






 本文介绍了特征维度约减的概念,尤其是PCA方法,以及其在机器学习中的作用,包括提高查询速度、去除噪声和用于高维数据可视化。通过PCA在人脸识别中的应用实例,展示了如何通过降维提高分类准确性,结合SVM进行高效的人脸识别。
本文介绍了特征维度约减的概念,尤其是PCA方法,以及其在机器学习中的作用,包括提高查询速度、去除噪声和用于高维数据可视化。通过PCA在人脸识别中的应用实例,展示了如何通过降维提高分类准确性,结合SVM进行高效的人脸识别。
一、特征维度约减的概念
二、为什么要维度约减?
三、常规维度约减方法
四、Principal Component Analysis(PCA)
是一种常用的特征维度约减方法,它通过线性变换将原始数据映射到一个新的特征空间,使得映射后的特征具有最大的方差。
PCA的基本思想是找到一个新的坐标系,使得数据在新的坐标系下的方差最大化。具体步骤如下:
-
数据预处理:对原始数据进行标准化,使得每个特征的均值为0,方差为1。
-
计算协方差矩阵:根据标准化后的数据计算协方差矩阵。
-
特征值分解:对协方差矩阵进行特征值分解,得到特征值和对应的特征向量。
-
选择主成分:按照特征值从大到小的顺序,选择前k个特征向量作为主成分,其中k是降低的维度。
-
数据映射:将原始数据通过选取的主成分进行线性变换,得到降维后的数据。
样本数据:
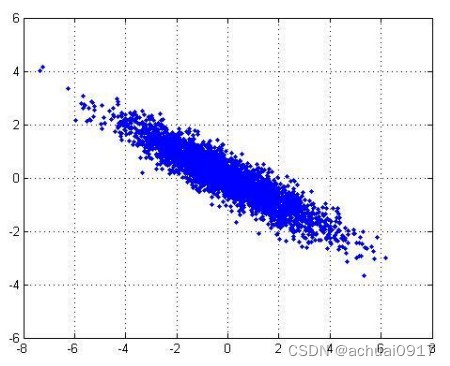
1st主成分:

2nd主成分:
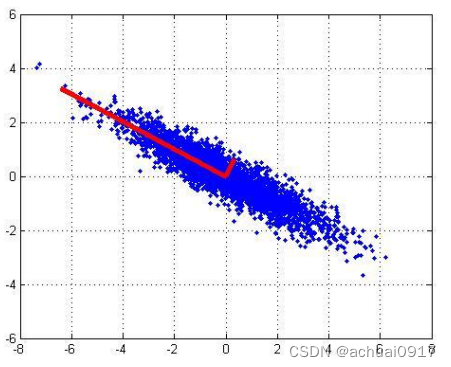
五、主成分的代数推导


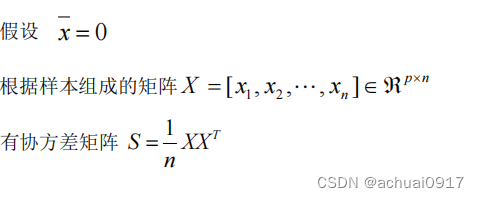
六、根据PCA完成人脸识别
import numpy as np
from sklearn.decomposition import PCA
from sklearn.datasets import fetch_lfw_people
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
# 加载人脸数据集
lfw_dataset = fetch_lfw_people(min_faces_per_person=100)
X = lfw_dataset.data
y = lfw_dataset.target
target_names = lfw_dataset.target_names
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 使用PCA进行维度约减
n_components = 150
pca = PCA(n_components=n_components, whiten=True, random_state=42)
pca.fit(X_train)
# 应用PCA转换到训练集和测试集
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
# 使用支持向量机进行分类
svm = SVC(kernel='linear', C=0.1, random_state=42)
svm.fit(X_train_pca, y_train)
# 在测试集上进行预测
y_pred = svm.predict(X_test_pca)
# 输出准确率
accuracy = np.mean(y_pred == y_test)
print(f"Accuracy: {accuracy}")
当然,下面是对上述代码的详细解释:
1、导入必要的库:
在这里,我们导入了NumPy用于数值计算,sklearn.decomposition模块中的PCA类用于主成分分析,sklearn.datasets模块中的fetch_lfw_people函数用于加载人脸数据集,sklearn.model_selection模块中的train_test_split函数用于划分训练集和测试集,sklearn.svm模块中的SVC类用于支持向量机分类。
2、加载人脸数据集:
这里使用fetch_lfw_people函数从LFW数据集中加载人脸数据,并将数据存储在X中,目标类别存储在y中,目标类别的名称存储在target_names中。min_faces_per_person参数用于控制每个人至少有多少张人脸图像。
3、划分训练集和测试集:
使用train_test_split函数将数据划分为训练集和测试集。这里将70%的数据用于训练,30%的数据用于测试。
4、使用PCA进行维度约减:
创建PCA对象,并指定要保留的主成分数量(这里设置为150)。whiten参数用于指定是否对数据进行白化处理。然后使用fit函数拟合训练集数据。
5、应用PCA转换到训练集和测试集:
使用transform函数将原始数据转换为降维后的数据。转换后的数据存储在X_train_pca和X_test_pca中。
6、使用支持向量机进行分类:
创建SVC对象,并指定使用线性核函数。C参数用于控制正则化强度。然后使用fit函数拟合降维后的训练集数据。
7、在测试集上进行预测:
使用predict函数对降维后的测试集数据进行预测,预测结果存储在y_pred中。
8、输出准确率:
计算预测准确率并输出。np.mean函数用于计算预测结果与真实标签之间的平均一致性。
希望这样的解释能够帮助您理解代码的执行流程和目的。如果还有其他问题,请随时提问。
运行结果:

七、实验总结
- 主成分分析(PCA)是一种常用的降维技术,尤其适用于处理高维数据。通过PCA,可以找到原始数据中最重要的特征,并将其转换为较低维度的表示形式,从而提高计算效率和模型性能。
- PCA在人脸识别领域有广泛的应用。通过降维,可以减少数据集的特征数量,并且仍然能够保留足够的信息来进行人脸分类和识别。
- 在实验中,选择合适的主成分数量对于识别准确性至关重要。过少的主成分可能会丢失重要信息,导致低准确率;而过多的主成分可能会引入噪声和冗余特征,导致过拟合。
- 结合适当的分类算法,如SVM,可以提高人脸识别的性能。SVM是一种强大的分类器,能够有效地处理高维数据,并在不同类别之间建立清晰的决策边界。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









