







🌵爬虫系列之Scrapy框架
🌱本文章只用于技术交流,商用请移步
🍀欢迎大家关注~
🌴博主还在学习中,如有错误还望大家提出😜
目录

🌴前言
今天让我们来学习一下Scrapy框架的图片下载器(pipeline的一个包)——ImagePipeline。大家都知道Scrapy框架下载数据的效率,但对于图片的下载就不是很好使用,所以Scrapy就推出了ImagePipeline。如何使用它呢?其实很简单,看完这篇文章你肯定能秒懂😉
🍉思路
🍄 创建项目
哈哈,第一步当然是创建项目了~
1.scrapy startproject 项目名称
2.scrapy genspider 网站域名 爬虫项目名称
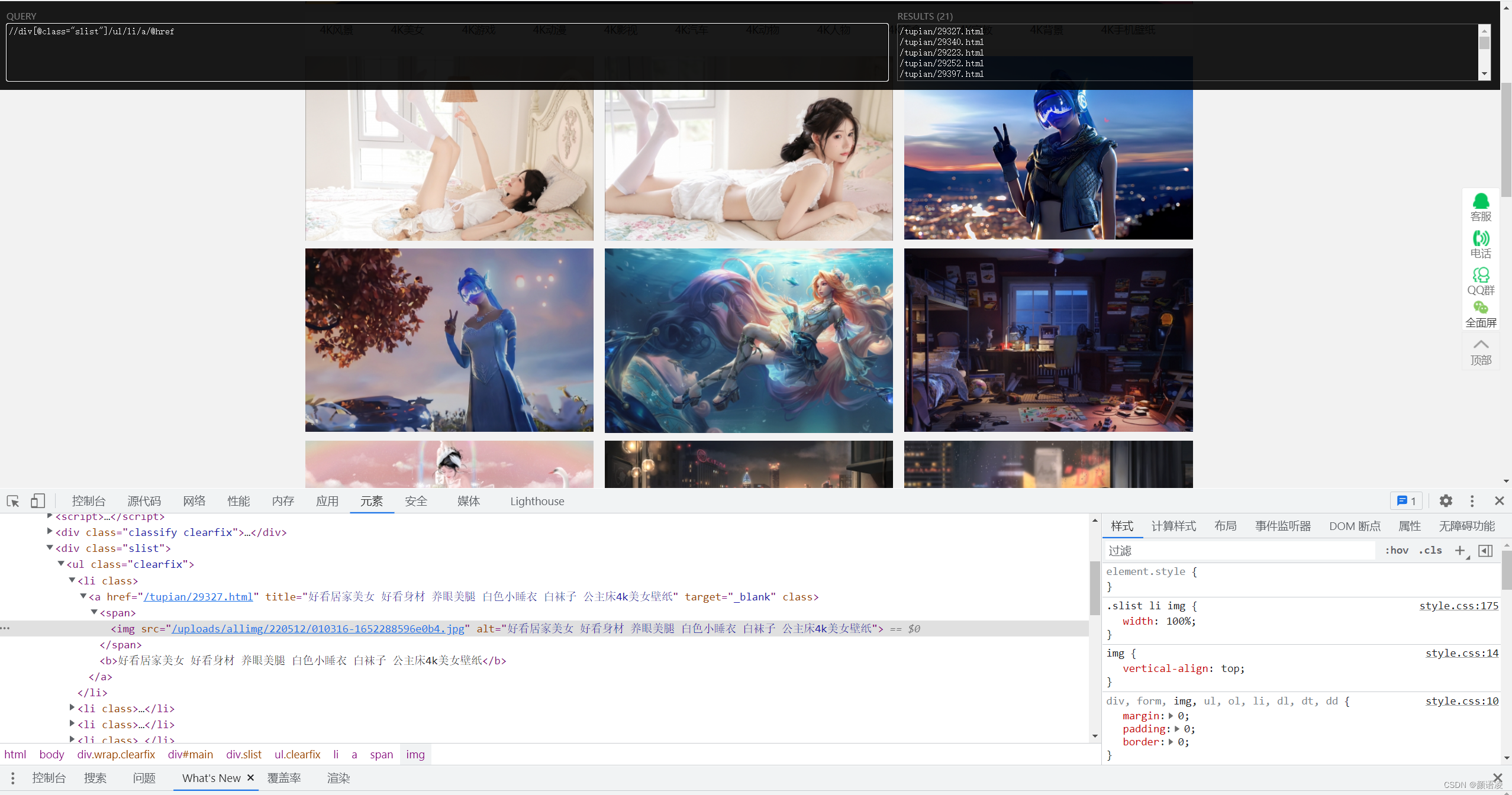
🍄 网页分析
对网页进行分析,找到图片链接在源码中的位置,写出图片链接xpath(本文主要用xpath)表达式~
🍄 编写spider文件及设置
编写spider文件以及对setting文件进行设置(都是固定的步骤),这里讲一下我们setting文件中要添加一个图片保存文件路径(新建一个你要保存图片的文件夹)
#imagepipline的下载保存地址 IMAGES_STORE = 'D:/imagephoto'
🍄 改写pipeline.py
改写pipeline.py,我们要用ImagePipeline下载图片,所以我们要改pipeline.py文件

Ctrl + 点击进入ImagePipeline包(它是pipelines.image下的封装的包)

这个是ImagePipeline下的一个函数主要功能是对我们爬虫获取的url图片链接进行请求结果给到我们的file_path()进行下一步的处理

将get_media_requests()的结果保存为jpg,下面我对这个函数进行了修改加入了图片的标题。
🍉项目实战
🌵编写spider.py
分析网页得到了图片的链接,对多页如何处理呢?我们必须定位页码的位置,每获取完一页的数据就需要进行翻页处理。由于版权问题爬虫文件无法展示
🌵编写items.py
import scrapy
class ImagesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
image = scrapy.Field()我们要把图片和图片对应的标题保存下来 ~
🌵编写pipeline.py(文章核心)
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
from scrapy.http import Request
from loguru import logger
class FTPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['image']:
logger.info(item['title']) #在控制台打印出标题
yield Request(image_url,meta={'title':item['title']}) #传参
def file_path(self, request, response=None, info=None, *, item=None):
#对图片的名称进行处理
image_guid = request.url.split('.')[-1]
name = request.meta['title']
filename = '{0}.{1}'.format(name, image_guid)
return filename从pipeline.image中导入ImagePipeline包,对图片下载~
🍉成果展示

🍉结束

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











