







使用resnext50网络模型 预训练+全连接层微调
交叉熵损失 + Adam优化器
数据增广:随机水平翻转+随机上下翻转+随机调整图片亮度、饱和度、色温
transform = transforms.Compose([
transforms.Resize((self.resize_height, self.resize_weight)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.ColorJitter(brightness=0.2,saturation=0.1,hue=0.1),
transforms.ToTensor()
])| 图片大小 | 224x224 |
| 类别数量 | 176 |
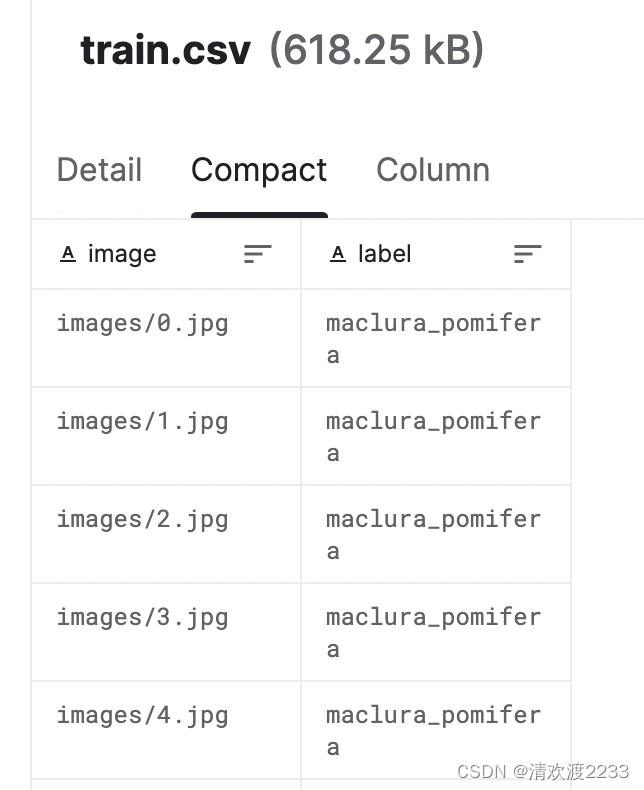
| 训练集数量 | 18353 |
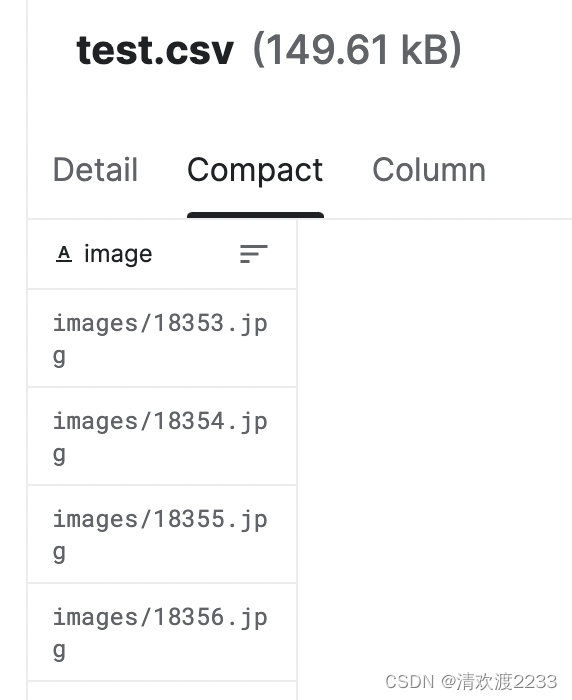
| 测试集数量 | 8800 |
训练集格式: 测试集格式:
代码:
import pandas as pd
import torch
import torch.nn as nn
import numpy as np
import torchvision
from tqdm import tqdm
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from PIL import Image
# 判断device
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 一些文件位置
train_csv_path = 'classify-leaves/train.csv'
test_csv_path = 'classify-leaves/test.csv'
submission_path = 'classify-leaves/sample_submission.csv'
img_dir_path = 'classify-leaves/'
model_path = 'pre_res_model. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









