







目录
背景
迁移学习中目标域和源域数据之间存在分布差异,这个差异不仅仅有边界分布差异,也可能是条件分布差异,更多的可能是二者同时存在。确立哪种分布对数据的影响更大,对应的调节网络参数,可以更好的调节源域与目标域之间的领域差异大小,以此实现更好的迁移效果。
不同的分布之间的差异如图所示:
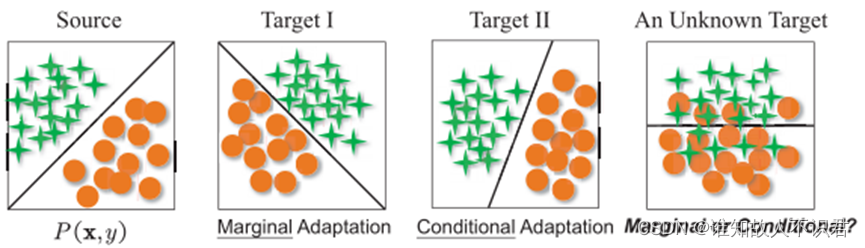
传统方法
传统的基线对抗网络模型DANN,针对边际分布差异较大的情况下,效果会比较好。然而它对于域内子类,即域内的类别与其他域内同类别样本的边界判断效果并不好。基于此,一般我们会引入条件分布,但一般数据间的迁移,二者的分布差异都有的。如何调整二者之间的分布权重,成为了新的研究问题。
论文中提到MEDA方法虽然旨在自适应对齐两种分布。但它存在以下问题。
(1)需要训练c+1个额外线性分类器,这既昂贵又耗时。
(2)它只能适应小的数据集
(3)且由于每次都要计算所有样本的伪逆,所以无法在线部署。
关于传统的DANN方法可以看我的博客:
深度对抗神经网络(DANN)笔记_谁知故人不识君的博客-CSDN博客
MEDA论文地址:
DAAN
DAAN (Dynamic Adversarial Adaptation Network)一种可以动态调整边界和条件分布关系的深度对抗网络模型,它的基础网络与DANN网络基本一致,核心在于引入了条件域判别块和集成化的动态调节因子ω,下面是DANN网络结构图与DAAN的网络结构图。
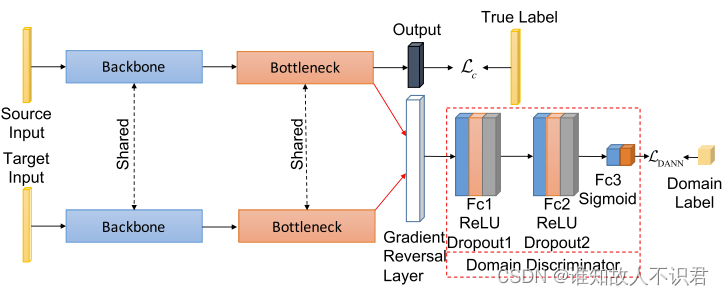
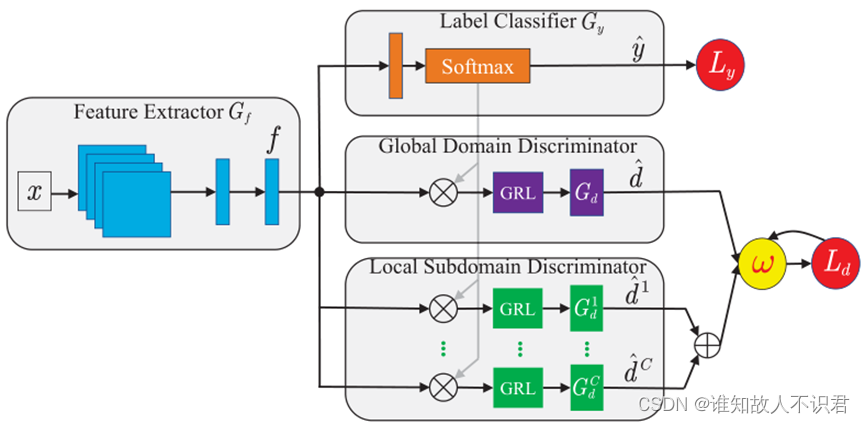
代码介绍
from loss_funcs.adv import *
class DAANLoss(AdversarialLoss, LambdaSheduler):
def __init__(self, num_class, gamma=1.0, max_iter=1000, **kwargs):
super(DAANLoss, self).__init__(gamma=gamma, max_iter=max_iter, **kwargs)
self.num_class = num_class
###子域判别器,加入条件对抗判别器
self.local_classifiers = torch.nn.ModuleList()
for _ in range(num_class):
self.local_classifiers.append(Discriminator())
self.d_g, self.d_l = 0, 0
self.dynamic_factor = 0.5
### 动态调节因子dynamic_factor
###需要源域和目标域经过分类器预测的source_logits和target_logits作为BCELOSS的输入求出源域的全局损失和local 损失,目标域也是如此。最后计算得出源域和目标域的全局损失和local损失。
def forward(self, source, target, source_logits, target_logits):
lamb = self.lamb()
self.step()
source_loss_g = self.get_adversarial_result(source, True, lamb)
target_loss_g = self.get_adversarial_result(target, False, lamb)
source_loss_l = self.get_local_adversarial_result(source, source_logits, True, lamb)
target_loss_l = self.get_local_adversarial_result(target, target_logits, False, lamb)
global_loss = 0.5 * (source_loss_g + target_loss_g) * 0.05
local_loss = 0.5 * (source_loss_l + target_loss_l) * 0.01#得到的值是所有类的总和,最后要除类总数,得到一个子类loss的平均值
#源域和目标域比例是1:1,所以总数×0.5
self.d_g = self.d_g + 2 * (1 - 2 * global_loss.cpu().item())#定义全局A距离
self.d_l = self.d_l + 2 * (1 - 2 * (local_loss / self.num_class).cpu().item())
#err(h)表示的是平均值
adv_loss = (1 - self.dynamic_factor) * global_loss + self.dynamic_factor * local_loss
"""
adv_loss = (1 - self.dynamic_factor) * global_loss + self.dynamic_factor * local_loss
self.dynamic_factor 全局w动态平衡参数
"""
return adv_loss
### adv_loss 是新的域判别器损失
def get_local_adversarial_result(self, x, logits, c, source=True, lamb=1.0):
loss_fn = nn.BCELoss()
x = ReverseLayerF.apply(x, lamb)#这个x是输入类判别器中的特征值
loss_adv = 0.0
for c in range(self.num_class):
logits_c = logits[:, c].reshape((logits.shape[0],1))
# (B, 1)
features_c = logits_c * x
domain_pred = self.local_classifiers[c](features_c)
#第几个分类器,使用这一类的特征数据
device = domain_pred.device
if source:
domain_label = torch.ones(len(x), 1).long()
else:
domain_label = torch.zeros(len(x), 1).long()
loss_adv = loss_adv + loss_fn(domain_pred, domain_label.float().to(device))
return loss_adv
#更新动态调节因子w的函数
def update_dynamic_factor(self, epoch_length):
if self.d_g == 0 and self.d_l == 0:
self.dynamic_factor = 0.5
"""
初始化参数的条件
"""
else:
self.d_g = self.d_g / epoch_length#平均值
self.d_l = self.d_l / epoch_length
self.dynamic_factor = 1 - self.d_g / (self.d_g + self.d_l)#原论文是后面为w
self.d_g, self.d_l = 0, 0与之对应的相关公式可以查看论文的第三部分。
文章仅供初步了解,代码来自王晋东老师的开源代码库,只截取了比较关键的对抗损失函数部分,具体学习可以关注王晋东老师的开源代码库。
最后希望本文能对您学习深度迁移学习有所帮助,欢迎评论区沟通交流,互相学习。
论文地址:
开源代码库地址:

















 1838
1838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









