







简介
在经过sklearn.decomposition.PCA的transform()方法转换后,我们可以轻松得到原始数据转换后(降维)的矩阵,inverse_transform(X)方法可以让我们把转换后的矩阵变回为转换前的矩阵。但是我们无法知晓中间的过程,也就意味着我们无法轻松的移植到其他平台上。好在pca类提供了pca.componets_属性,可以帮助我们使用矩阵运算手写转换。
代码示例
from sklearn.decomposition import PCA
df_X = df.drop(columns=['Name','Time'])
pca = PCA(n_components=3)
df_X_pca = pca.fit_transform(df_X)
在这个例子中呢,我们的df_X的shape是(181,16),也就是有16个维度,我们的PCA选取了前三个维度,包含了90%的变异解释率,所以转换后得到的df_X_pca的shape是(181,3)。
接下来我们打印出pca.componets_并保存
comp = pca.components_
print(comp)

后面太长就不放了,comp的维度是(3,16)。
一.如果我们要把原矩阵转化为transform后的矩阵,只需要:
df_X_M = df_X - df_X.mean()
np.dot(df_X_M,np.linalg.pinv(comp))
先是减去各列的均值,再使该矩阵和comp的逆矩阵(此处因为不是方阵,所以用pinv方法求伪逆矩阵)相乘。
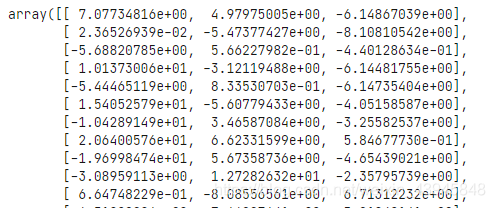
就可以得到和transform一模一样的转换后的结果。
二.把转换后的矩阵还原,是以上的逆过程:
np.matmul(df_X_pca,comp) + df_X.mean()
这个转换后的结果和原来有一点误差,因为你已经降维了,如果维度数小于原来的维度,是不能100%还原的。














 7662
7662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









