







学习笔记的文件层次结构为:
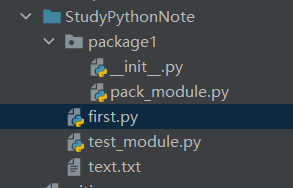
[StudyPythonNote](根目录):
--------first.py
--------test_module.py
--------text.txt
--------[package1](python包):
==========__init__.py
==========pack_module.py
first.py
# coding:utf-8
# author:ChenBaijing
# date:2022/3/31 22:40
# #将数据输出到文件当中
# fp=open('D:/Python/MyCode/text.txt','a+') #a+为追加方式打开文件 r只读 w重写
# print('helloworld',file=fp)
# fp.close();
#
# print('hello','world','=-=')
# # /n换行 /r覆盖 /t水平制表符 /b退格
# print('he\rwwww')
# #原字符
# print(r'http:\\www.baidu.com')
# name='xxx'
# print('数据标识:',id(name))
# print('数据类型:',type(name))
# print('数据值:',name)
# #按规定格式计算浮点类型数据
# from decimal import Decimal
# print(Decimal('1.1')+Decimal('2.2'))
# # 强制类型转换 str() int() float()
# age = 18
# print('我叫xxx,今年'+str(age)+'岁了')
# age = input('输入你的年龄')
# print(age,type(age))
# # /除法运算 //整除运算 **幂运算
# print(11/2,11//2,3**3)
# 一正一负的整除公式是向下取整
# a=b=c=20
# print(a,id(a),b,id(b),c,id(c))
# a-=10
# print(a,id(a),b,id(b),c,id(c))
# a,b,c=1,2,3
# print(a,b,c)
# # 交换
# a,b = b,a
# print(a,b)
# # 变量是由标识id,变量类型,变量值组成
# # 比较a,b的标识id是否一致用is is not
# a,b,c=10,10,1
# print(a is b)
# print(a is not c)
# # 4算术左移两位
# print(4<<2)
# 运算符的优先级:算数运算>位运算>比较运算>布尔运算>赋值运算
# money=1000
# s=int(input('请输入取款金额:'))
# if money>=s:
# money-=s
# print('取款成功,余额为',money)
# else:
# print('余额不足')
# score=int(input('请输入您的成绩:'))
# if score>100 or score<0:
# print('请输入有效数据')
# elif 90<=score<=100:
# print('A')
# elif 80<=score<90:
# print('B')
# elif 70<=score<80:
# print('C')
# elif 60<=score<70:
# print('D')
# else:
# print('E')
# answer=input('您是会员么?Y/N:')
# money=int(input('您的购物金额:'))
# if answer=='Y':
# if 100<=money<200:
# print(money*0.9)
# elif money>=200:
# print(money*0.8)
# else:
# print(money)
# else:
# if money>=200:
# print(money*0.9)
# else:
# print(money)
# num_a=int(input('请输入第一个数:'))
# num_b=int(input('请输入第二个数:'))
# print( str(num_a)+'>='+str(num_b) if num_a>=num_b else str(num_a)+'<'+str(num_b) )
# 若判断为真则执行左侧--------------------否则执行右侧
# pass什么都不做 只是占位符
# # range()返回值是一个迭代器对象
# # range(step) 创建一个[0,step)之间的整数序列 步长为1
# # range(start,stop) 创建一个[start,stop)之间的整数序列 步长为1
# # range(start,stop,step) 创建一个[start,stop)之间的整数序列 步长为step
# r=range(1,10,2)
# print(list(r))
# # 用in和not in判断一个整数在序列中是否存在
# print(8 in r)
# temp=1
# while temp<10:
# print(temp,end=' ')
# temp+=1
# for item in 'Python':
# print(item,end=' ')
# r = range(10)
# for item in r:
# print(item,end=' ')
# for _ in range(5):
# print('hello world')
# sum=0
# for item in range(1,101):
# if not item%2:
# sum+=item
# print(sum)
# # 水仙花数
# for item in range(100,1000):
# num_1=item//100
# num_2=(item-num_1*100)//10
# num_3=item%10
# if num_1**3+num_2**3+num_3**3 == item:
# print(item)
# for item in range(1,51):
# if not item%5:
# continue
# else:
# print(item,end=' ')
# # else的特殊用法 可与循环搭配
# for item in range(3):
# pwd=input('请输入密码:')
# if pwd=='8888':
# print('密码正确')
# break
# else:
# print('密码错误')
# else:
# print('三次密码均错误')
# for i in range(3):
# for j in range(4):
# print('*',end='')
# print()
# row=1
# while row<10:
# for list in range(1,row+1):
# print(str(row)+'*'+str(list)+'='+str(row*list),end=' ')
# print()
# row+=1
# # ========[列表 值 有序]========
# # 列表可以使用负向索引 若索引越界则抛出异常
# lst=['hello','world',98]
# print(id(lst),type(lst),lst,lst[1])
# lst2=list(['HELLO','WORLD',99])
# print(id(lst2),type(lst2),lst2,lst2[-2])
# # index可以获取列表中数据的索引 列表中有多个相同元素 只返回第一个元素的索引 或者可以在指定位置区间查找 若元素不存在会抛出异常
# lst=['hello','world',98,'hello']
# print(lst.index('hello'))
# print(lst.index('hello',1,4))
# # 列表切片 list[start:stop:step] 范围[start,stop) 步长step
# # 切片的结果是一个新的列表
# lst=[1,2,3,4,5,6,7,8,9,10]
# lst2=lst[1:6:1]
# print('初试列表id:'+str(id(lst)))
# print('切片列表id:'+str(id(lst2)))
# # 将原列表逆置
# print(lst[::-1])
# print('p' in 'python')
# print('k' not in 'python')
# # ========列表操作========
# # append()在末尾新增一个元素 extend()在末尾至少添加一个元素 insert()在列表任意位置添加元素
# lst1=list([10,20,30])
# lst2=list([10,20,30])
# lst1.append(100)
# print(lst1)
# lst3=['hello','world']
# lst1.append(lst3) #将lst3作为一个元素添加到列表中
# print(lst1)
# lst2.extend(lst3) #将lst3作为多个元素添加到列表中
# print(lst2)
# lst2.insert(1,200)
# print(lst2)
# # 切片 切片在任意位置添加任意个数元素
# lst4=[True,False,'python']
# lst3 [1:]=lst4
# print(lst3)
# # remove()移除首次匹配值的元素 若不存在抛出异常 pop()根据索引移除 若不存在抛出异常 默认删除最后一个 clear()清空列表 del删除列表
# lst=[10,20,30,40,50,60,30]
# lst.remove(30)
# print(lst)
# lst.pop(1)
# print(lst)
# #切片至少删除一个元素
# lst[1:3]=[]
# print(lst)
# lst.clear()
# print(lst)
# del lst
# lst=[10,20,30,40]
# lst[2]=100
# print(lst)
# lst[1:3]=[100,200,300,400]
# print(lst)
# # 排序 sort()默认升序排序 reverse=True逆置排序 sorted()内置函数排序 将产生一个新的列表对象
# lst=[4,5,6,4,1,6,48,8,4,6]
# lst.sort()
# print(lst)
# lst.sort(reverse=True)
# print(lst)
# lst2=sorted(lst)
# print(lst2)
# # 列表生成式 语法格式: [变量(可为变量表达式) for 变量名 in range()]
# lst1=[name for name in range(1,11,2)]
# lst2=[name * name for name in range(1,11,2)]
# print(lst1)
# print(lst2)
# # ========{字典 键值对 无序 哈希函数计算位置所以键是不可变序列且键唯一}========
# # 字典操作
# scores={'张三':100,'李四':80,'王五':'未参加考试'}
# print(scores)
# info=dict(name='jack',age=20)
# print(info)
# print(scores['张三']) # 用该方式查询不存在的键会抛出异常
# print(info.get('iphone')) # 用该方式查询不存在的键会返回None
# print(info.get('iphone','不存在')) # 指定返回默认值
# print('iphone' in info)
# del scores['王五'] # 删除指定键值对
# print(scores)
# scores.clear() # 清空字典
# print(scores)
# del scores # 删除字典
# info['iphone']='1213121' # 字典元素新增
# print(info)
# for item in info: # 遍历字典
# print(item,'=',info.get(item),end=' ')
# # 字典视图 keys()获取所有key values()获取所有value items()获取所有键值对
# scores={'张三':100,'李四':80,'王五':'未参加考试'}
# keys=scores.keys() # 键视图
# print(keys,type(keys))
# list_keys=list(keys) # 键视图转列表
# print(list_keys,type(list_keys))
# values=scores.values() # 值视图
# print(values)
# items=scores.items()
# print(items) # 返回的视图值以(元组)为单位
# print(list(items)) # 转换后的列表也以(元组)为单位
# # 字典生成式 内置函数zip()将可迭代的对象作为参数,将对象中对应的元素打包成一个元组然后返回由这些元组组成的列表
# # 字典生成式格式 {key(可为key的表达式):value for key,value in zip(key,value)}
# items=['Fruits','Books','Others']
# prices=[96,78,85]
# dire={items:prices for items,prices in zip(items,prices) }
# print(dire)
# dire2={items+'价格为:':prices for items,prices in zip(items,prices) }
# print(dire2)
# # ========(元组 内置数据结构 不可变序列)========
# # 在多任务环境下 同时操作不可变序列时不需要加锁 因为谁也操作不了不可变序列 只能看
# # 注意事项: 1.如果元组本身是不可变对象 则不能引用其他对象 2.如果元组中对象是可变对象 则可变对象的引用不允许改变 但数据可以改变
# # 对注意事项的解释: (9,[20,30],10) 不可以改写为 (9,100,10) 但可改写为 (9,[20,30,100],10)
# 元组操作
# tuple1=('python','world',98)
# print(tuple1,type(tuple1))
# tuple2=tuple(('helloo','world',99)) # 空元组创建方式 t=() t=tuple()
# print(tuple2,type(tuple2))
# tuple3=('tuple3') # 当元组只包含一个元素必须加上逗号否则会认为是声明变量
# tuple4=('tuple4',)
# print(tuple3,'type:',type(tuple3))
# print(tuple4,'type:',type(tuple4))
# print(tuple1[0])
# for item in tuple1: # 遍历元组
# print(item,end=' ')
# # ========{集合 内置数据结构 无序 可变序列 集合元素唯一}========
# # 相当于没有value的字典 也采用了哈希表
# # 集合操作
# # add()向集合中添加一个元素 update()向集合中至少添加一个元素 可以是元组 列表 集合 或多个数据
# # remove()删除一个指定元素 不存在则抛出异常 discard()删除指定元素 不抛出异常 pop()删除任意一个元素 若空抛异常 clear()清空集合
# s1={'python','hello',90,90}
# s2=set(['helloo','world',99,'world'])
# print(s1)
# print(s2)
# print('hello' in s1)
# s1.add(80)
# s2.update((11,66,'abcde'))
# print(s1)
# print(s2)
# s1.remove(90)
# print(s1)
# s1.discard(90)
# s=s1.pop()
# print('删除元素:',s,'删除后为:',s1)
# s1.clear()
# print(s1)
# del s1
# # 集合之间的关系 ==相等 A.issubset(B) A是B的子集? A.issuperset(B)A是B的超集? A.isdisjoint(B)A与B无交集?
# s1,s2,s3,s4={10,20,30,40},{40,30,20,10},{10,20,30,40,50,60},{10,20,90}
# print(s1==s2,s1!=s2)
# print('s2是s1的子集么?',s2.issubset(s1))
# print('s3是s1的子集么?',s3.issubset(s1))
# print('s3是s1的超集么?',s3.issuperset(s1))
# print('s4和s1无交集?',s4.isdisjoint(s1))
# # 集合的数学操作
# # intersection()等价于& 求取交集 union()等价于| 求取并集 difference()等价于- 求差集
# # symmetric_difference()等价于^ 求对称差集
# s1={10,20,30,40}
# s2={20,30,40,50,60}
# print(s1.intersection(s2))
# print(s1 & s2)
# print(s1.union(s2))
# print(s1 | s2)
# print(s2.difference(s1),s1.difference(s2))
# print(s2-s1,s1-s2)
# print(s1.symmetric_difference(s2))
# print(s1^s2)
# # 集合生成式 语法格式: {变量(可为变量表达式) for 变量名 in range()}
# s={i*i for i in range(6)}
# print(s)
# # ========字符串========
# # 驻留机制 仅保留一份相同且不可变的字符串方法 不同的值被存放在字符串的驻留池中 对相同的字符串只保留一份拷贝 创建已有值的对象时只把该地址赋给变量
# # 驻留机制的几种条件 字符串长度为0或1 符合标识符(字母数字下划线)的字符串 字符串只在编译时进行驻留而非运行 [-5,256]之间的整数数字
# a,b,c='Python',"Python",'''Python'''
# print(a,id(a),b,id(b),c,id(c))
# # 条件三 字符串只在编译时进行驻留而非运行
# str1='abc'
# str2='ab'+'c'
# str3=''.join(['ab','c'])
# print(str1 is str2)
# print(str1 is str3)
# print(str1,type(str1),'-----',str3,type(str3))
# # 强制驻留
# import sys
# str3=sys.intern(str1)
# print(str1 is str3)
# # 字符串操作
# # index()查找子串第一次出现的位置 不存在抛出异常 rindex()最后一次出现 抛异常
# # find()查找第一次出现的位置 不存在返回-1 rfind()最后一次出现 返回-1
# s='hello,hello'
# print(s.index('lo'),s.rindex('lo'),s.find('aaaa'))
# # upper()所有字符转大写 lower()所有字符转小写 swapcase()大小写互换 capitalize()第一位大写其余小写 title()每个单词的第一个大写其余小写
# s='hEllo baBy'
# print(s.upper())
# print(s.lower())
# print(s.swapcase())
# print(s.capitalize())
# print(s.title())
# # 字符串对齐 center(指定宽度,指定填充符 默认为空)居中对其 ljust(宽,填)左对齐 rjust()右对齐 zfill(指定宽度)右对齐 左边用0填充
# s='hello Python'
# print(s.center(20,'*'))
# print(s.ljust(5,'@'))
# print(s.rjust(20,'@'))
# print('-8910'.zfill(8))
# # split(sep='指定分隔符',maxsplit='指定最大分割次数')从左边开始分割 默认以空格为分割符 返回列表 rsplit()从右边开始分割
# s='hello|world|python|baby'
# print(s.split(sep='|',maxsplit=1))
# print(s.rsplit(sep='|',maxsplit=2))
# # isidentifier()判断字符串是不是合法标识符 isspace()判断字符串是否全由空白字符串组成 isalpha()判断是否由字母组成
# # isdecimal()判断字符串是否由十进制数字组成 isnumeric()判断是否由数字组成 isalnum()判断是否由字母和数字组成
# print('hello_python'.isidentifier())
# print(' '.isspace())
# print('as123456'.isalpha())
# print('0b132'.isdecimal())
# print('123345'.isnumeric())
# print('465sdaf'.isalnum())
# # replace('指定被替换的字串','指定替换字串的字符串'(,'最大替换次数')) join()将列表或元组中的字符串合并成一个字符串
# s='hella,pythan'
# print(s.replace('a','o'))
# lst=['hello','java','python']
# tuple1=('hello','c++','php')
# print('|'.join(lst))
# print(' '.join(tuple1))
# print('^'.join('python'))
# # ord()字符转ASCII chr()ASCII转字符
# print(ord('陈'))
# print(chr(38472))
# # 比较的区别 ==比较的是值 is比较的是id
# # 切片[start默认0:end默认最后位置:step默认1] 字符串是不可变序列 切片操作后产生的是新的字符串对象
# s='hello,python'
# s1,s2=s[:5],s[6:]
# print(s1,s2)
# print(s[::-1])
# print(s[-6:])
# # 格式化字符串 用%做占位符 或 用{}做占位符 或 f格式法
# name,age='张三',20
# print('我叫%s,今年%d岁' % (name,age))
# print('我叫{0},今年{1}岁'.format(name,age))
# print(f'我叫{name},今年{age}岁')
# # 编码和解码
# s='天涯共此时'
# byte1=s.encode(encoding='GBK') # 在GBK格式中一个中文占两个字节
# byte2=s.encode(encoding='UTF-8') # 在UTF-8格式中一个中文占三个字节
# print(byte1)
# print(byte2)
# print(byte1.decode(encoding='GBK'))
# # ========函数========
# # ----函数的创建----
# def calc(a,b=5): # 用del声明函数 a和b为函数形参 b=5声明默认值为5
# print('第一位参数为:',a,end=' ')
# print('第二位参数为:',b,end=' 结果为 ')
# return a+b
#
# num1,num2,num3=10,20,100
# print(calc(num1,num2))
# print(calc(num1))
# print(calc(b=num3,a=num1)) # 使用关键字参数后可以不需要按照形参顺序传值
# # ----函数的参数传递----
# # 不可变序列不会随着函数调用改变 可变序列会随着函数调用改变
# def fun(arg1,arg2):
# print('arg1=',arg1)
# print('arg2=',arg2)
# arg1=100
# arg2.append(10)
# print('arg1=',arg1)
# print('arg2=',arg2)
# print('调用完毕')
#
# n1=11
# n2=[22,33,44]
# print('n1=',n1)
# print('n2=',n2)
# print('调用函数传递参数')
# fun(n1,n2)
# print('n1=',n1)
# print('n2=',n2)
# # ----函数的返回值----
# # 函数可以没有返回值
# # 当函数返回一个值时 返回原数据类型
# # 当函数返回多个值时 返回对象为元组
# def fun(num):
# odd,even=[],[]
# for i in num:
# if i%2:
# odd.append(i)
# else:
# even.append(i)
# return odd,even
#
# print(fun([10,29,34,26,33,55,44]))
# # ----函数的参数定义----
# # 个数可变的位置参数 使用*定义 结果为一个元组 只能定义一个
# def fun1(*args):
# print(args)
#
# fun1(10)
# fun1(100,30,50)
# # 个数可变的关键字形参 使用**定义 结果为一个字典 只能定义一个
# def fun2(**args):
# print(args)
#
# fun2(a=10,b=20,v=50)
# # 当一个函数中既有位置参数又有关键字参数时 位置参数要放在关键字参数之前
# # 函数参数实例
# def fun(a,b,c):
# print('a=',a)
# print('b=',b)
# print('c=',c)
#
# lst=[11,22,33]
# fun(*lst) # 在函数调用时,将列表的每个元素都转换为位置实参传入
# dic={'a':111,'c':555,'b':333}
# fun(**dic) # 在函数调用时,将字典中的键值对都转换为关键字实参传入
# # 递归 斐波那契
# def fib(step):
# if len(lst_fi) != step:
# fib(step-1)
# lst_fi.append(lst_fi[step - 1] + lst_fi[step - 2])
#
# lst_fi=list([0,1,1])
# fib(9)
# print(lst_fi)
# # ======异常处理机制========
# # 常见异常类型: ZeroDivisionError:除0或取模0 IndexError:序列中无此索引 KeyError:映射中没有此键
# # NameError:未声明初始化对象 SyntaxError:语法错误 ValueError:传入无效参数 等等
# # try:(可能会抛出异常的代码) except 异常类型:(抛出异常处理代码) else:(未抛出异常处理代码) finally:(无论是否抛出异常都会执行的代码)
# try:
# n1=int(input('请输入一个整数:'))
# n2=int(input('请输入一个整数:'))
# result=n1/n2
# except BaseException as e:
# print('出错了:',e)
# else:
# print('结果为:',result)
# finally:
# print('程序结束')
# # Traceback模块 使用traceback打印异常信息 可以写入log日志
# import traceback
# try:
# print('*****************')
# num=10/0
# except:
# traceback.print_exc()
# # ========面向对象========
# # 类的创建
# class StudentInfo:
# native_place='山东' # 声明的类属性
# def __init__(self,name,age): # 声明一个类初始化方法
# self.name=name # self.属性名称为实例属性 进行赋值操作
# self.__age=age # __属性名只可以在类的内部被使用 (仍然靠自觉性遵守 可以靠 对象名._类名__属性名 强制访问)
# def eat(self): # 声明实例方法:被该类的所有对象所共享
# print(self.name+'同学在吃饭','在类的方法内部可以使用私有属性年龄',self.__age)
# def drink(self):
# print(self.name+'同学在喝水')
# @staticmethod # 声明静态方法的修饰声明:使用类名直接访问的方法
# def sm(): # 没有任何参数传入 故不能调用任何属性
# print('声明了一个静态方法,不能调用任何属性')
# @classmethod # 声明类方法的修饰声明:使用类名直接访问的方法
# def cm(cls): # 传入了class参数 故可以调用类属性 但不可调用实例属性
# print('声明了一个类方法,可以调用类属性,但不可调用实例属性:'+cls.native_place)
#
# # 对象创建和对象操作
# stu1=StudentInfo('张三',20)
# stu2=StudentInfo('李四',18)
# stu1.eat() # 对象名.方法名() == 类名.方法名(对象)
# StudentInfo.drink(stu2) # 类名.方法名(对象) == 对象名.方法名()
# StudentInfo.sm() # 类名.静态方法名
# StudentInfo.cm() # 类名.类方法名
# print(StudentInfo.native_place) # 类名.类属性名 == 对象名.类属性名
# print(stu1.native_place) # 对象名.类属性名 == 类名.类属性名
# print(stu1.name) # 对象名.实例属性名
# # 为对象动态绑定指定属性
# stu2.gender='女' # 只有stu2有gender这个实例属性 而 stu1没有
# print(stu2.name,stu2.gender)
# # 为对象动态绑定方法
# def show():
# print('定义在类之外的函数')
# stu1.show=show # 只有stu1有show这个实例方法 而 stu2没有
# stu1.show()
# del stu1,stu2
# # 类的继承 重写
# # class 子类类名 (父类1,父类2...): object是所有类的父类(默认继承)
# class Person(object): # 定义一个父类
# def __init__(self,name,age):
# self.name=name
# self.age=age
# def info(self):
# print('姓名:{0},年龄:{1}'.format(self.name,self.age))
# def polymorphism(self):
# print('用于介绍重写的方法')
#
# class Student(Person): # 定义一个子类
# def __init__(self,name,age,score):
# super().__init__(name,age) # 直接调用父类的初始化方法
# self.score=score
# def polymorphism(self): # 重写了Person类的polymorphism方法
# super().polymorphism() # 仍然可以调用父类的polymorphism方法
# print('Student类重写polymorphism方法')
#
# stu=Student('张三',20,100)
# stu.info() # 子类继承了父类的方法和属性
# stu.polymorphism() # 子类可以重写父类的方法
# del stu
# 常用的类的特殊属性和特殊方法
# 特殊属性 __dict__:获得类对象或实例对象所绑定的所有属性和方法的字典 __class__:获得类所属的类型 __bases__:获取父类列表
# __mro__:获取类的继承层次 __subclasses__:获取子类列表
# 特殊方法 __add__():定义+操作的方法 __len__():定义计算长度的方法 __new__():定义创建对象的方法 __init__():初始化 __str__():返回一个对象的描述信息
# # ========浅拷贝与深拷贝========
# # 浅拷贝只向下拷贝一层
# # 深拷贝会递归的完全拷贝每一层
# # ========模块========
# # 每个.py的文件都可以认作一个模块 导入的包也都是模块
# 导入模块 import 模块名称 (as 别名) from 模块名称 import 函数/变量/类
# import math # 数学运算模块
# print(id(math),type(math),math)
# print(math.pi)
#
# from math import pi
# print(pi)
# # 自定义模块 不能于python自带模块重名 新建test_module.py
# import test_module as module
# print(module.add(100,500))
# # ========包========
# # 每个python程序可由多个包组成
# # 每个包可由多个模块组成 避免了不同作用的模块重名的冲突
# # 包与目录的区别是 包中包含了一个__init__.py的文件
# # 导入不同包中的模块 import 包名.模块名 (as 别名) from 包名.模块名 import 函数/变量/类
# import package1.pack_module as pmod
# pmod.package_fun()
# # 常用的一些模块和包
# # sys:与python解释器及环境操作相关的标准库 time:与时间相关的各种函数的标准库 os:访问操作系统服务功能的标准库
# # calendar:与日期相关的各种函数的标准库 urllib:用于读取来自服务器的数据标准库 json:用于使用JSON序列化和反序列化对象
# # re:在字符串中执行正则表达式匹配和替换 math:标准算数运算函数的标准库 decimal:精确控制运算精度 有效位数 四舍五入的十进制运算
# # logging:提供了灵活的记录事件 错误 警告 调试信息等日志信息的功能
# # 第三方模块的安装及使用
# # 安装 打开cmd 输入pip install 模块名
# # 使用 import 模块名
# # ========文件========
# # 内置函数open()创建文件对象 文件对象名=open( 文件名称 (,打开模式默认只读,编码格式默认gbk) )
# file=open('text.txt')
# print(file.readlines())
# file.close()
# # 常用的文件打开模式 r只读 读指针会放在开头 w只写 若文件不存在则创建 若文件存在则覆盖内容 a追加 若文件不存在则创建 若存在则在末尾追加
# # b以二进制打开文件 不能单独使用 一般rb wb +以读写方式打开 不能单独使用 一般a+
# # 文件对象常用方法 read() readline() readlines() write() writelines() seek() tell() flush() close()
# # 上下文管理器with
# # 可以自动管理上下文资源 不论什么原因跳出with块 都能确保文件正常关闭 释放资源
# with open('text.txt','r') as file:
# print(file.read())
# # 解释with的处理机制
# class MyContentMgr():
# def __enter__(self):
# print('enter方法被调用执行了')
# return self
# def __exit__(self, exc_type, exc_val, exc_tb):
# print('exit方法被调用执行了')
# def show(self):
# print('show方法被调用执行了')
#
# with MyContentMgr() as file:
# file.show()
text_module.py
# coding:utf-8
# author:ChenBaijing
# date:2022/4/4 21:22
def add(a,b):
print('正在运行test_module模块的add方法')
return a+b
# 只有当test_module.py以主程序方式运行时才会打印以下语句
if __name__ == '__main__':
print('test_module.py正在以主程序方式运行')pack_module.py
# coding:utf-8
# author:ChenBaijing
# date:2022/4/4 22:05
def package_fun():
print('正在运行package1包中的pack_module模块的方法')text.txt
helloworld
python
java


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









