










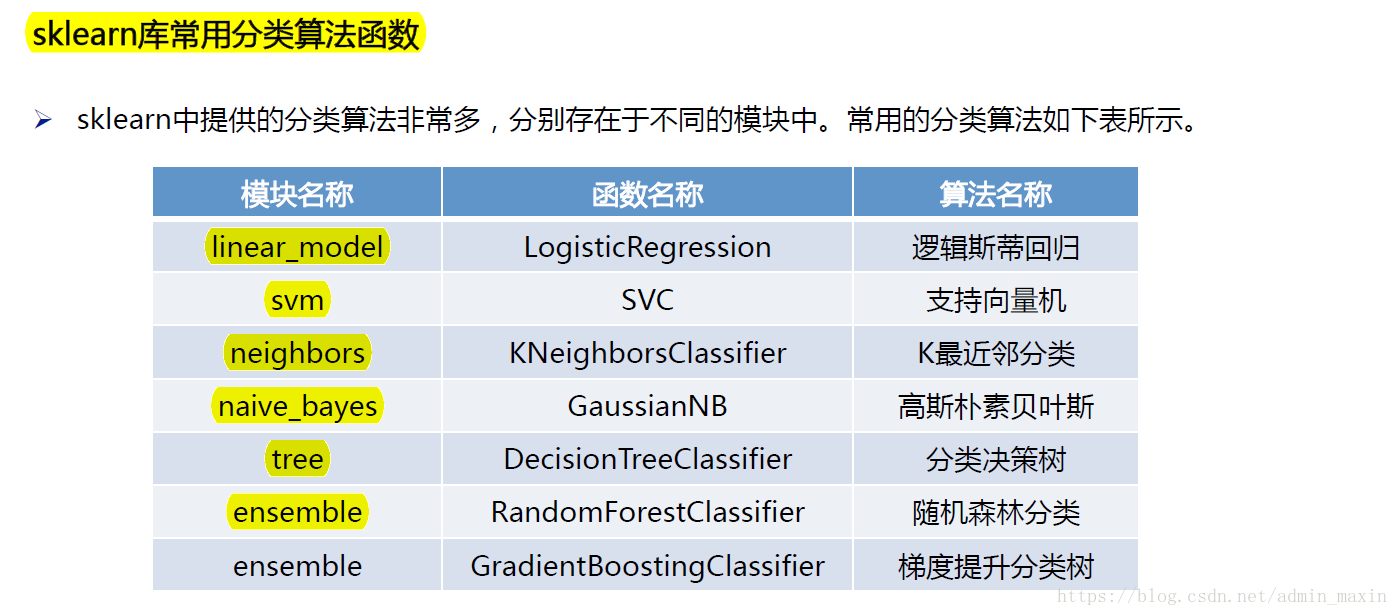
sklearn是一个机器学习的第三方库,在整个库当中提供了非常多的算法,tree(分类决策树)模块就是其中之一。
1.DecisionTreeClassifier
DecisionTreeClassifier是我们通常所说的决策树分类器,它是一个继承于BaseDecisionTree和ClassifierMixin类的子类
| 函数名 | 功能 |
|---|---|
| __init__ | 决策树分类器构造函数(内部实现是通过调用父类DecisionTreeClassifier中的构造函数实现的) |
| fit | |
| predict_proba | |
| predict_log_proba |
(一)__init__()函数说明
# --------------------class DecisionClassifier: def __init__():---------------------------#
# --重要参数
# --criterion="gini":划分属性的选择标准 gini(基尼系数) entropy(信息增益)
# --splitter="best": 在节点中选择分类的策略。 best(最好的分类) random(最好的随机分类)
# --max_depth=None: 树最大深度。
# --min_samples_split=2: 区分一个内部节点需要的最少的样本数
# --min_samples_leaf=1: 叶子结点所需要的最小样本数
# --min_weight_fraction_leaf=0.:一个叶节点的输入样本所需要的最小的加权分数
# --max_features=None:分类时需要考虑的特征数
# --random_state=None: 随机数字发生器种子。(用来保证输出结果的唯一性)
# --max_leaf_nodes=None: 在最优方法中使用max_leaf_nodes构建一个树.(通常跟max_depth配合使用)
# --min_impurity_decrease=0.: 如果该分裂导致杂质的减少大于或等于该值,则将分裂节点
# --min_impurity_split=None: 节点停止分裂的阙值
# --class_weight=None:与标点中的类所关联的标签的权重
# --presort=False: 是否预先分配数据以加快拟合中最佳分裂的发现(小型数据集适合设置为True)
from sklearn.tree import DecisionTreeClassifier
tr = DecisionTreeClassifier(criterion="gini")















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











