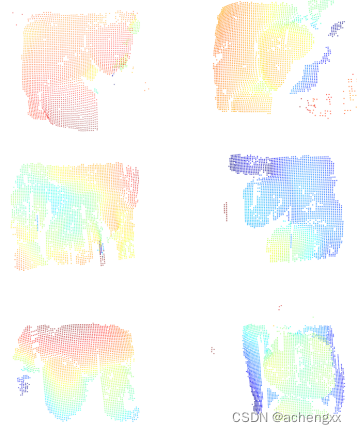
图2-14 单帧点云重建效果图
参考文献:
[2]张佳,陆永华,梁立鹏,赵采仪,.线结构光条纹自适应中心提取优化算法【J】.应用激光,2019,(06):1028-1034.
[3]Gühring J. Dense 3D surface acquisition by structured light using off-the-shelf components[C]//Videometrics and Optical Methods for 3D Shape Measurement. SPIE, 2000, 4309: 220-231.
[4]孙海卫.基于多线结构光的三维测量研究【D】.烟台大学,2021(09).
该章节部分核心代码如下:
main:
import open3d
import cv2 as cv
import numpy
from get_total_dict import get_newtotal_dict
from get3d import Get_3D
from write3d import show3d
import time
time1 = time.time()
img = cv.imread("1.bmp")
##获取中心线编号字典
total_dict = get_newtotal_dict(img)
##获取三维坐标列表
threeD_lst = Get_3D(total_dict)
time2 = time.time()
print("总用时" + str(time2 - time1))
##显示三位点云
show3d(threeD_lst)
中心线提取核心代码:
import numpy as np
import cv2 as cv
def show(name,img):
cv.imshow(name,img)
cv.waitKey(0)
cv.destroyAllWindows()
def rowconvolution(rowlist):
kernel = np.array([-1, -1, -1, -1, -1, 0, 1, 1, 1, 1])
# 使用卷积核进行卷积
convolved_values = np.convolve(rowlist, kernel, mode='same')
return convolved_values
def findchange(convolved_values):
sign_changes = np.where((convolved_values[1:] * convolved_values[:-1] < 0))[0] ##sign_changes里面包含了符号改变位置的索引
return sign_changes
def linearinterpolation(newgray,img):
subpixelindex = [] ##储存线性插值点的索引的列表(保留三位小数)
floatsubpixelindex = []
row,col = np.shape(newgray)
# graybinary = np.zeros_like(newgray)
for i in range(row):
rowsubpixelindex = [] ##存储三位索引
introwsubpixelindex = [] ##储存整型索引
rowlist = newgray[i,:]
convolved_values = rowconvolution(rowlist) ##对行向量进行卷积
sign_changes = findchange(convolved_values) ##sign_changes里面包含了符号改变位置的索引
for j in sign_changes: ##(j是i行像素值变号位置的索引)
if newgray[i,j]<12 or newgray[i,j]>200: ##(将灰度小于该值或大于该值的点不认做是激光线中心点)
pass
else:
index = (0 - convolved_values[j]) / (convolved_values[j + 1] - convolved_values[j]) + j
rowsubpixelindex.append(("{:.3f}".format(index)))
introwsubpixelindex.append((int(index)))
distance = 14
##下面这些是胡写的弥补缺线算法,可以随时删
try:
nextdistance = rowsubpixelindex[-1] - rowsubpixelindex[-2]
if nextdistance > 1.65*distance and nextdistance < 2.45*distance: ##缺一条线
insertline = rowsubpixelindex[-2] + (nextdistance/2)
rowsubpixelindex.insert(-1,("{:.3f}".format(insertline)))
introwsubpixelindex.insert(-1,int(insertline))
elif nextdistance < 0.65*distance or (1.35*distance < nextdistance < 1.65*distance): ##该点与左边的点太近,不符合规范,删除
del rowsubpixelindex[-1]
del introwsubpixelindex[-1]
except:
pass
# rowsubpixelindex.append("{:.3f}".format(index))
# graybinary[i,j] = 255
# img[i,j] = (0,0,255)
subpixelindex.append(introwsubpixelindex) ##将每一行的线性插值点的索引作为一个列表添加进总图像线性插值索引列表中
floatsubpixelindex.append(rowsubpixelindex)
for i in range(row):
for j in subpixelindex[i]:
img[i,j] = (0,0,255)
return img,subpixelindex,floatsubpixelindex
图像主体提取代码(基于最大轮廓查找):
##该文件中的newimg函数功能在于将初始彩色图像进行ROI区域提取,
##并将高亮反光点和噪声点删去,为后续处理奠定基础,返回值是一张处理后的彩色图
import cv2 as cv
import numpy as np
def show(name,img):
cv.imshow(name,img)
cv.waitKey(0)
cv.destroyAllWindows()
def newimg(img):
#二值化
bilateralFilter = cv.bilateralFilter(img, 15, 120, 100) ##采用高斯双边滤波,保留边缘信息
gray = cv.cvtColor(bilateralFilter, cv.COLOR_BGR2GRAY)
# 设定阈值
threshold_low = 20
threshold_high = 150##将高亮反光点过滤
# 对图像进行二值化处理
ret, binary = cv.threshold(gray, threshold_low, 255, cv.THRESH_BINARY)
# _,otsu = cv.threshold(gray, 0, 255, cv.THRESH_OTSU | cv.THRESH_BINARY)
# show("otsu",otsu)
##膨胀选取感兴趣区域(ROI)
# kernel = np.ones((5,5),np.uint8)
# dilate = cv.dilate(otsu,kernel,iterations=1)#膨胀
# show("dialate",dilate)
##选取最大面积的轮廓
contours, hierarchy = cv.findContours(binary, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE) ##轮廓查找,第一个返回值是轮廓,第二个是层级
# cv.drawContours(img, contours, -1, (0,0,255), 2) ##绘制轮廓,改变的是img这张图。因为画的是红色,要在三通道图像上面画,二值化图像是单通道
# show("img",img)
area=[]
for i in range(len(contours)): ##找寻面积最大的轮廓
area.append(cv.contourArea(contours[i]))
max_idx = np.argmax(np.array(area))
mask = np.zeros(np.shape(binary),dtype=np.uint8)
# ret, inverted_binary_image = cv.threshold(gray, threshold_high, 255, cv.THRESH_BINARY_INV)
cv.drawContours(mask, contours, max_idx, 1, cv.FILLED)
newimg = cv.bitwise_and(img,img,mask=mask)
# newimg = cv.bitwise_and(newimg,newimg,mask= inverted_binary_image)
return newimg
图像自适应二值化与形态学处理核心代码:
##本文件中的函数旨在获得自适应二值化,灰度图,彩色图
import cv2 as cv
import numpy as np
def show(name,img):
cv.imshow(name,img)
cv.waitKey(0)
cv.destroyAllWindows()
def adaptivebinary(gray):
img = cv.adaptiveThreshold(src=gray, maxValue=255, adaptiveMethod=cv.ADAPTIVE_THRESH_GAUSSIAN_C,
thresholdType=cv.THRESH_BINARY, blockSize=25, C=0)
##我希望对自适应二值化后的图像进行纵向膨胀(或者闭运算)的处理
# 定义结构元素的高度和宽度
kernel_height = 5
kernel_width = 1
# 创建纵向结构元素
vertical_kernel = np.ones((kernel_height, kernel_width), np.uint8)
# 进行膨胀操作
# img = cv.dilate(img, vertical_kernel, iterations=1)
img = cv. morphologyEx(img, cv.MORPH_CLOSE, vertical_kernel, iterations=4)
img = cv. morphologyEx(img, cv.MORPH_OPEN, vertical_kernel, iterations=4)
# show("newbin",img)
return img
def adaptivegray(img):
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
maskbinary = adaptivebinary(gray)
newgray = cv.bitwise_and(gray,gray,mask=maskbinary)
return newgray
def adaptiveimg(img):
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
maskbinary = adaptivebinary(gray)
newimg = cv.bitwise_and(img,img,mask=maskbinary)
return newimg关键颜色定位线提取代码:
import numpy as np
import cv2 as cv
def codekeyline(n,i,number,total_dict,float_subpixelindex):
coordinate = (n,float_subpixelindex[n][i+4])
total_dict[number].append(coordinate)
def greenkeypoints(n,subpixelindex,newdistancearray,distance,x,min_peaks,img,float_subpixelindex,total_dict,keylabel_dic): ##x是一行中扫描出来的去掉头尾的中心点的5邻域h通道
for i in min_peaks:
if i+3 > len(x) or i-2 < 0 :
continue
else:
lst = list(x[i-2:i+3]) ##取最小值左右的各两个值,总共五个值
# myindex = lst.index(max(lst)) ##myindex代表了最大值是删除的里面的第几个
# del lst[myindex] ##lst此时类型已为列表,不再是array
lst.remove(max(lst)) #此时lst中只剩下四个点
minindex = lst.index((min(lst)))
index_1 = i-minindex+0
index_2 = i-minindex+1
index_3 = i-minindex+2
if index_3 >= len(newdistancearray):
index_3 = index_2
##下面判断该点属于第几个周期:
col = subpixelindex[n][i+4] ##col 表示最低点所在的列数
if 960 - distance * 3 < col < 960 + distance * 5:
cycle = 2
elif 960 + distance * 13 < col < 960 + distance * 21:
cycle = 3
elif 960 + distance * 29 < col < 960 + distance * 37:
cycle = 4
elif 960 + distance * 45 < col < 960 + distance * 53:
cycle = 5
elif 960 + distance * 61 < col < 960 + distance * 69:
cycle = 6
elif 960 - distance * 19 < col < 960 - distance * 11:
cycle = 1
else:
continue
##下面判断四个点之间的距离是否合规
dis_1 = newdistancearray[index_1] ##第一个点与第二个点之间的距离
dis_2 = newdistancearray[index_2] ##第二个点与第三个点之间的距离
dis_3 = newdistancearray[index_3] ##第三个点与第四个点之间的距离
# print(dis_1,dis_2,dis_3)
if dis_1<1.3*distance and dis_2<1.3*distance and dis_3<1.3*distance: ##三组差值全无问题
# print("第"+str(s)+"组四条线无缺失")
number = 16 * cycle+minindex
codekeyline(n,i,number,total_dict,float_subpixelindex)
# cv.putText(img,str(number) , (col, n), cv.FONT_HERSHEY_SIMPLEX, 0.3,
# (255, 255, 255), 1)
keylabel_dic[i+4] = number
else:
# print("第"+str(s)+"组四条线有缺失")
lst.remove(max(lst)) ##此时lst只含有三个元素了,这三个元素一定是四条线中的其中三条
minindex = lst.index((min(lst)))
newindex_1 = i - minindex + 0
newindex_2 = i - minindex + 1
newdis_1 = newdistancearray[newindex_1] ##第一个点与第二个点之间的距离
newdis_2 = newdistancearray[newindex_2] ##第二个点与第三个点之间的距离
if newdis_1<1.3*distance and newdis_2<1.3*distance: ##新的两组差值都符合要求
if dis_1>1.3*distance: ##说明是第一条线没有
number = 16 * cycle + minindex +1
codekeyline(n, i, number, total_dict, float_subpixelindex)
# cv.putText(img, str(number), (col, n), cv.FONT_HERSHEY_SIMPLEX, 0.3,
# (255, 255, 255), 1)
keylabel_dic[i + 4] = number
else: ##说明是第四条线没有
number = 16 * cycle + minindex
codekeyline(n, i, number, total_dict, float_subpixelindex)
# cv.putText(img, str(number), (col, n), cv.FONT_HERSHEY_SIMPLEX, 0.3,
# (255, 255, 255), 1)
keylabel_dic[i + 4] = number
if newdis_1>1.3*distance and newdis_2<1.3*distance: ##新的第一组差值不符合要求
number = 16 * cycle + minindex + 1
codekeyline(n, i, number, total_dict, float_subpixelindex)
# cv.putText(img, str(number), (col, n), cv.FONT_HERSHEY_SIMPLEX, 0.3,
# (255, 255, 255), 1)
keylabel_dic[i + 4] = number
if newdis_1<1.3*distance and newdis_2>1.3*distance: ##新的第二组差值不符合要求
number = 16 * cycle + minindex
codekeyline(n, i, number, total_dict, float_subpixelindex)
# cv.putText(img, str(number), (col, n), cv.FONT_HERSHEY_SIMPLEX, 0.3,
# (255, 255, 255), 1)
keylabel_dic[i + 4] = number
def bluekeypoints(n,subpixelindex,newdistancearray,distance,x,peaks,img,float_subpixelindex,total_dict,keylabel_dic): ##x是一行中扫描出来的去掉头尾的中心点的5邻域h通道
for i in peaks:
if i+3 > len(x) or i-2 < 0 :
continue
else:
lst = list(x[i-2:i+3]) ##取最小值左右的各两个值,总共五个值
lst.remove(min(lst)) #此时lst中只剩下四个点
maxindex = lst.index((max(lst)))
index_1 = i-maxindex+0
index_2 = i-maxindex+1
index_3 = i-maxindex+2
if index_3 >= len(newdistancearray):
index_3 = index_2
col = subpixelindex[n][i+4] ##col 表示最低点所在的列数
if 960 - distance * 9 < col < 960 - distance * 1:
cycle = 2
elif 960 + distance * 7 < col < 960 + distance * 15:
cycle = 3
elif 960 + distance * 23 < col < 960 + distance * 31:
cycle = 4
elif 960 + distance * 39 < col < 960 + distance * 47:
cycle = 5
elif 960 + distance * 55 < col < 960 + distance * 63:
cycle = 6
elif 960 - distance * 25 < col < 960 - distance * 17:
cycle = 1
else:
continue
# try:
##下面判断四个点之间的距离是否合规
dis_1 = newdistancearray[index_1] ##第一个点与第二个点之间的距离
dis_2 = newdistancearray[index_2] ##第二个点与第三个点之间的距离
dis_3 = newdistancearray[index_3] ##第三个点与第四个点之间的距离
# print(dis_1,dis_2,dis_3)
if dis_1<1.3*distance and dis_2<1.3*distance and dis_3<1.3*distance: ##三组差值全无问题
# print("第"+str(s)+"组四条线无缺失")
number = 16 * cycle + maxindex - 6
codekeyline(n, i, number, total_dict, float_subpixelindex)
# cv.putText(img,str(number) , (col, n), cv.FONT_HERSHEY_SIMPLEX, 0.3,
# (255, 255, 255), 1)
keylabel_dic[i+4] = number
else:
# print("第"+str(s)+"组四条线有缺失")
lst.remove(min(lst)) ##此时lst只含有三个元素了,这三个元素一定是四条线中的其中三条
maxindex = lst.index((max(lst)))
newindex_1 = i - maxindex + 0
newindex_2 = i - maxindex + 1
newdis_1 = newdistancearray[newindex_1] ##第一个点与第二个点之间的距离
newdis_2 = newdistancearray[newindex_2] ##第二个点与第三个点之间的距离
if newdis_1<1.3*distance and newdis_2<1.3*distance: ##新的两组差值都符合要求
if dis_1>1.3*distance: ##说明是第一条线没有
number = 16 * cycle + maxindex - 5
codekeyline(n, i, number, total_dict, float_subpixelindex)
# cv.putText(img, str(number), (col, n), cv.FONT_HERSHEY_SIMPLEX, 0.3,
# (255, 255, 255), 1)
keylabel_dic[i + 4] = number
else: ##说明是第四条线没有
number = 16 * cycle + maxindex - 6
codekeyline(n, i, number, total_dict, float_subpixelindex)
# cv.putText(img, str(number), (col, n), cv.FONT_HERSHEY_SIMPLEX, 0.3,
# (255, 255, 255), 1)
keylabel_dic[i + 4] = number
if newdis_1>1.3*distance and newdis_2<1.3*distance: ##新的第一组差值不符合要求
number = 16 * cycle + maxindex - 5
codekeyline(n, i, number, total_dict, float_subpixelindex)
# cv.putText(img, str(number), (col, n), cv.FONT_HERSHEY_SIMPLEX, 0.3,
# (255, 255, 255), 1)
keylabel_dic[i + 4] = number
if newdis_1<1.3*distance and newdis_2>1.3*distance: ##新的第二组差值不符合要求
number = 16 * cycle + maxindex - 6
codekeyline(n, i, number, total_dict, float_subpixelindex)
# cv.putText(img, str(number), (col, n), cv.FONT_HERSHEY_SIMPLEX, 0.3,
# (255, 255, 255), 1)
keylabel_dic[i + 4] = number
# except:
# pass

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











