










学习storm入门的例子,100%可运行
源码下载地址:http://download.csdn.net/download/adam_zs/9961426
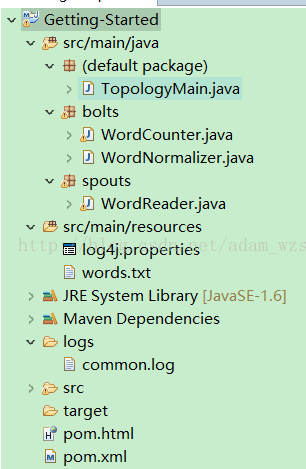
TopologyMain.java
import spouts.WordReader;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.topology.TopologyBuilder;
import backtype.storm.tuple.Fields;
import bolts.WordCounter;
import bolts.WordNormalizer;
/**
* @title: 创建拓扑 <br/>
* @author: wangzs <br/>
* @date: 2017年9月2日
*/
public class TopologyMain {
public static void main(String[] args) throws InterruptedException {
// 定义拓扑: TopologyBuilder 将用来创建拓扑,它决定 Storm 如何安排各节点,以及它们交换数据的方式。
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("word-reader", new WordReader());
builder.setBolt("word-normalizer", new WordNormalizer()).shuffleGrouping("word-reader");
builder.setBolt("word-counter", new WordCounter(), 2).fieldsGrouping("word-normalizer", new Fields("word"));
// 在 spout 和 bolts 之间通过 shuffleGrouping 方法连接。这种分组方式决定了 Storm 会以随机分配方式从源节点向目标节点发送消息。
// 配置: 创建一个包含拓扑配置的 Config 对象,它会在运行时与集群配置合并,并通过prepare 方法发送给所有节点。
Config conf = new Config();
conf.put("wordsFile", "E:/wangzsAi/Getting-Started/src/main/resources/words.txt");
conf.setDebug(false);
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 1);
// 运行拓扑: 调用 createTopology 和 submitTopology,运行拓扑,休眠两秒钟(拓扑在另外的线程运行),然后关闭集群。
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("Getting-Started-Toplogie", conf, builder.createTopology());
Thread.sleep(1000);
cluster.shutdown();
}
}
WordReader.java
package spouts;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.util.Map;
import backtype.storm.spout.SpoutOutputCollector;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseRichSpout;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Values;
/**
* @title: WordReader负责从文件按行读取文本,并把文本行提供给第一个 bolt。 <br/>
* @author: wangzs <br/>
* @date: 2017年9月2日
*/
public class WordReader extends BaseRichSpout {
private static final long serialVersionUID = 8659118943517689911L;
private SpoutOutputCollector collector;
private FileReader fileReader;
private boolean completed = false;
/**
* 第一个被调用的spout方法都是open,我们将创建一个文件并维持一个collector对象
*
* @param conf
* 配置对象,在定义topology对象是创建
* @param context
* TopologyContext对象,包含所有拓扑数据
* @param collector
* 能让我们发布交给 bolts 处理的数据
*/
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
try {
this.fileReader = new FileReader(conf.get("wordsFile").toString());
} catch (FileNotFoundException e) {
throw new RuntimeException("Error reading file [" + conf.get("wordFile") + "]");
}
this.collector = collector;
}
/**
* 我们要通过nextTuple向 bolts 发布待处理的数据。在这个例子里,这个方法要读取文件并逐行发布数据。
*/
public void nextTuple() {
/**
* 这个方法会不断的被调用,直到整个文件都读完了,我们将等待并返回。
*/
if (completed) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
return;
}
String str;
BufferedReader reader = new BufferedReader(fileReader);
try {
while ((str = reader.readLine()) != null) {
/**
* 按行发布一个新值
*/
this.collector.emit(new Values(str), str); // Values 是一个 ArrarList 实现,它的元素就是传入构造器的参数。
}
} catch (Exception e) {
throw new RuntimeException("Error reading tuple", e);
} finally {
completed = true;
}
}
// nextTuple() 会在同一个循环内被 ack() 和 fail() 周期性的调用。
public void ack(Object msgId) {
System.out.println("OK:" + msgId);
}
public void fail(Object msgId) {
System.out.println("FAIL:" + msgId);
}
/**
* 声明输入域"line"
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("line"));
}
}
WordNormalizer.java
package bolts;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Fields;
import backtype.storm.tuple.Tuple;
import backtype.storm.tuple.Values;
/**
* @title: 第一个 bolt,WordNormalizer,负责得到并标准化每行文本。它把文本行切分成单词,大写转化成小写,去掉头尾空白符。 <br/>
* @author: wangzs <br/>
* @date: 2017年9月2日
*/
public class WordNormalizer extends BaseBasicBolt {
private static final long serialVersionUID = 751105854423231360L;
/**
* bolt最重要的方法execute(),每次接收到元组时都会被调用一次,还会再发布若干个元组 <br/>
* bolt从单词文件接收到文本行,并标准化它。 文本行会全部转化成小写,并切分它,从中得到所有单词。
*/
public void execute(Tuple input, BasicOutputCollector collector) {
String sentence = input.getString(0);
String[] words = sentence.split(" ");
for (String word : words) {
word = word.trim();
if (!word.isEmpty()) {
word = word.toLowerCase();
// 发布这个单词
collector.emit(new Values(word));
}
}
}
/**
* 声明 bolt 的出参,这里我们声明 bolt 将发布一个名为 “word” 的域。
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
WordCounter.java
package bolts;
import java.util.HashMap;
import java.util.Map;
import backtype.storm.task.TopologyContext;
import backtype.storm.topology.BasicOutputCollector;
import backtype.storm.topology.OutputFieldsDeclarer;
import backtype.storm.topology.base.BaseBasicBolt;
import backtype.storm.tuple.Tuple;
public class WordCounter extends BaseBasicBolt {
private static final long serialVersionUID = -2795932943749903797L;
Integer id;
String name;
Map<String, Integer> counters;
/**
* 初始化
*/
@Override
public void prepare(Map stormConf, TopologyContext context) {
this.counters = new HashMap<String, Integer>();
this.name = context.getThisComponentId();
this.id = context.getThisTaskId();
}
/**
* 为每个单词计数
*/
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
String str = input.getString(0);
/**
* 如果单词尚不存在于map,我们就创建一个,如果已在,我们就为它加1
*/
if (!counters.containsKey(str)) {
counters.put(str, 1);
} else {
Integer c = counters.get(str) + 1;
counters.put(str, c);
}
}
/**
* 这个拓扑结束时(cleanup() 方法被调用时),我们将显示每个单词的数量。
*/
@Override
public void cleanup() {
System.out.println("-- Word Counter [" + name + "-" + id + "] --");
for (Map.Entry<String, Integer> entry : counters.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
输出结果:
OK:storm
OK:test
OK:are
OK:great
OK:an
OK:storm
OK:but
OK:really
OK:is
OK:StOrm
OK:simple
OK:application
OK:very
OK:powerfull
OK:
OK:is
OK:great
-- Word Counter [word-counter-2] --
very: 1
test: 1
application: 1
are: 1
is: 2
simple: 1
powerfull: 1
-- Word Counter [word-counter-1] --
but: 1
storm: 3
great: 2
an: 1
really: 1















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









