







项目源码下载:http://download.csdn.net/download/adam_zs/10166641
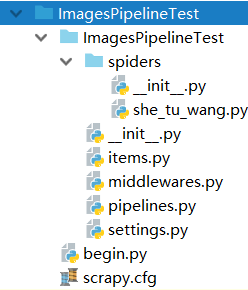
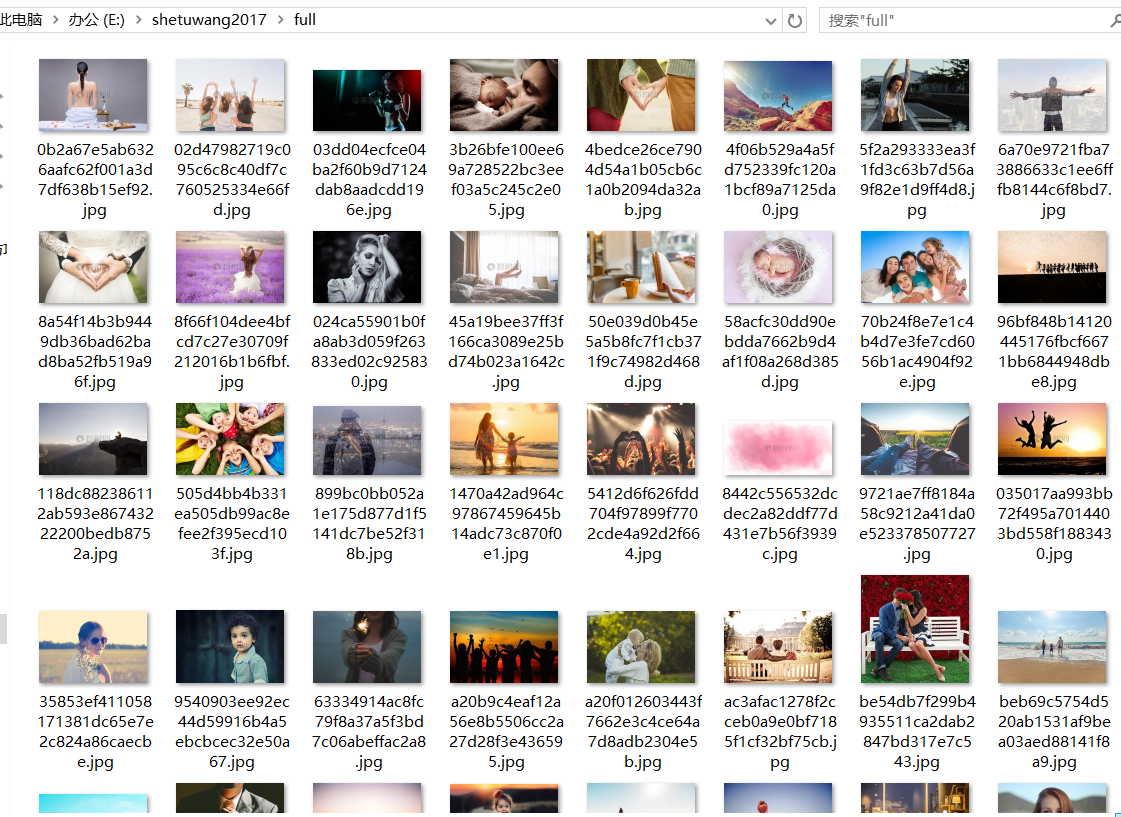
1.项目结构,下载图片截图
2.项目简介
settings.py
ITEM_PIPELINES = {
# 'scrapy.pipelines.images.ImagesPipeline': 1
"ImagesPipelineTest.pipelines.MyImagesPipeline":1
}
IMAGES_STORE = 'E:\\shetuwang2017'items.py
import scrapy
class ImageItem(scrapy.Item):
image_urls = scrapy.Field()
images = scrapy.Field()
# image_urls和images是固定的
she_tu_wang.py
# -*- coding: utf-8 -*-
import scrapy
from ImagesPipelineTest.items import ImageItem
class XiaohuaSpider(scrapy.Spider):
name = "shetuwang"
allowed_domains = ["699pic.com"]
start_urls = ['http://699pic.com/people.html']
download_delay = 2
def parse(self, response):
item = ImageItem()
srcs = response.xpath('//div[@class="swipeboxEx"]/div[@class="list"]/a/img/@data-original').extract()
item['image_urls'] = srcs
yield item
pipelines.py
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem
from scrapy.http import Request
class MyImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image_urls']:
yield Request(image_url)
def item_completed(self, results, item, info):
image_path = [x['path'] for ok, x in results if ok]
if not image_path:
raise DropItem('Item contains no images')
item['image_paths'] = image_path
return item
3.运行项目
pycharm中运行begin.py
from scrapy import cmdline
# cmdline.execute("scrapy crawl dmoz".split())
cmdline.execute("scrapy crawl shetuwang".split())














 5911
5911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









