






最近在准备gee学习室的暑假课程,在筹备基础课程内容的时候,发现了一个之前没有注意到的问题,其中主要涉及一个函数,这个函数的功能存在一定的缺陷,其主要问题是运行速度慢、效率低,这一缺陷(几乎)影响99%的用户。
这个函数就是sampleRegions。这个sampleRegions函数的使用说明如下。很显然,sampleRegions函数的功能就是:将与一个或多个区域相交的图像中的每个像素(在给定的比例尺下)转换为一个要素,返回一个要素集合(FeatureCollection)。每个输出要素将拥有一个输入图像中每个波段的属性,以及从输入要素中复制的任何指定属性。也就是说,sampleRegions函数实现了对影像数据进行采样,从而得到了一个FeatureCollection。

表面上看似乎没有什么问题,而且很多官方代码或者网络上流传的代码都在使用这个函数。但是最近在测试的时候,我们发现这个sampleRegions函数运行效率比较差,尤其是针对大样本数据的时候会出现这一问题。下面就用具体例子来说明这个问题。
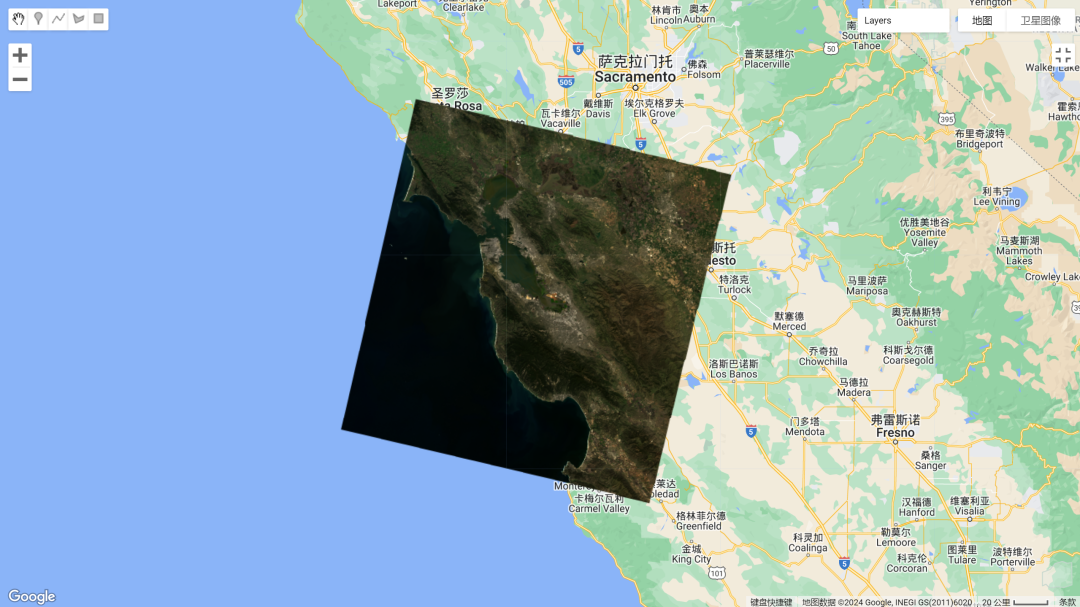
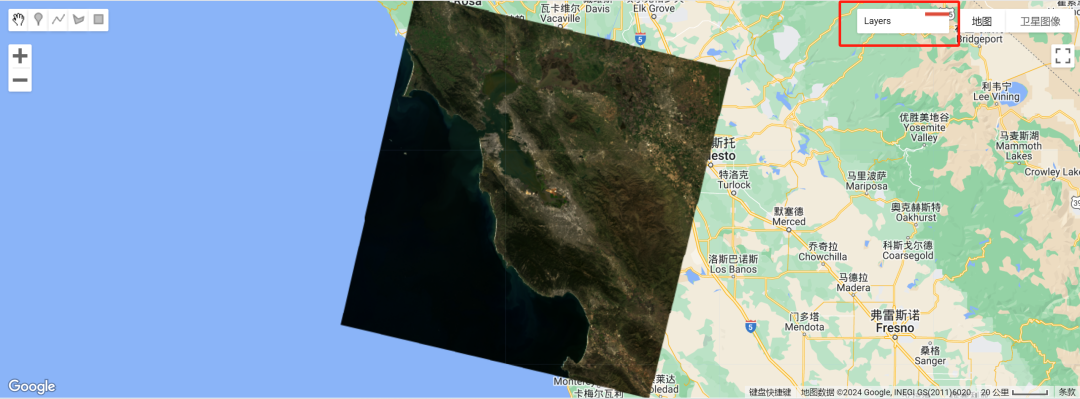
假设我们对下面的Landsat影像数据进行采样操作,也就是希望得到featureCollection特征点集合。我们第一次尝试总共有接近13000个样本点,也就是下图所示(密密麻麻分不清具体点的哈)。
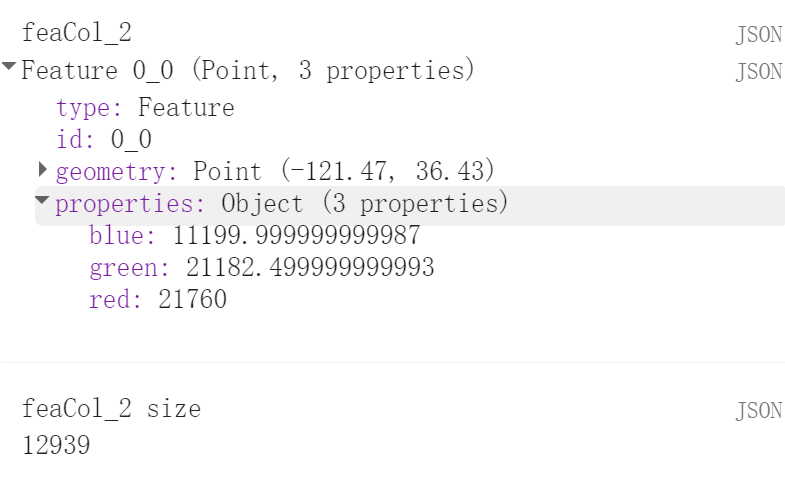
我们使用sampleRegions函数来采样数据,会得到下面的结果。也就是说,在三个波段情况下,是可以采样得到近13000个样本点的数据的。这一点还是很好的。
接下来,我们上点难度。这次我们想一下子采集28万条样本数据,但是我们会得到下面的结果,想加载的样本数据也不能显示。而且这是等待了好久才出现的报错。我相信很多人都遇到过这个情况,这也是大家都最不想遇到的情况。
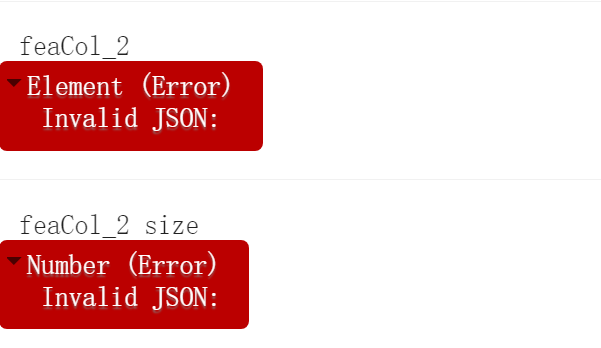
这个例子就充分说明sampleRegions函数在处理大数据的时候能力是有限的,而这一有限的处理能力则会影响到(几乎)99%的用户。
那么,有没有解决办法呢?当然有了,具体解决思路请听下回分解,或者在交流群找到解决方案。
交流合作/加入我们
geeAI前沿哨是一群具有摄影测量与遥感和计算机等专业背景的高校博士生(含在读和已毕业)创办的用于分享科学前沿动态、专注智能计算和数据的平台。该平台主要结合Google Earth Engine(GEE)云平台和人工智能(AI)技术,实现对地理空间数据的高效处理和智能分析。截至目前,已经有好几千人参加了本平台的学习课程等,其中报名的会员人数已经超过400+,协助学员发表SCI一区/二区高级别论文20篇以上。
此外,geeAI前沿哨创建了多个学习交流群,交流群成员来自各地高校和研究所,涵盖本科、硕士、博士和老师群体,可以在交流群交流讨论、积极碰撞、找到共同研究兴趣的“科研搭子”以及下载各种学术论文等。
想加入交流群的同学可加小编微信让其邀请进群(扫描下方二维码咨询报名或菜单栏“联系我们”选项框都可以找到小编哟)。注意,咨询加群验证信息请备注为“学位-研究方向-学校-加群”格式,否则不予通过。例如,假如你是武汉大学土地利用分类方向的博士研究生,则可以备注“博士-LULC-武大-加群”;假如你是北京大学生态学方向的硕士研究生,则可以备注“硕士-生态学-北大-加群”。

如果有帮助,点赞或者关注一下呗















 4160
4160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









