







1. promethues 介绍
1.1 监控的分类
监控重要性由高到低
1. 业务监控:
公司领导比较关心的指标,如电商平台的订单数量,用户的日活等
2. 系统监控:
主要是跟操作系统相关的基本监控项,比如CPU,内存,硬盘,IO,TCP链接,流量等等
3. 网络监控:
对网络状态的监控(交换机,路由器,防火墙,VPN等),互联网公司必不可少,但是很多时候又被忽略,例如:IDC机房内网之间,外网之间的丢包率,延迟等等。
4. 日志监控:
监控中的重头戏,往往单独设计和搭建,全部种类的日志都有需要采集,常见的解决方案如Elstic stack(有免费版),Splunk(付费版)等。
5. 程序监控:
一般需要和开发人员配合,程序中嵌入各种接口,直接获取数据或者特质的日志格式。
1.2 promethues 优点
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。
相比于传统监控系统Prometheus具有以下优点:
(1)易于管理
Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
Prometheus基于Pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统。对于一些复杂的情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
(2)监控服务的内部运行状态
Pometheus鼓励用户监控服务的内部状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
(3)时间序列(time series)
所谓的时间序列(time series)指的是一系列有序的数据,通常是指等时间间隔的采样数据,说白了就是分为X和Y轴,其中X轴是按照时间间隔进行推进,而Y轴是有序的数字。
(4)强大的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。
(5)强大的查询语言PromQL
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
通过PromQL可以轻松回答类似于以下问题:
1>.在过去一段时间中95%应用延迟时间的分布范围?
2>.预测在4小时后,磁盘空间占用大致会是什么情况?
4>.CPU占用率前5位的服务有哪些?(过滤)
(6)高效
对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而Prometheus可以高效地处理这些数据,对于单一Prometheus Server实例而言它可以处理:数以百万的监控指标和每秒处理数十万的数据点。而zabbix对此相对来说就有点吃力了;
(7)可扩展(支持集群)
Prometheus是如此简单,因此你可以在每个数据中心、每个团队运行独立的Prometheus Sevrer。
Prometheus对于联邦集群的支持,可以让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)可以对其进行扩展。
(8)易于集成
使用Prometheus可以快速搭建监控服务,并且可以非常方便地在应用程序中进行集成。目前支持: "Java","JMX","Python","Go","Ruby",".Net", "Node.js"等等语言的客户端SDK,基于这些SDK可以快速让应用程序纳入到Prometheus的监控当中,或者开发自己的监控数据收集程序。同时这些客户端收集的监控数据,不仅仅支持Prometheus,还能支持Graphite这些其他的监控工具。
同时Prometheus还支持与其他的监控系统进行集成:"Graphite", "Statsd", "Collected", "Scollector", "muini", "Nagios"等。
Prometheus社区还提供了大量第三方实现的监控数据采集支持:"JMX", "CloudWatch", "EC2","MySQL","PostgresSQL", "Haskell", "Bash", "SNMP", "Consul", "Haproxy", "Mesos", "Bind", "CouchDB", "Django", "Memcached", "RabbitMQ", "Redis", "RethinkDB", "Rsyslog"等等。
(9)可视化
Prometheus Server中自带了一个Prometheus UI,通过这个UI可以方便地直接对数据进行查询,并且支持直接以图形化的形式展示数据。
同时Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案Promdash。
最新的Grafana可视化工具也已经提供了完整的Prometheus支持,基于Grafana可以创建更加精美的监控图标。基于Prometheus提供的API还可以实现自己的监控可视化UI。
(10)开放性
通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持。因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制。对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于Prometheus来说,使用Prometheus的client library的输出格式不止支持Prometheus的格式化数据,也可以输出支持其它监控系统的格式化数据,比如Graphite。
因此你甚至可以在不使用Prometheus的情况下,采用Prometheus的client library来让你的应用程序支持监控数据采集。
Prometheus除了上述说到的优点,其实也有以下不足之处:
(1)学习成本太大,尤其是其独有的数学命令行,学习起来很吃力,而且全是英文文档;
(2)对磁盘资源也是耗费的较大,这个具体要看监控的集群量和监控项的多少和保存时间的长短;
(3)有网友称在1.x版本中可能会发生数据丢失的风险,因此生产环境中建议大家使用较新的2.x发行版;
温馨提示:
(1)zabbix采用的是MySQL数据库,Prometheus采用的是时间序列数据库,由于监控数据并不需要更新,监控数据会存在大量的写入和查询,其底层实现会更高,具体细节原理可自行查阅资料,Prometheus是支持外部数据库存储的,但我觉得完全没有必要在生产环境中这样做;
(2)如果上述10点还不足以打动你学习Prometheus,那我再说一点比较现实的,国内目前很多中小企业都在使用Prometheus监控docker,Kubernetes,学习它有助于咱们找工作。
1.3 promethues 使用场景
适用的场景(When does it fit?)
Prometheus适用于记录任何纯数字时间序列。它既适合以机器为中心的监控,也适合监控高度动态的面向服务的架构。在微服务的世界中,它对多维数据收集和查询的支持是一个特殊的优势。
Prometheus是为可靠性而设计的,它是您在中断期间访问的系统,让您能够快速诊断问题。每个 Prometheus服务器都是独立的,不依赖于网络存储或其他远程服务。当基础架构的其他部分损坏时,您可以依赖它,并且您无需设置大量基础架构即可使用它。(请记住该点,这是优点也是缺点哟~)
不适用的场景(When does it not fit?)
如上所示,Prometheus重视可靠性。即使在出现故障的情况下,您也可以随时查看有关系统的可用统计信息。
如果您需要100%的准确性,例如按请求计费,Prometheus不是一个好的选择,因为收集的数据可能不够详细和完整。在这种情况下,您最好使用其他系统来收集和分析计费数据,并使用Prometheus进行其余的监控。
推荐阅读:
https://prometheus.io/docs/introduction/overview/#when-does-it-fit
https://prometheus.io/docs/introduction/overview/#when-does-it-not-fit
1.4 promethues 宏观架构图
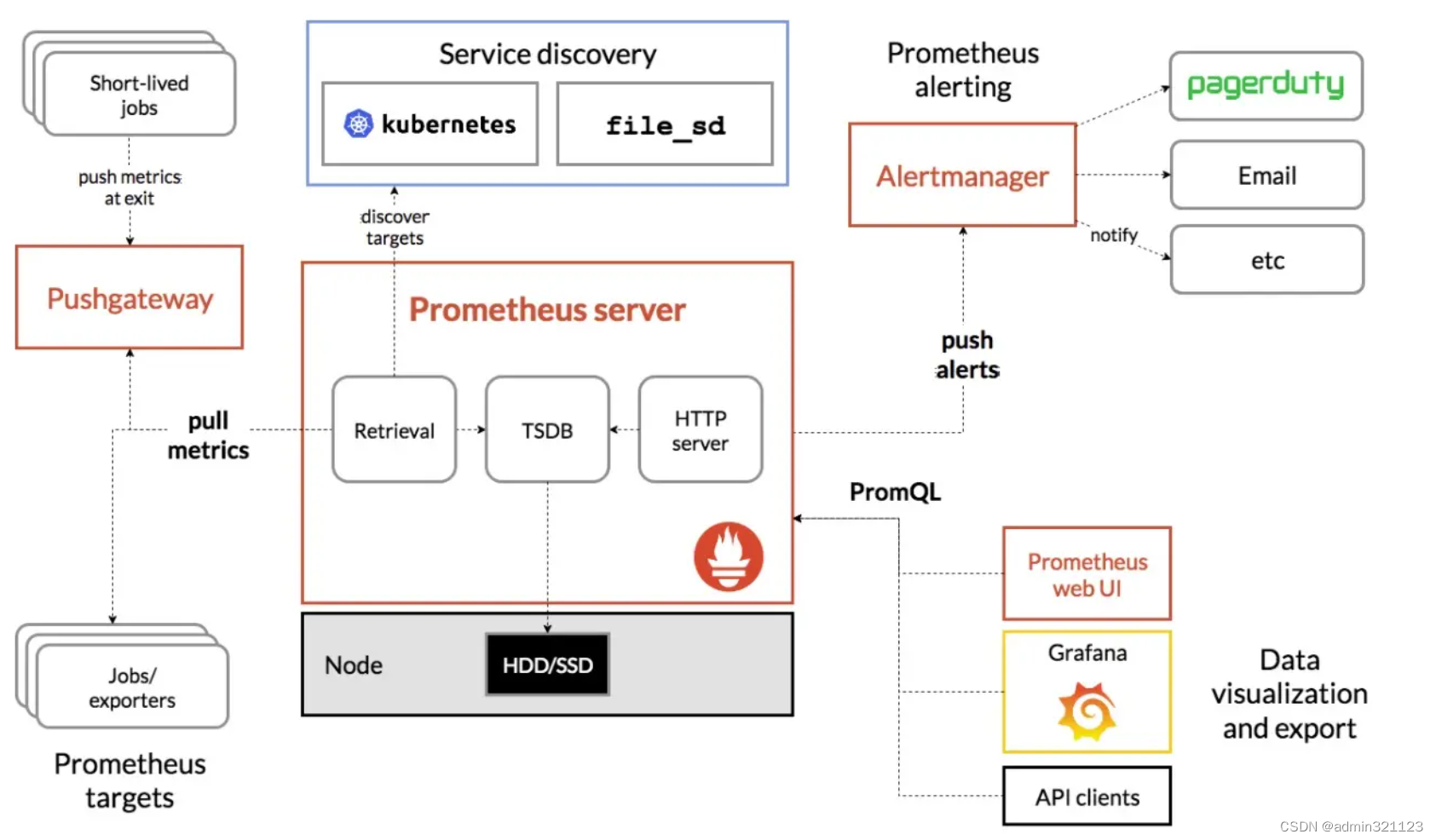
如下图所示,展示了普罗米修斯(prometheus)的建筑和它的一些生态系统组成部分。
(1)Prometheus server:
prometheus的服务端,负责收集指标和存储时间序列数据,并提供查询接口。
(2)exporters:
如果想要监控,前提是能获取被监控端数据,并且这个数据格式必须遵循Prometheus数据模型,这样才能识别和采集,一般使用exporter数据采集器(类似于zabbix_agent端)提供监控指标数据。
exporter数据采集器,除了官方和GitHub提供的常用组件exporter外,我们也可以为自己自研的产品定制exporters组件哟。
(3)Pushgateway:
短期存储指标数据,主要用于临时性的任务。比如备份数据库任务监控等。
本质上我们可以理解为Pushgateway可以帮咱们监控自定义的监控项,这需要咱们自己编写脚本来推送到Pushgateway端,而后由Prometheus server从Pushgateway去pull监控数据。
换句话说,请不要被官方的架构图蒙骗了,咱们完全可以基于Pushgateway来监控咱们自定义的监控项哟,这些监控项完全可以是长期运行的呢!
(4)Service discovery:
服务发现,例如我们可以配置动态的服务监控,无需重启Prometheus server实例就能实现动态监控。
(5)Alertmanager:
支持报警功能,比如可以支持基于邮件,微信,钉钉报警。
据网友反馈该组件在生产环境中存在缺陷,因此我们可以考虑使用Grafana来展示并实现报警功能。
(6)Prometheus Web UI
Prometheus比较简单的Web控制台,通常我们可以使用grafana来集成做更漂亮的Web展示哟。
温馨提示:
大多数Prometheus组件都是用Go编写的,这使得它们易于构建和部署为静态二进制文件。
2.部署服务端
下载链接:https://prometheus.io/download/
2.1 解压启动
tar xf /data/bestcem_rpm/monitor/prometheus-2.28.1.linux-amd64.tar.gz -C /usr/local/src/
ln -svf /usr/local/src/prometheus-2.28.1.linux-amd64 /usr/local/prometheus &>/dev/null
2.2 编辑配置文件
[root@harbor prometheus]# cat /usr/local/prometheus/prometheus.yml
#全局配置
global:
#设置prometheus采集数据的间隔时间,默认是1分钟。通常该值设置15秒就够用了。
#如果设置的间隔时间过短,比如设置为1秒,可能会造成更多的存储空间哟。
scrape_interval: 30s
#监控数据规则的评估评论,默认值为每1分钟。通常该值设置每15秒评估一次规则就够用了。
#举个例子: 假如我们定义的rule(规则)是当内存使用率大于70%就发出报警,那么prometheus会默认15秒来执行这个规则并检查内存的情况。
evaluation_interval: 30s
# Alertmanager configuration(先战略性忽略)
# 抓取数据的配置
scrape_configs:
#定义任务的名称
- job_name: "prometheus"
#定义静态的配置,比如使用targets指定要监控的对象
static_configs:
- targets: [localhost:9100]
#定义基于文件的动态配置,比如使用files指定文件路径,使用refresh_interval指定监控的间隔时间
# - file_sd_configs:
- job_name: "jenkins"
static_configs:
- targets: [192.168.221.128:9100]
有关自动发现的配置
• azure_sd_configs
• • consul_sd_configs
• dns_sd_configs
• ec2_sd_configs
• openstack_sd_configs
• • file_sd_configs
• gce_sd_configs
• • kubernetes_sd_configs
• marathon_sd_configs
• nerve_sd_configs
• serverset_sd_configs
• triton_sd_configs
2.3 使用后台启动
cd /usr/local/prometheus/prometheus
nohup ./prometheus &>/var/log/prometheus.log &
2.4 查看监控数据

3. 部署node exporter 客户端 监控软件
3.1 安装包下载
推荐链接: https://prometheus.io/download/
3.2 解压使用
tar xf node_exporter-1.2.2.linux-amd64.tar.gz -C /data
3.3 后台启动
cd /data/node_exporter-1.2.2.linux-amd64
nohup node_exporter &>/var/log/node_exporter.log &
3.4 promethues 监控 windows
参考链接:Prometheus 监控Windows机器及配置Granfana
推荐链接:Grafana Dashboard 页面下载
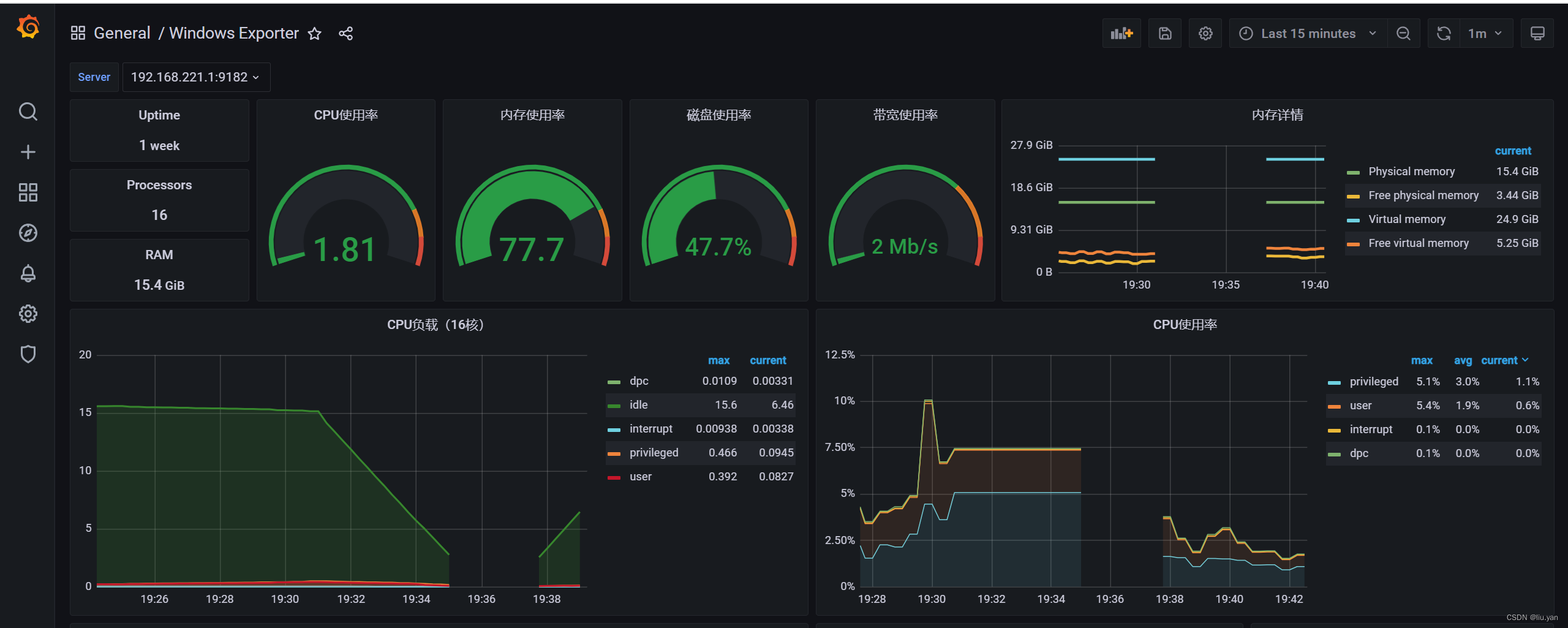
3.5 查看node exports 实例采集的metrics指标
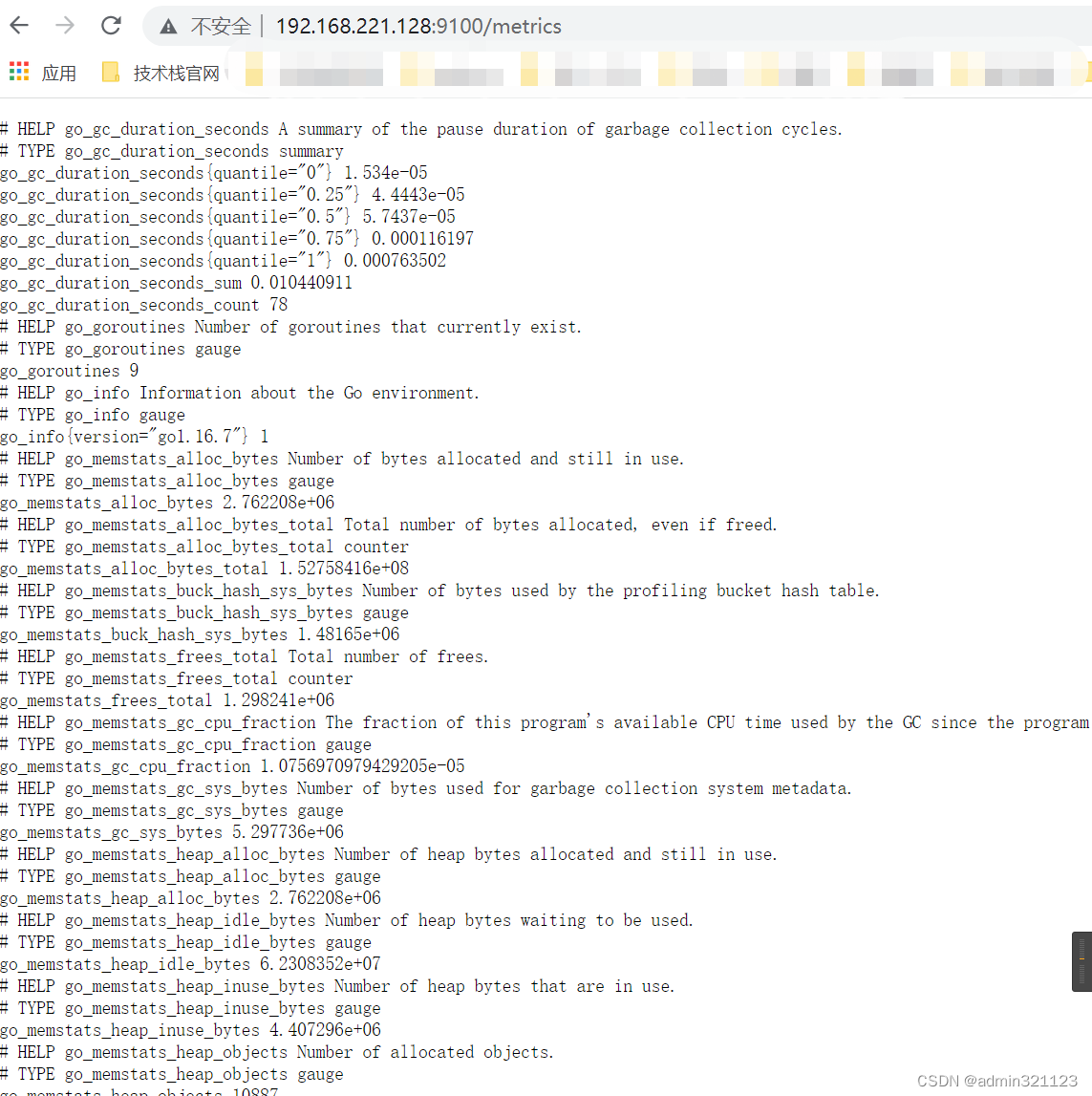
访问:http://192.168.221.128:9100/metrics
官方文档:
默认启用的采集器:
https://github.com/prometheus/node_exporter#enabled-by-default
默认禁用的采集器:
https://github.com/prometheus/node_exporter#disabled-by-default
温馨提示:
对于中小型企业,推荐大家使用默认的采集器启用的采集器即可,基本上也够咱们使用了,除非你要开启监控一些特殊的数据,可以启用对应的采集器。
3.5 metrics 简单介绍
prometheus监控中对于采集过来的数据统一称为metrics数据。
metrics是一种对采样数据的总称,其并不代表一种具体的数据格式,而是一种对于度量计算单位的抽象。
当我们需要为某个系统或者某个服务做监控,统计时,就需要用到metrics。
在Prometheus监控中,对于采集到服务端的指标数据,统一称为metrics数据。
metrics指标为时间序列数据,它们按相同的时序, 以时间维度来存储连续数据的集合。
1 metric格式
prometheus采集回来的指标数据(metric)是以key/value格式存储和展示
可以通过curl localhost:9100/metrics 获取key/value 值,如下:
node_cpu_seconds_total{cpu="0",mode="idle"} 206175.75
node_cpu_seconds_total{cpu="0",mode="iowait"} 14.25
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0.64
node_cpu_seconds_total{cpu="0",mode="softirq"} 4.28
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 417.86
node_cpu_seconds_total{cpu="0",mode="user"} 130.58
2. Metric类型
Prometheus的时序数据分为Gauge(仪表盘),Counter(计数器),Histogram(直方图)。
2.1 Gauge类型:
Gauge类型的指标用于展示瞬时的值,只有一个简单返回值,例如CPU、内存、硬盘容量等,用来反映目标在某个时间点的状态。
2.2 Counter类型
counter类型的指标与计数器一样,从0开始不断积累,趋势线上升或水平,如用户访问累积量、服务请求总量、错误总数等。
2.3 Histogram 类型
Histogram 统计数据的分布情况。比如最小值,最大值,中间值,中位数。75%,90%,92%,99.9% ,百分位值。特殊的 Metrics 数据类型,比例型数据,百分比估算数值。
如我们平时用的比较多的针对请求响应时间的90线、95线,对于90分为值也就是P90,我们简单的可以这样理解,假设有100个请求,按照响应时间从小到大排序,第90个请求的响应时间3000ms就是P90值,也就是说有90%的请求响应时间小于3000ms。
参考链接:https://www.modb.pro/db/422698
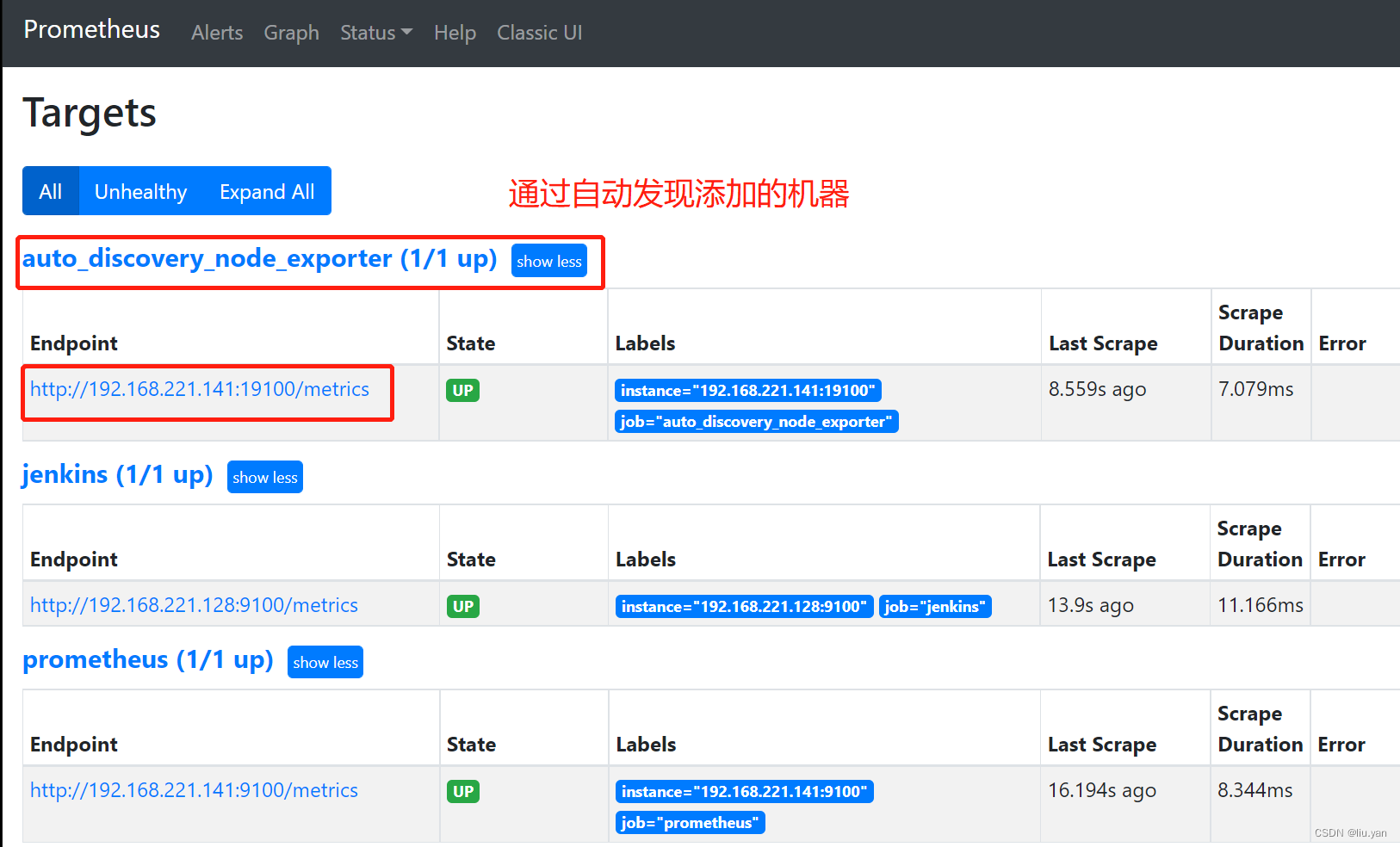
4. promethues 服务自动发现
我们在添加客户端后,每次需要手动去重启peomethues 服务端,这种方式是基于静态配置。使用promethues 自动发现(动态配置),则不需要重启服务端。
4.1 添加测试机器(以容器为例)
[root@harbor prometheus]# docker images
quay.io/prometheus/node-exporter latest 0fafea149859 14 months ago 21.2MB
docker container run -dp 19100:9100 -v "/:/host:ro,rslave" --name=node_exporter2 quay.io/prometheus/node-exporter:latest --path.rootfs /host
4.2 编辑promethues.yml文件
[root@harbor prometheus]# cat prometheus.yml
global:
scrape_interval: 30s
evaluation_interval: 30s
#基于文件实现动态配置
- job_name: "auto_discovery_node_exporter"
file_sd_configs:
- files:
- /usr/local/prometheus/discovery/node_exporter.yml
#刷新间隔
refresh_interval: 5s
#编辑自动发现文件
[root@harbor prometheus]# cat /usr/local/prometheus/discovery/node_exporter.yml
[
{
"targets": ["192.168.221.141:19100"]
#可监控多个
# "targets": ["192.168.221.141:8080","192.168.221.141:18080"]
}
]
4.3 重启promethues
ps -ef |grep prom
nohup ./prometheus &>/var/log/prometheus.log &
#后期就不用再次重启配置文件了,只需要修改/usr/local/prometheus/discovery/node_exporter.yml
promethues 会每隔5s读取文件(refresh_interval: 5s)
4.4. cadvisor 容器的自动发现
4.4.1 cadvisor 容器介绍
docker stats 可以查看容器的运行状态,但是数据比较原始且没有界面,数据可视化还需要做大量的工作

由于docker stats 有这些问题,所以cadvisor 诞生了我。cadvisor 不仅可以搜集一台机器上所有运行的容器信息还提供基础查询界面和http接口,方便promethues进行数据抓取。
4.4.2 cadvisor 容器启动
docker run \
--volume=/:/rootfs:ro \
--volume=/var/run:/var/run:rw \
--volume=/sys:/sys:ro \
--volume=/var/lib/docker/:/var/lib/docker:ro \
--volume=/dev/disk/:/dev/disk:ro \
--publish=18104:8080\
--detach=true \
--name=cadvisor \
google/cadvisor:latest
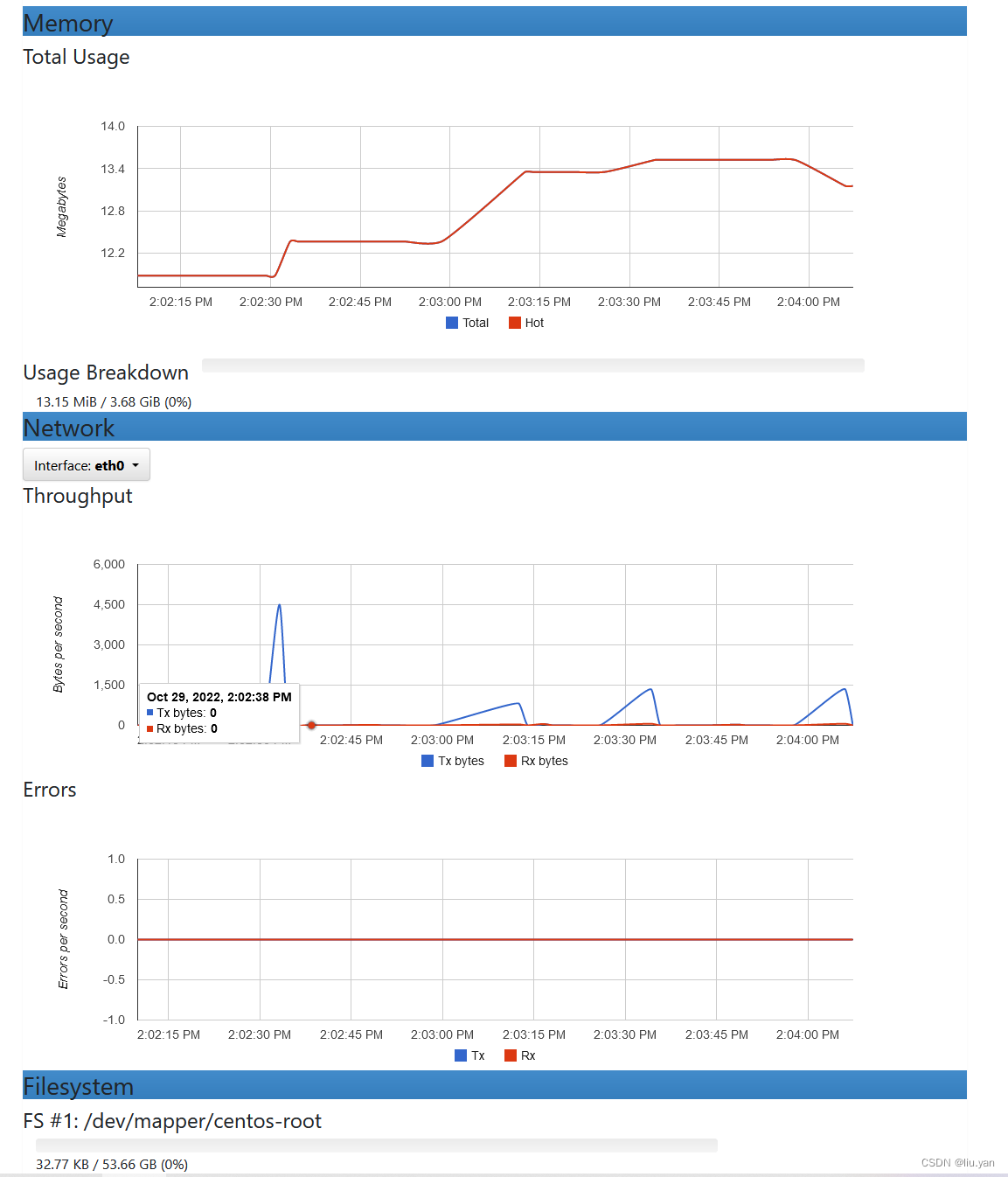
4.4.3 cadvisor 使用介绍
cadvisor部分界面如下:

grafana容器内CPU,内存,网络,磁盘信息

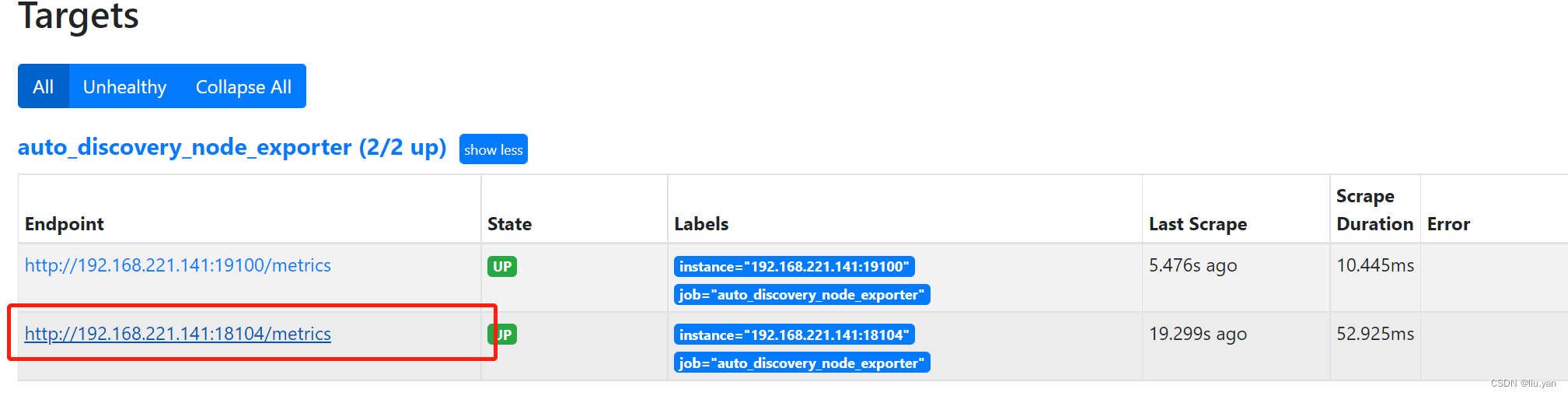
4.4.4 结合promethues 动态配置(file_sd_configs)使用
- 配置promethues 动态发现
[root@harbor discovery]# cat /usr/local/prometheus/discovery/node_exporter.yml [ { "targets": ["192.168.221.141:19100","192.168.221.141:18104"] } ] - 查看数据















 1887
1887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









