






1.dble和mycat分库分表中间件
1.1分库分表中间件原理
1.分析SQL语句 2.根据SQL语义,将SQL拆分成多个,发送至数据节点 3.将多个数据节点的结果聚集,返回客户端
1.2dble
1.高性能、高可用的MySQL分库分表中间件 2.上号爱可生公司开发 3.完全开源 4.基于开源项目MyCat
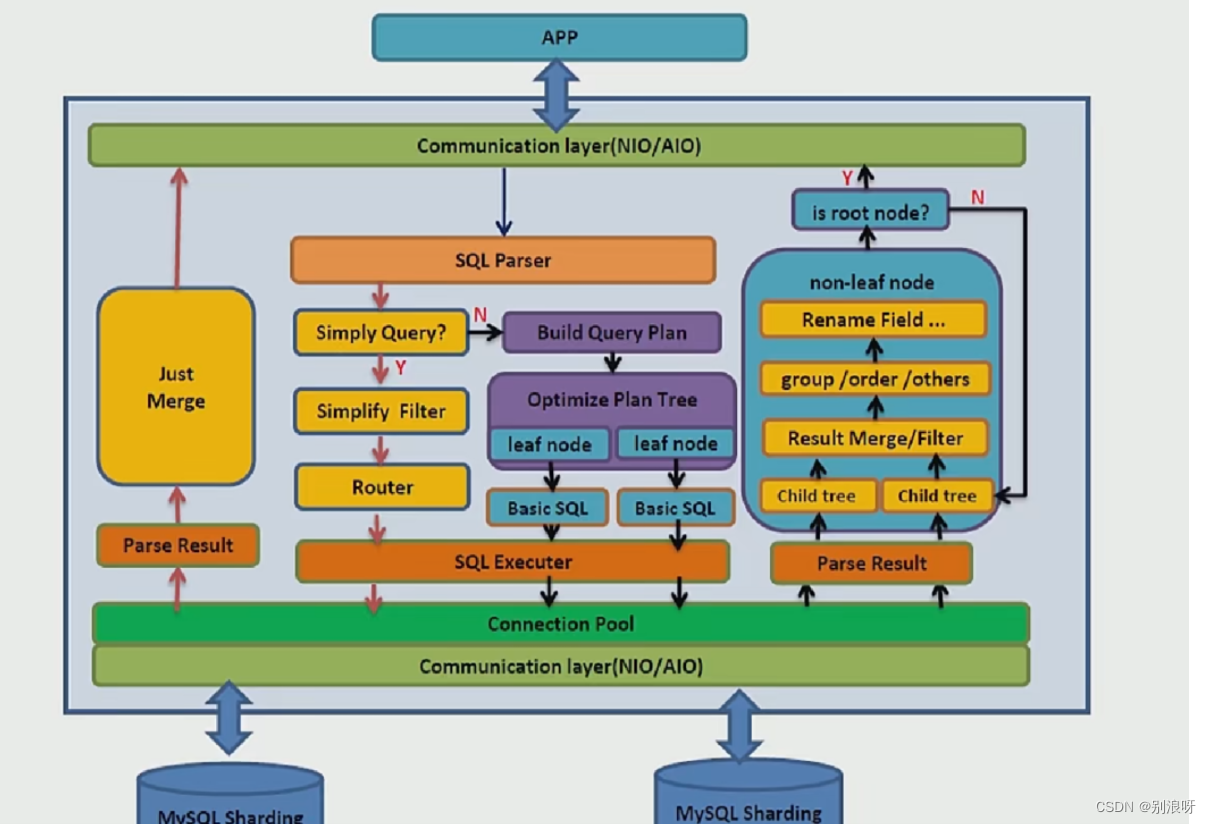
1.3dble对MyCat做的增强
1.缺陷修复 2.实现改进,插入语句语法增强,用户连接欸书增强 3.功能增强,提升性能 4.功能裁剪,去掉不用的算法
1.4dble的基本概念
1.schema:虚拟数据库(不同于传统的schema) 2.shardingTable:虚拟表(被拆分的表) 3.shardingNode:虚拟节点 4.dbGroup:实际的Mysql集群 5.database:实际的database
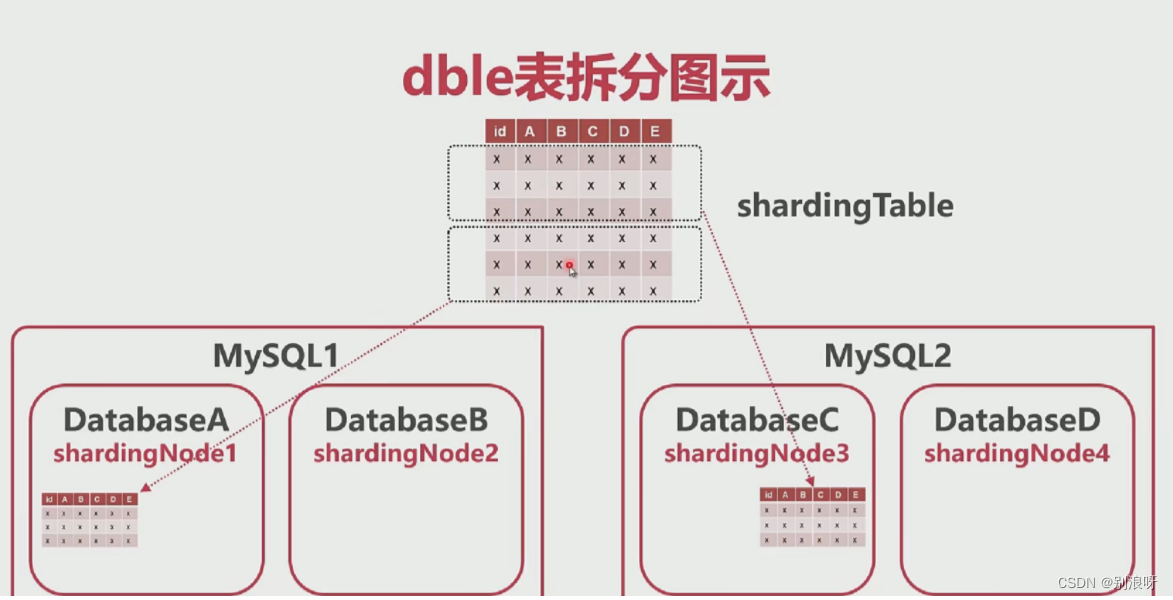
1.5dble表的类型
1.全局表:每个节点上有保存表的完整数据 2.拆分表:被拆分的表,存入不同节点 3.非拆分表:不拆分的表,存在单一节点
1.6dble节
1.dble是一个高性能、易用的分库分表中间件 2.dble基于MyCat,并做了改进 3.dble在功能上水平分表为主
2.dble最简运行环境
1.mysql A 和 mysql B 是两个独立的数据库互相不知道对方的存在
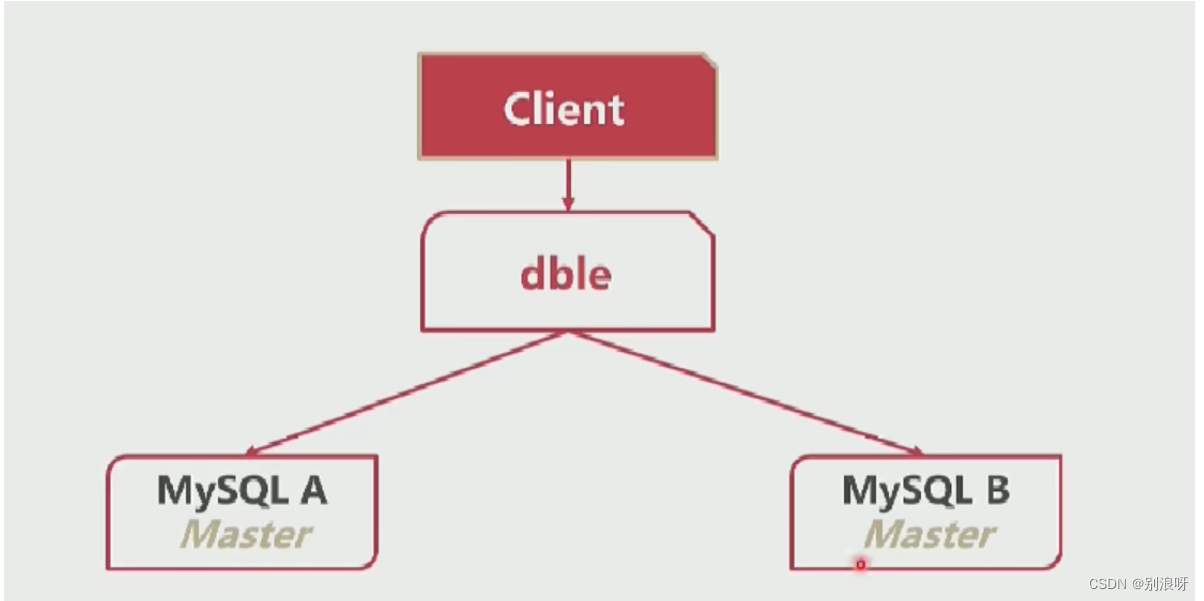
2.1安装两个mysql
5.7版本;
2.2安装java
1.8.x版本;
2.3安装dble
# 官网 https://opensource.actionsky.com/ # github 源码位置 https://github.com/actiontech/dble # 下载版本页面 https://github.com/actiontech/dble/releases # 3.21.10.3 版本 https://github.com/actiontech/dble/releases/download/3.21.10.3%2Ftag/dble-3.21.10.3-20220331093302-java1.8.0_151-linux.tar.gz # 百度网盘 链接:https://pan.baidu.com/s/1Pmw_KOzK9wTmnh9sP42tZA 提取码:4545 # lunix 下载 wget https://github.com/actiontech/dble/releases/download/3.21.10.3%2Ftag/dble-3.21.10.3-20220331093302-java1.8.0_151-linux.tar.gz # 解压dao /var/lib 目录下 tar -xvf dble-3.21.10.3-20220331093302-java1.8.0_151-linux.tar.gz -C '/var/lib/'
2.4dble配置文件
# 进入dble配置目录 cd /var/lib/dble/conf ll [root@localhost conf]# ll 总用量 76 -rw-rw-r--. 1 2000 2000 0 3月 31 17:32 bootstrap.dynamic.cnf -rw-rw-r--. 1 2000 2000 5399 3月 31 17:32 bootstrap_template.cnf -rw-rw-r--. 1 2000 2000 304 3月 31 17:32 cacheservice.properties -rw-rw-r--. 1 2000 2000 720 3月 31 17:32 cluster_template.cnf -rw-rw-r--. 1 2000 2000 1203 3月 31 17:32 dbseq.sql -rw-rw-r--. 1 2000 2000 1553 3月 31 17:32 db_template.xml -rw-rw-r--. 1 2000 2000 631 3月 31 17:32 ehcache.xml -rw-rw-r--. 1 2000 2000 4648 3月 31 17:32 log4j2.xml -rw-rw-r--. 1 2000 2000 15 3月 31 17:32 partition-enum.txt -rw-rw-r--. 1 2000 2000 88 3月 31 17:32 partition-number-range.txt -rw-rw-r--. 1 2000 2000 108 3月 31 17:32 partition-pattern.txt -rw-rw-r--. 1 2000 2000 607 3月 31 17:32 sequence_conf.properties -rw-rw-r--. 1 2000 2000 267 3月 31 17:32 sequence_db_conf.properties -rw-rw-r--. 1 2000 2000 6810 3月 31 17:32 sharding_template.xml -rw-rw-r--. 1 2000 2000 6411 3月 31 17:32 template_table.sql -rw-rw-r--. 1 2000 2000 1809 3月 31 17:32 user_template.xml
2.5dble集群配置文件
# dble 集群配置文件 cluster_template.cnf vi cluster_template.cnf # Copyright (C) 2016-2020 ActionTech. # License: http://www.gnu.org/licenses/gpl.html GPL version 2 or higher. # clusterEnable=false # cluster ucore/zk clusterMode=zk # zk: clusterIP=10.186.19.aa:2281,10.186.60.bb:2281 clusterIP=10.186.61.132:2181 # zk not need cluster.port clusterPort=5700 rootPath=/dble #cluster namespace, please use the same one in one cluster clusterId=cluster-1 # if HA need sync by cluster, only useful when useOuterHa=true needSyncHa=false # unit is millisecond showBinlogStatusTimeout=60000 sequenceHandlerType=2 # valid for sequenceHandlerType=2 or 3 #sequenceStartTime=2010-11-04 09:42:54 # valid for sequenceHandlerType=3 and clusterMode is zk, default true #sequenceInstanceByZk=true # 复制配置文件去掉template cp cluster_template.cnf cluster.cnf
2.6bootstrap.dynamic.cnf
# 和java相关配置,复制文件去掉template cp bootstrap_template.cnf bootstrap.cnf
2.7db_template.xml
# 实际数据分片配置文件 修改数据库实际地址
cp db_template.xml db.xml
# 核心配置文件
<?xml version="1.0"?>
<!--
修改dble 链接数据库的配置信息
-->
<dble:db xmlns:dble="http://dble.cloud/" version="4.0">
<dbGroup name="dbGroup1" rwSplitMode="2" delayThreshold="100">
<heartbeat>show slave status</heartbeat>
<!-- 第一个数据分片地址
实际数据分片地址,修改 dbInstance 标签
-->
<dbInstance name="instanceM1" url="ip1:3306" user="your_user" password="your_psw" maxCon="1000" minCon="10"
primary="true" readWeight="1" id="xx1">
<property name="testOnCreate">true</property>
</dbInstance>
<!--<dbInstance name="instanceS1" url="ip3:3306" user="your_user" password="your_psw" maxCon="1000" minCon="10" readWeight="2" disabled="true">-->
<!--<property name="testOnCreate">false</property>-->
<!--</dbInstance>-->
</dbGroup>
<dbGroup name="dbGroup2" rwSplitMode="0" delayThreshold="100" disableHA="true">
<heartbeat errorRetryCount="1" timeout="10">show slave status</heartbeat>
<!-- 第二个数据分片地址
实际数据分片地址,修改 dbInstance 标签
-->
<dbInstance name="instanceM2" url="ip2:3306" user="your_user" password="your_psw" maxCon="1000" minCon="10"
primary="true">
<property name="testOnCreate">true</property>
</dbInstance>
<!-- can have multi read instances -->
<!--<dbInstance name="instanceS2" url="ip4:3306" user="your_user" password="your_psw" maxCon="1000" minCon="10" usingDecrypt="true">-->
<!--<property name="testOnCreate">true</property>-->
<!--</dbInstance>-->
</dbGroup>
</dble:db>
2.7user_template.xml
cp user_template.xml user.xml <!-- 真正的客户端能够链接到dble的用户名和密码 --> <!-- - - Licensed under the Apache License, Version 2.0 (the "License"); - you may not use this file except in compliance with the License. - You may obtain a copy of the License at - - http://www.apache.org/licenses/LICENSE-2.0 - - Unless required by applicable law or agreed to in writing, software - distributed under the License is distributed on an "AS IS" BASIS, - WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. - See the License for the specific language governing permissions and - limitations under the License. --> <dble:user xmlns:dble="http://dble.cloud/" version="4.0"> <managerUser name="man1" password="654321" maxCon="100"/> <managerUser name="user" usingDecrypt="true" whiteIPs="127.0.0.1,0:0:0:0:0:0:0:1" readOnly="true" password="AqEkFEuIFAX6g2TJQnp4cJ2r7Yc0Z4/KBsZqKhT8qSz18Aj91e8lxO49BKQElC6OFfW4c38pCYa8QGFTub7pnw=="/> <shardingUser name="root" password="123456" schemas="testdb" readOnly="false" blacklist="blacklist1" maxCon="20"/> <shardingUser name="root2" password="123456" schemas="testdb,testdb2" maxCon="20" tenant="tenant1"> <privileges check="true"> <schema name="testdb" dml="0110"> <table name="tb_global1" dml="0000"/> <table name="tb_global2" dml="1111"/> </schema> </privileges> </shardingUser> <!--rwSplitUser not work for now--> <!--<rwSplitUser name="rwsu1" password="123456" dbGroup="dbGroup1" blacklist="blacklist1" maxCon="20"/>--> <blacklist name="blacklist1"> <property name="selelctAllow">true</property> </blacklist> </dble:user>
2.8sharding_template.xml
cp sharding_template.xml sharding.xml # 设置数据分片,虚拟数据库,虚拟数据表 <?xml version="1.0"?> <!-- ~ Copyright (C) 2016-2020 ActionTech. ~ License: http://www.gnu.org/licenses/gpl.html GPL version 2 or higher. --> <dble:sharding xmlns:dble="http://dble.cloud/" version="4.0"> <schema name="testdb" sqlMaxLimit="100"> <!-- 配置水平分表 name 拆分的虚拟表名称, shardingNode 把这个数据拆分到dn1和dn2两个数据节点上 对应shardingNode标签 function 使用的拆分函数。对应function 标签 shardingColumn 按照这个表哪个列去拆分 --> <shardingTable name="tb_enum_sharding" shardingNode="dn1,dn2" sqlMaxLimit="200" function="func_enum" shardingColumn="code"/> <shardingTable name="tb_range_sharding" shardingNode="dn1,dn2,dn3" function="func_range" shardingColumn="id"/> <!-- --> <shardingTable name="tb_hash_sharding" shardingNode="dn1,dn2" function="func_common_hash" shardingColumn="id"/> <shardingTable name="tb_hash_sharding_er1" shardingNode="dn1,dn2" function="func_common_hash" shardingColumn="id"/> <shardingTable name="tb_hash_sharding_er2" shardingNode="dn1,dn2" function="func_common_hash" shardingColumn="id2"/> <shardingTable name="tb_hash_sharding_er3" shardingNode="dn1,dn2" function="func_common_hash" shardingColumn="id" incrementColumn="id2"/> <shardingTable name="tb_uneven_hash" shardingNode="dn1,dn2,dn3" function="func_uneven_hash" shardingColumn="id"/> <shardingTable name="tb_mod" shardingNode="dn1,dn2,dn3,dn4" function="func_mod" shardingColumn="id" sqlRequiredSharding="true"/> <shardingTable name="tb_jump_hash" shardingNode="dn1,dn2" function="func_jumpHash" shardingColumn="code"/> <shardingTable name="tb_hash_string" shardingNode="dn1,dn2,dn3,dn4" function="func_hashString" shardingColumn="code"/> <shardingTable name="tb_date" shardingNode="dn1,dn2,dn3,dn4" function="func_date" shardingColumn="create_date"/> <shardingTable name="tb_pattern" shardingNode="dn1,dn2" function="func_pattern" shardingColumn="id"/> <!--global tables--> <globalTable name="tb_global1" shardingNode="dn1,dn2" sqlMaxLimit="103" /> <globalTable name="tb_global2" shardingNode="dn1,dn2,dn3,dn4" cron="0 0 0 * * ?" checkClass="CHECKSUM"/> <!--single node table--> <singleTable name="tb_single" shardingNode="dn6" sqlMaxLimit="105"/> <!--er tables--> <shardingTable name="tb_parent" shardingNode="dn1,dn2" function="func_common_hash" shardingColumn="id"> <childTable name="tb_child1" joinColumn="child1_id" parentColumn="id" sqlMaxLimit="201"> <childTable name="tb_grandson1" joinColumn="grandson1_id" parentColumn="child1_id"/> <childTable name="tb_grandson2" joinColumn="grandson2_id" parentColumn="child1_id2"/> </childTable> <childTable name="tb_child2" joinColumn="child2_id" parentColumn="id"/> <childTable name="tb_child3" joinColumn="child3_id" parentColumn="id2"/> </shardingTable> </schema> <!-- --> <schema name="testdb2" shardingNode="dn5"/> <!-- dbGroup 对应物理数据节点 database 数据库名 --> <shardingNode name="dn1" dbGroup="dbGroup1" database="db_1"/> <shardingNode name="dn2" dbGroup="dbGroup2" database="db_2"/> <shardingNode name="dn3" dbGroup="dbGroup1" database="db_3"/> <shardingNode name="dn4" dbGroup="dbGroup2" database="db_4"/> <shardingNode name="dn5" dbGroup="dbGroup1" database="db_5"/> <shardingNode name="dn6" dbGroup="dbGroup2" database="db_6"/> <!-- enum partition --> <function name="func_enum" class="Enum"> <property name="mapFile">partition-enum.txt</property> <property name="defaultNode">0</property><!--the default is -1,means unexpected value will report error--> <property name="type">0</property><!--0 means key is a number, 1 means key is a string--> </function> <!-- number range partition --> <function name="func_range" class="NumberRange"> <property name="mapFile">partition-number-range.txt</property> <property name="defaultNode">0</property><!--he default is -1,means unexpected value will report error--> </function> <!-- Hash partition,when partitionLength=1, it is a mod partition, MAX(sum(count*length[i]) must not more then 2880--> <function name="func_common_hash" class="Hash"> <property name="partitionCount">2</property> <property name="partitionLength">512</property> </function> <!-- Hash partition,when partitionLength=1, it is a mod partition, MAX(sum(count*length[i]) must not more then 2880--> <function name="func_uneven_hash" class="Hash"> <property name="partitionCount">2,1</property> <property name="partitionLength">256,512</property> </function> <!-- eg: mod 4 --> <function name="func_mod" class="Hash"> <property name="partitionCount">4</property> <property name="partitionLength">1</property> </function> <!-- jumpStringHash partition for string--> <function name="func_jumpHash" class="jumpStringHash"> <property name="partitionCount">2</property> <property name="hashSlice">0:2</property> </function> <!-- Hash partition for string--> <function name="func_hashString" class="StringHash"> <property name="partitionCount">4</property> <property name="partitionLength">256</property> <property name="hashSlice">0:2</property> <!--<property name="hashSlice">-4:0</property> --> </function> <!-- date partition 4 case: 1.set sEndDate and defaultNode: input <sBeginDate ,router to defaultNode; input>sEndDate ,mod the period 2.set sEndDate, but no defaultNode:input <sBeginDate report error; input>sEndDate ,mod the period 3.set defaultNode without sEndDate: input <sBeginDate router to defaultNode;input>sBeginDate + (node size)*sPartionDay-1 will report error(expected is defaultNode,but can't control now) 4.sEndDate and defaultNode are all not set: input <sBeginDate report error;input>sBeginDate + (node size)*sPartionDay-1 will report error --> <function name="func_date" class="Date"> <property name="dateFormat">yyyy-MM-dd</property> <property name="sBeginDate">2015-01-01</property> <property name="sEndDate">2015-01-31</property> <!--if not set sEndDate,then in fact ,the sEndDate = sBeginDate+ (node size)*sPartionDay-1 --> <property name="sPartionDay">10</property> <property name="defaultNode">0</property><!--the default is -1--> </function> <!-- pattern partition : mapFile must contains all value of 0~patternValue-1,key and value must be Continuous increase--> <function name="func_pattern" class="PatternRange"> <property name="mapFile">partition-pattern.txt</property> <property name="patternValue">1024</property> <property name="defaultNode">0</property><!--contains string which is not number,router to default node--> </function> </dble:sharding>
2.9template_table.sql
# 示例表格所需要的建表语句 -- testdb schema for template only -- @since 2019-04-26 -- @author yanhuqing666 -- 水平分表案例 use testdb; drop table if exists tb_enum_sharding; create table if not exists tb_enum_sharding ( id int not null, code int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_enum_sharding values(1,10000,'1'),(2,10010,'2'),(3,10000,'3'),(4,10010,'4'); drop table if exists tb_range_sharding; create table if not exists tb_range_sharding ( id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_range_sharding values(1,'1'),(5000001,'5000001'),(10000001,'10000001'); drop table if exists tb_hash_sharding; create table if not exists tb_hash_sharding ( id int not null, id2 int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_hash_sharding values(1,1,'1'),(2,2,'2'),(513,513,'513'); drop table if exists tb_hash_sharding_er1; create table if not exists tb_hash_sharding_er1 ( id int not null, id2 int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_hash_sharding_er1 values(1,1,'1'),(2,2,'2'),(513,513,'513'); drop table if exists tb_hash_sharding_er2; create table if not exists tb_hash_sharding_er2 ( id int not null, id2 bigint not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_hash_sharding_er2 values(1,1,'1'),(2,2,'2'),(513,513,'513'); drop table if exists tb_hash_sharding_er3; create table if not exists tb_hash_sharding_er3 ( id int not null, id2 bigint not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_hash_sharding_er3(id,content) values(1,'1'),(2,'2'),(513,'513'); drop table if exists tb_uneven_hash; create table if not exists tb_uneven_hash ( id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_uneven_hash values(1,'1'),(257,'257'),(513,'513'); drop table if exists tb_mod; create table if not exists tb_mod ( id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_mod values(1,'1'),(2,'2'),(3,'3'),(4,'4'); drop table if exists tb_jump_hash; create table if not exists tb_jump_hash ( id int not null, code varchar(250) not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_jump_hash values(1,'1','1'),(2,'2','2'),(3,'3','3'),(4,'4','4'); drop table if exists tb_hash_string; create table if not exists tb_hash_string ( id int not null, code varchar(250) not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_hash_string values(1,'1','1'),(2,'2','2'),(3,'3','3'),(4,'4','4'); drop table if exists tb_date; create table if not exists tb_date ( id int not null, code varchar(250) not null, create_date date not null, primary key(id) )engine=innodb charset=utf8; insert into tb_date values(1,'1','2015-01-01'),(2,'2','2015-01-11'),(3,'3','2015-01-21'); drop table if exists tb_pattern; create table if not exists tb_pattern ( id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_pattern values(1,'1'),(11,'11'); -- global tables drop table if exists tb_global1; create table if not exists tb_global1 ( id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_global1 values(1,'1'),(2,'2'); drop table if exists tb_global2; create table if not exists tb_global2 ( id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_global2 values(1,'1'),(2,'2'); drop table if exists tb_single; create table if not exists tb_single ( id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_single values(1,'1'),(2,'2'); drop table if exists tb_parent; create table if not exists tb_parent ( id int not null, id2 int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_parent values(1,1,'1'),(2,2,'2'),(513,513,'513'); drop table if exists tb_child1; create table if not exists tb_child1 ( id int not null, child1_id int not null, child1_id2 int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_child1 values(1,1,1,'1'); insert into tb_child1 values(2,2,2,'2'); insert into tb_child1 values(513,513,513,'513'); drop table if exists tb_grandson1; create table if not exists tb_grandson1 ( id int not null, grandson1_id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_grandson1 values(1,1,'1'); insert into tb_grandson1 values(2,2,'2'); insert into tb_grandson1 values(513,513,'513'); drop table if exists tb_grandson2; create table if not exists tb_grandson2 ( id int not null, grandson2_id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_grandson2 values(1,1,'1'); insert into tb_grandson2 values(2,2,'2'); insert into tb_grandson2 values(513,513,'513'); drop table if exists tb_child2; create table if not exists tb_child2 ( id int not null, child2_id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_child2 values(1,1,'1'); insert into tb_child2 values(2,2,'2'); insert into tb_child2 values(513,513,'513'); drop table if exists tb_child3; create table if not exists tb_child3 ( id int not null, child3_id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_child3 values(1,1,'1'); insert into tb_child3 values(2,2,'2'); insert into tb_child3 values(513,513,'513'); use testdb2; drop table if exists tb_test1; create table if not exists tb_test1 ( id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_test1 values(1,'1'),(2,'2'); drop table if exists tb_test2; create table if not exists tb_test2 ( id int not null, content varchar(250) not null, primary key(id) )engine=innodb charset=utf8; insert into tb_test2 values(1,'1'),(2,'2');
3.dble运行
# 进入dble启动目录 cd /var/lib/dble/bin # 启动 /var/lib/dble/bin/dble start # 重启 /var/lib/dble/bin/dble restart Starting dble-server... [root@localhost conf]# # 查看日志 tail -f /var/lib/dble/logs/wrapper.log tail -f /var/lib/dble/logs/dble.log # 打开管理端接口 9066 firewall-cmd --zone=public --add-port=9066/tcp --permanent firewall-cmd --zone=public --add-port=8066/tcp --permanent firewall-cmd --reload # 链接dble mysql客户端 mysql -h 192.168.1.9 -uman1 -P9066 -p654321 # 数据端口8066 数据节点 用户名root/123456 mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 2003 (HY000): Can't connect to MySQL server on '192.168.1.9' (113) [root@localhost ~]# mysql -h'192.168.1.9' -uman1 -P9006 -p654321 mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 2003 (HY000): Can't connect to MySQL server on '192.168.1.9' (113) [root@localhost ~]# mysql -h 192.168.1.9 -uman1 -P9006 -p654321 mysql: [Warning] Using a password on the command line interface can be insecure. ERROR 2003 (HY000): Can't connect to MySQL server on '192.168.1.9' (113) [root@localhost ~]# mysql -h 192.168.1.9 -uman1 -P9066 -p654321 mysql: [Warning] Using a password on the command line interface can be insecure. Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1 Server version: 5.7.11-dble-3.21.10.3-7023a10895753d46ee8343cc337b1d5d66bf593c-20220331093302 dble Server (ActionTech) Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> # 创建数据库 create database @@shardingnode='dn$1-6'; # 登录dble服务端口 mysql -h 192.168.1.9 -uroot -P8066 -p123456 mysql> show databases; +----------+ | DATABASE | +----------+ | testdb | +----------+ 1 row in set (0.02 sec) mysql>
4.提高分库分表架构的可靠性
1.解决数据完整性,主从复制
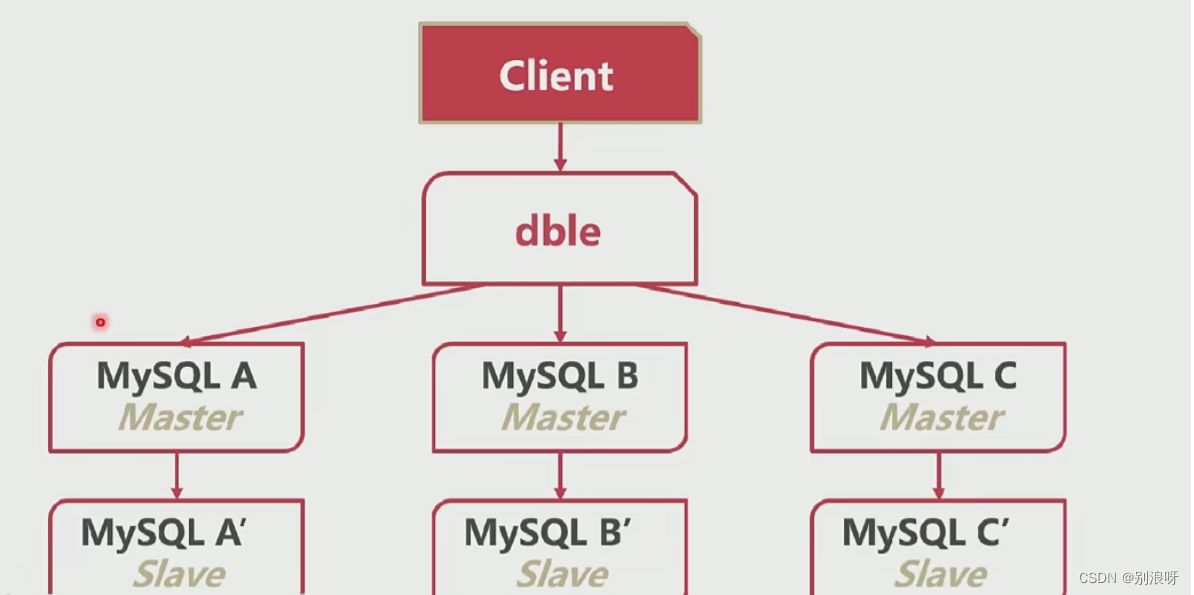
5.使用dble进行读写分离
/1.使用dble进行读写分离 2.dble分析sql将读发给从 3.rwSplitMode=0 直接分发到主实例 4.rwSplitMode=1 读操作必须在所有从实例中均衡 5.rwSplitMode=2 读操作在所有实例中均衡 6.rwSplitMode=3 读操作尽量在所有实例中均衡r 7.rwSplitMode=3 读操作尽量在所有实例中均衡,有从走从,没有走主
6.配至两台主和一台从
略
7.配至读写分离
# 1.配置db.xml disabled="false" 改为false,true 是这个节点废弃了 # rwSplitMode="3" 读操作尽量在所有实例中均衡,有从走从,没有走主 <?xml version="1.0"?> <!-- ~ Copyright (C) 2016-2020 ActionTech. ~ License: http://www.gnu.org/licenses/gpl.html GPL version 2 or higher. --> <dble:db xmlns:dble="http://dble.cloud/" version="4.0"> <dbGroup name="dbGroup1" rwSplitMode="3" delayThreshold="100"> <heartbeat>show slave status</heartbeat> <dbInstance name="instanceM1" url="192.168.1.7:3306" user="root" password="admin123" maxCon="1000" minCon="10" primary="true" readWeight="1" id="xx1"> <property name="testOnCreate">true</property> </dbInstance> <dbInstance name="instanceS1" url="192.168.1.10:3306" user="root" password="admin123" maxCon="1000" minCon="10" readWeight="2" disabled="false" <property name="testOnCreate">false</property> </dbInstance> </dbGroup> <dbGroup name="dbGroup2" rwSplitMode="0" delayThreshold="100" disableHA="true"> <heartbeat errorRetryCount="1" timeout="10">show slave status</heartbeat> <dbInstance name="instanceM2" url="192.168.1.9:3306" user="root" password="admin123" maxCon="1000" minCon="10" primary="true"> <property name="testOnCreate">true</property> </dbInstance> <!-- can have multi read instances --> <!--<dbInstance name="instanceS2" url="ip4:3306" user="your_user" password="your_psw" maxCon="1000" minCon="10" usingDecrypt="true">--> <!--<property name="testOnCreate">true</property>--> <!--</dbInstance>--> </dbGroup> </dble:db> # 配置好重启 /var/lib/dble/bin/dble restart # 记录sql语句去实际节点执行命令 SET GLOBAL log_output = 'TABLE'; SET GLOBAL general_log = 'on'; # 查看sql语句,去实际节点执行 SELECT * from mysql.general_log ORDER BY envent_time desc;
8.分库分表之后性能反而下降,怎么办。
1.查询语句where 条件中尽可能带有拆分字段 2.插入语句必须带有拆分字段,根据拆分字段具体往哪个分库插入 3.若使用in子句,缩减in子句值的数量 4.减少表的搜索遍历 5.减少结果集。 6.跨节点连表 7.尽量使用拆分字段作为join条件 8.尽量少使用跨界点排序,分页功能 9.复杂的语句拆分成多条语句 数据crud尽量带拆分字段,尽量减少数据节点之间的数据交换,尽量将连接键作为拆分字段
9.小结
1.分区表 提升单节点表容量 2.分库分表:提升数据库性能,使用数据方法更复杂数据丢失的可能行增加 3.dble数据库中间件,水平分库、分表,读写分离
10.主从切换
10.1切换保业务还是保数据
1.将已经宕机的主数据库,切换到从数据库 2.停止备库同步 3.配置主库复制从库,身份切换
10.2可靠性数据优先策略
1.检查从库seconds_behind_master ,时间落后A库多少时间时间 2.落后时间太长,主库开启只读readonly=true 3.检查seconds_behind_master==0 4.等于0,从库关只读readonly=false 5.从库停止复制主库,主库开始复制从库,身份切换 6.可以保证数据五丢失,但是有几秒的时间两个数据库均不可写 7.一开始未检查seconds_behind_master,不可用时间无法控制
10.3可用性优先策略
1.取消等待数据一致的过程 2.主库只读、从库关只读 3.从库停止复制主库,主库开始复制从库 4.系统没有不可写的时间 5.有可能造成数据不一致错误
10.4数据库切换了,业务怎么连接备库
1.业务预留接口,通知新的数据库切换至新地址 2.使用微服务业务通知 3.内部搭建(coreDNS)DNS服务其,通知域名连接 4.vip漂移,使用keepalived进行vip漂移 5.使用代理,负载均衡器代理HaProxy、内网穿透 6.使用dble修改数据库配置文件,没方法探测数据库死活
10.5小结
1.业务切换至新地址:不影响性能,业务可能不支持 2.使用内部DNS:方便,需要多余硬件资源 3.vip漂移:自动漂移,需要多余的ip资源 4.使用代理:自动更新,需要多余资源 5.dble:客户无感知,需要被动通知
11.如何实现自动主从切换
11.1keepalived
1.常用的高可用组件 2.可以检测节点状态 3.自动执行切换脚本 4.还有VIP漂移功能
11.2MHA(Master High Availability)
1.常用的MySQL高可用组件 2.支持GTID方式 3.从宕机崩溃的master抢救未传送的binlog 4.等待从库执行中继日志,追赶Master 5.在从库执行从主库Master抢救出的binlog 6.从库和主库宕机前状态一样 7.提升从库为主库 8.提升从从库为从库,复制新的主库 9.修复好数据库宕机,再重新将配置好的主从关系配置到MHA
11.3研高可用组件
1.完全自主控制 2.研发代价高
11.4总结
1.keepalived可以自动切换身份,不完善 2.MHA比较完善的MySQL自动身份切换工具 3.有更高级的MySql管理需求,可以二次开发MHA或者自己的语言
12.MHA实战
12.1架构图
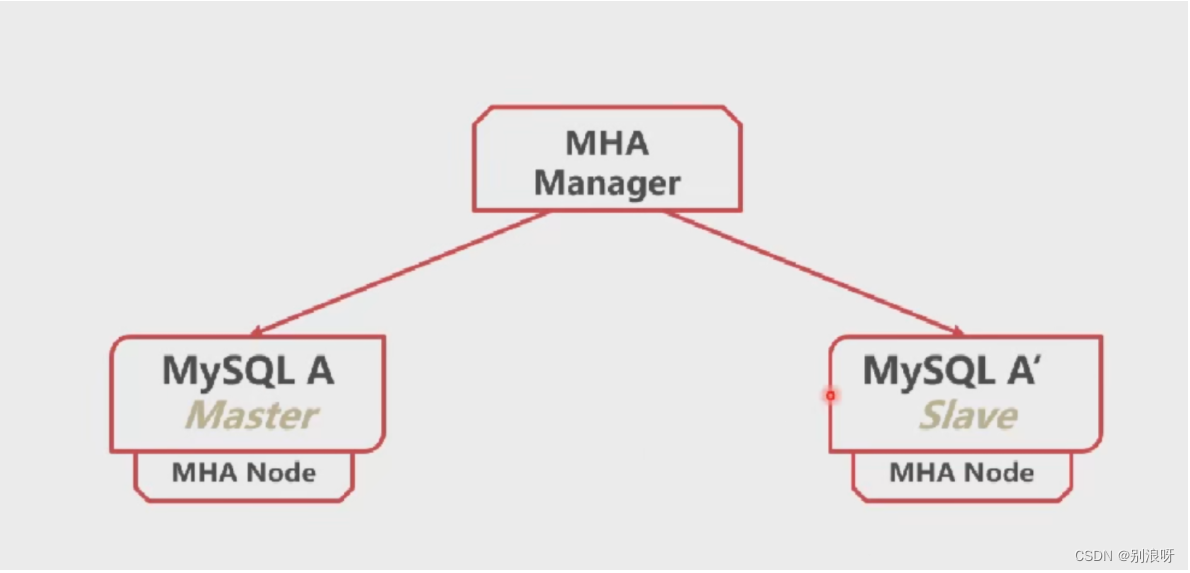
12.2github地址
# 主页地址 https://github.com/yoshinorim # 管理程序 https://github.com/yoshinorim/mha4mysql-manager # 预置到各个节点 https://github.com/yoshinorim/mha4mysql-node # 节点程序下载链接 https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58-0.el7.centos.noarch.rpm # 管理程序下载链接 https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
12.3安装mha4mysql-node
# 主从都要做 rpm -ivh mysql-community-libs-compat-5.7.18-1.el7.x86_64.rpm # perl-DBD-MySQL 脚本语言 yum install perl-DBD-MySQL -y # 依赖库 yum install epel-release -y # 清理yum缓存 yum clean all # 重新拉yum源 yum makecache # 安装mha4mysql-node-0.58-0.el7 rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
12.4安装mha4mysql-manager
# 上面不安装mha4mysql-node-0.58-0.el7的基础+ yum install mha4mysql-node-0.58-0.el7.centos.noarch.rpm
12.5让所有的服务器登录都免密
vim /etc/ssh/sshd_config PermitRootLogin yes # 允许root账户在远程登陆 PubkeyAuthentication yes
12.6配置MHA本身
vim /etc/mha.cnf # 检查主从之间免密连接 sudo masterha_check_ssh --conf=/etc/mha.cnf successfull # 检查主备复制是否正常 sudo masterha_check_repl --conf=/etc/mha.cnf successfull # 检查现在MHA工作状态 sudo masterha_check_status --conf=/etc/mha.cnf # 启动MHA sudo masterha_manager --conf=/etc/mha.cnf & # 查看日志,不停查看主节点状态。手动停止主库。查看日志状态。 tail -f /var/log/masterha/app1/app1.log # 进入从库查看从库状态 show slave status\G;
12.7MHA与DBLE联动
1.配置MHA使用脚本通知dble
12.8高可用了。集群为什么还会挂
1.dble单点问题可能造成数据库系统无法使用 2.使用zookeeper存储数据库信息、表信息、分片信息 3.MHA只能配置一个dble,使用SLB/Haproxy高可用 4.keepalived ip漂移


















 1375
1375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









