






深度学习技术在语义分割中的应用综述
摘要
这篇文章主要是对各种应用场景下,使用深度学习进行语义分割的方法的综述。论文中介绍的主要方面包括:
1)该领域的术语和必要的背景知识
2)主要数据集和竞赛的介绍,帮助研究者选择最适合他们的数据集
3)回顾现有方法,还有这些方法的贡献和重要性
4)以上方法和数据集对应的测试结果和评价
5)未来研究方向以及从当前最优的使用深度学习的语义分割技术得到的结论
1引言
和传统的计算机视觉和机器学习方法相比,深度学习的方法还不够成熟,缺少对当前工作的统一和对最好方法的综述。紧跟当前语义分割的相关工作,合理解释他们的论点,滤除掉一些低水平的工作同时验证相关的实验结果是必要但又是十分困难的。
他们工作的主要贡献包括:
1)针对现有的,对基于深度学习技术的分割项目有用的数据集进行了广泛的调查
2)对于使用深度学习技术的语义分割的最重要的方法进行了全面而有条理的回顾,包括它们的起源以及他们的贡献等。
3)使用多种指标,包括准确性、运行时间以及占用内存情况,做了全面的性能评估。
4)对前面提及结果的讨论,并给出了一系列可能在未来发展中存在优势的工作方向,以及对目前该领域最好方法的总结。
论文剩余部分的组织安排:
Section 2介绍了语义分割问题以及文献中常用的符号及术语,同时对常用的深度网络也进行了回顾。
Section 3介绍了现有的数据集,比赛以及标准。
Section 4基于它们的贡献,按照复杂度由低到高,对现有方法进行了回顾。这一部分主要是进行理论的介绍,而非进行定量评估。
Section 5基于它们在先前数据集的定量结果,对现有方法进行简短的讨论。
Section 6总结这篇论文,并且简述从这项工作以及该领域最好工作中所得到的结论。
2术语及背景概念
语义分割是实现精密推断的必经之路,它需要对每一个像素的标签进行预测。在这篇论文中,我们主要关注一般的场景标注,也就是像素级的分割,但同时也会对实例分割和基于部分的分割中最重要的方法进行简单回顾。
所谓的像素级别的标注问题,就是对随机变量集合中的每个随机变量,找到一种方法,为其指派一种来自标签空间的一种状态。每一种标签都代表一个不同的类别或物体,通常,背景也算一种标签。
2.1常见的深度网络架构
2.1.1 AlexNet
ILSVRC-2012获胜者,TOP-5准确度84.6%。
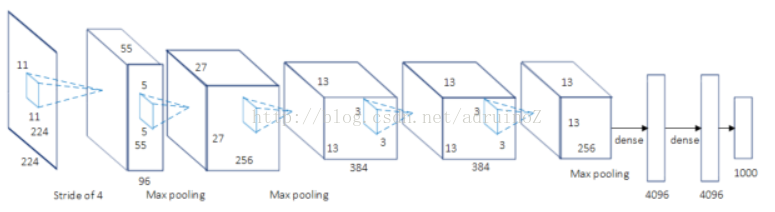
2.1.2 VGG
参加了ILSVRC-2013,TOP-5准确度92.7%。
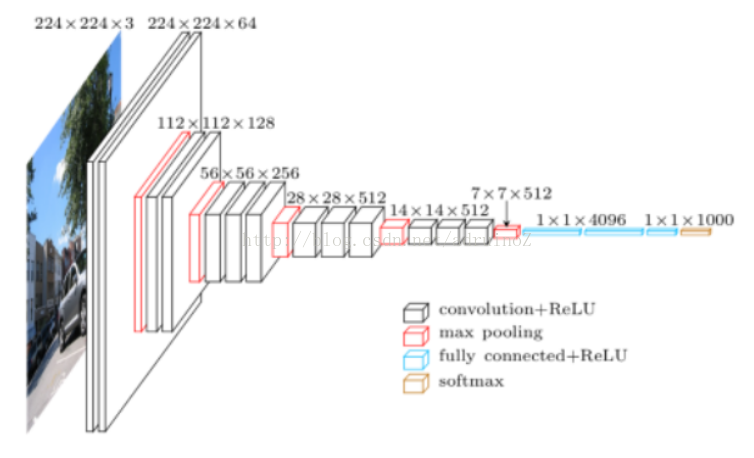
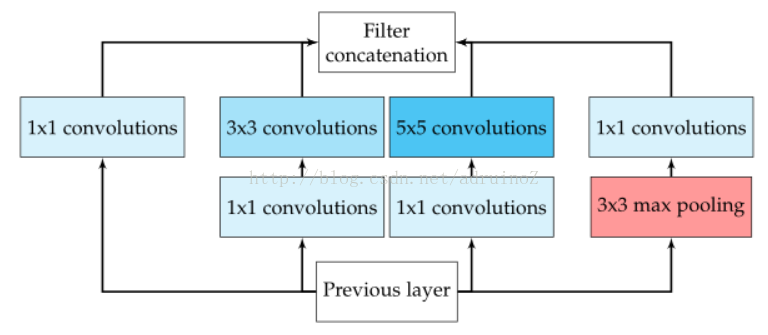
2.1.3 GoogLeNet
ILSVRC-2014获胜者,TOP-5准确度93.3%,引入了Inception module。
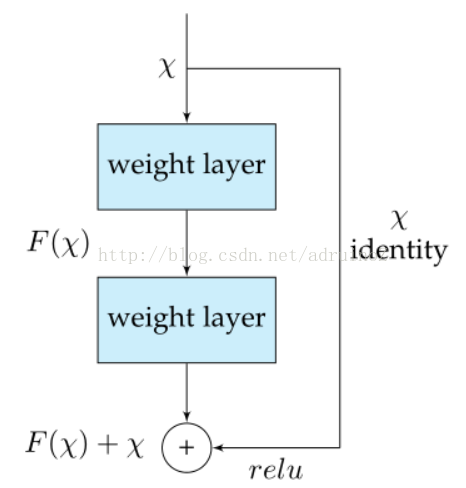
2.1.4 ResNet
ILSVRC-2016获胜者,TOP-5准确度96.4%,引入了Residual blocks。
2.1.5 ReNet
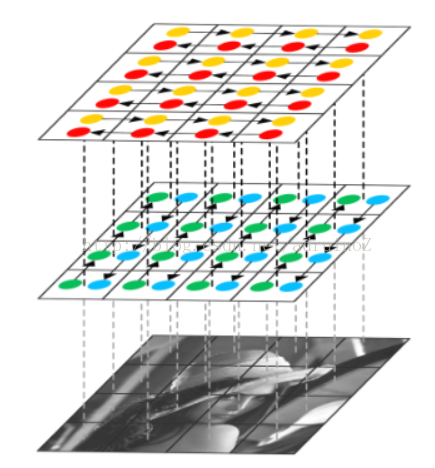
2.2迁移学习
迁移学习的一种主要的做法就是使用先前训练好的网络继续训练,对模型的权重值进行微调。即使是从不同的任务中迁移来的特征,也比直接随机初始化的特征要好。但一般不会对一个全新的网络结构进行迁移,使用现有的网络结构进行迁移学习是常见的。
2.3数据预处理和数据增强
有很多可用的转换方法来进行数据增强,包括平移、旋转、扭曲、缩放、颜色空间转换、裁剪等。这些方法的目标都是产生更多的样本来创造更大的数据集,从而防止过拟合的发生以及对模型进行正则化,对该数据集的各个类的大小进行平衡,甚至手工地产生对当前任务或应用场景更加具有代表性的新样本。
3数据集和竞赛
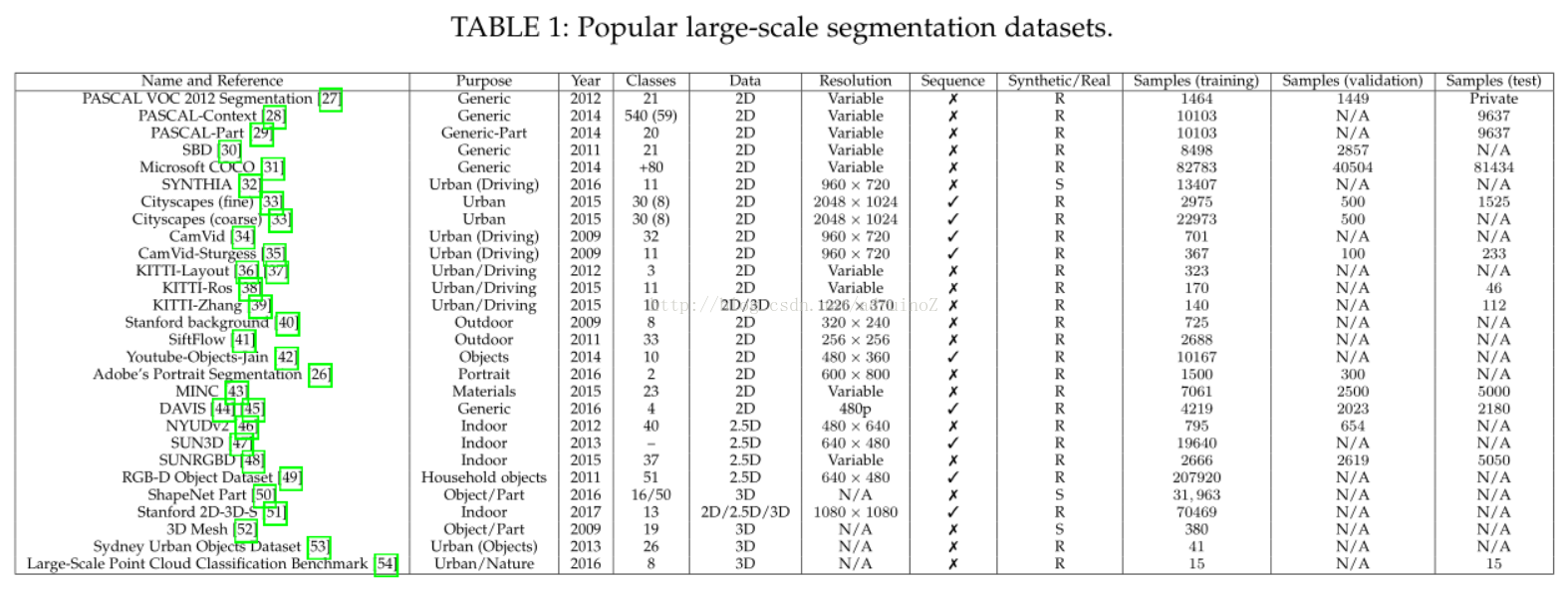
3.1 2D数据集
1)PASCAL Visual Object Classes (VOC)
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/
2)PASCAL Context
http://www.cs.stanford.edu/~roozbeh/pascal-context/
3)PASCAL Part
http://www.stat.ucla.edu/~xianjie.chen/pascal_part_dataset/pascal_part.html
4)Semantic Boundaries Dataset (SBD)
http://home.bharathh.info/home/sbd
5)Microsoft Common Objects in Context(COCO)
6)SYNTHetic Collection of Imagery and Annotations(SYNTHIA)
7)Cityscapes
https://www.cityscapes-dataset.com/
8)CamVid
http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/
9)KITTI
10)Youtube-Objects
11)Adobe’s Portrait Segmentation
http://xiaoyongshen.me/webpage_portrait/index.html
12)Materials in Context (MINC)
13)Densely-Annotated Video Segmentation (DAVIS)
http://davischallenge.org/index.html
14)Stanford background
http://dags.stanford.edu/data/iccv09Data.tar.gz
3.2 2.5D数据集
1)NYUDv2
http://cs.nyu.edu/~silberman/projects/indoor_scene_seg_sup.html
2)SUN3D
http://sun3d.cs.princeton.edu/
3)SUNRGBD
4)The Object Segmentation Database (OSD)
http://www.acin.tuwien.ac.at/?id=289
5)RGB-D Object Dataset
http://rgbd-dataset.cs.washington.edu/
3.3 3D数据集
1)ShapeNet Part
http://cs.stanford.edu/~ericyi/project_page/part_annotation/
2)Stanford2D-3D-S
http://buildingparser.stanford.edu/
3)A Benchmark for 3D Mesh Segmentation
http://segeval.cs.princeton.edu/
4)Sydney Urban Objects Dataset
http://www.acfr.usyd.edu.au/papers/SydneyUrbanObjectsDataset.shtml
5)Large-Scale Point Cloud ClassificationBenchmark
4方法

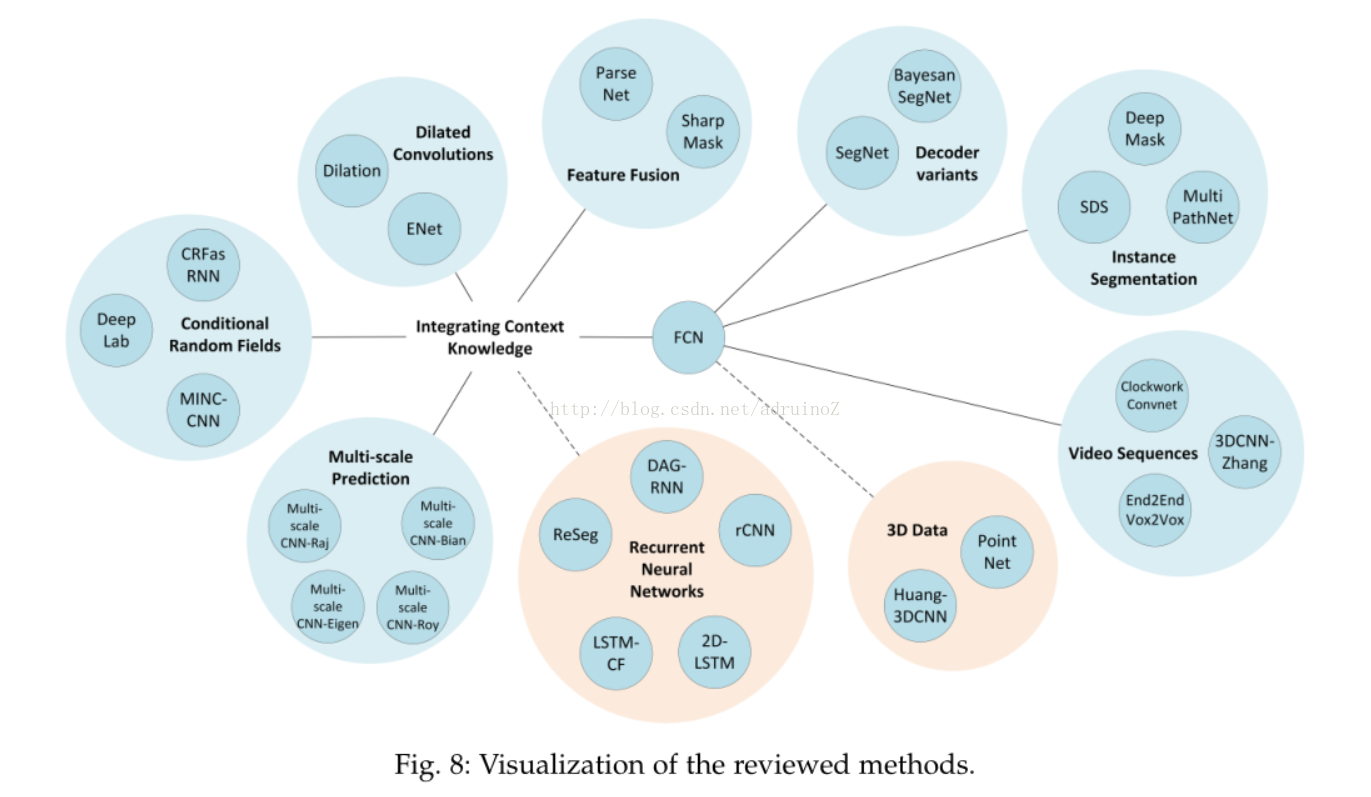
目前,最成功的基于深度学习的语义分割技术均是基于FCN,现有的比较有名的分类模型,包括AlexNet、VGG(16-layernet)、GoogLeNet和ResNet,将其全连接层换为卷积层,使其输出空间映射而非分类分数,即可得到全卷积网络的模型。
4.1解码器变体
一般而言,基于FCN的架构均选用一种分类网络,例如VGG-16,然后去掉其全连接层。得到的这个新的分割网络就叫做编码器,用来产生低分辨率的图像或特征映射。而在分割问题中,将低分辨率的图像映射到像素级别的预测上去,这一部分叫做解码器。
例如,对于SegNet,其解码器部分由一系列的上采样及卷积层组成,最终接上一个Softmax分类器来预测像素级别的标签,以此作为输出,可以达到与输入图像相同的分辨率。
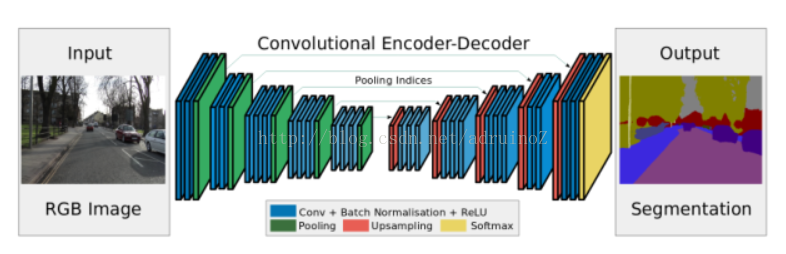
4.2整合环境知识
语义分割是一个需要对多种空间尺度信息进行整合的问题,它也意味着局部信息与全局信息的平衡。一方面,局部信息对于实现像素级别的精度是重要的,另一方面,整合图片的全局信息对于解决局部模糊性问题来说也是重要的。
4.2.1条件随机场
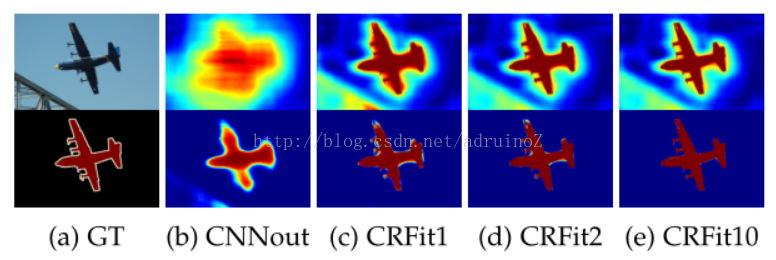
CRFs能够促进底层图像信息的结合,这种结合对于捕捉长期依赖性尤为重要,这也是善于捕捉细节信息的CNNs无法考虑到的。应用CRF对图像分割结果进行修正的算法有:DeepLab,CRFasRNN。
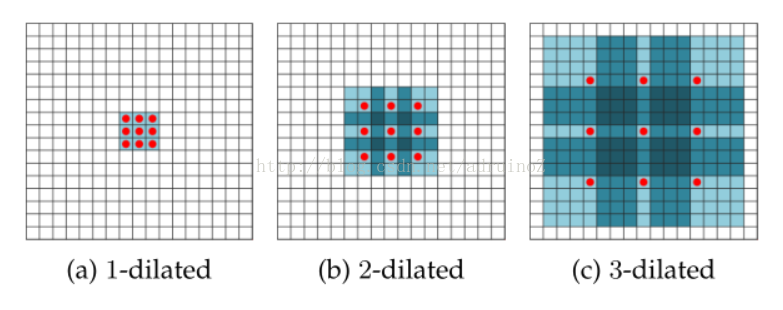
4.2.2扩张卷积
扩张卷积,又叫做`a-trous卷积,是对Kronecker-factored卷积核的一般化,它可以指数级扩大感受野而不损失精度。
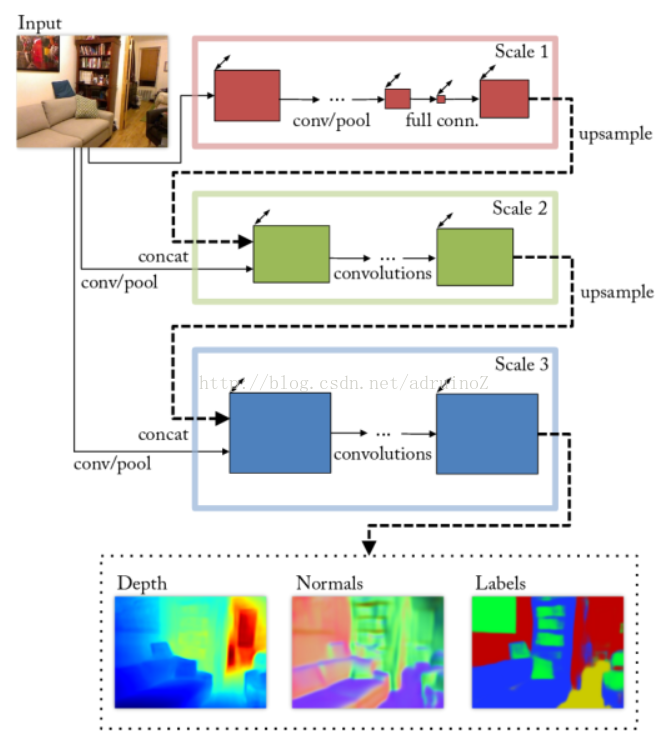
4.2.3多尺度预测
多尺度的网络一般都是选择处理多个不同尺度的网络,最后将他们的预测结果结合,产生一个单一的输出。
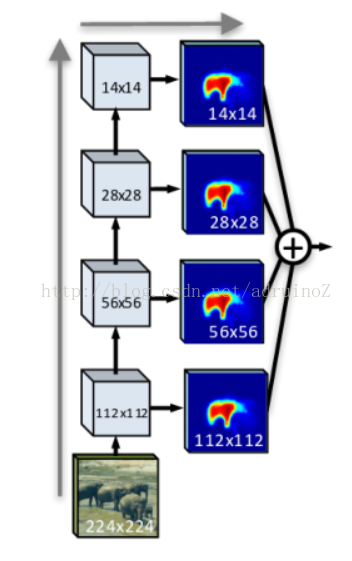
4.2.4特征融合
这种特征融合技术就是将来自于网络较前部分的全局特征与较深层次的局部特征相结合,常见的架构如原始FCN网络利用跳跃连接的方式进行延迟特征融合,也是通过将不用层产生的特征映射相结合来进行结果的预测。
4.2.5循环神经网络
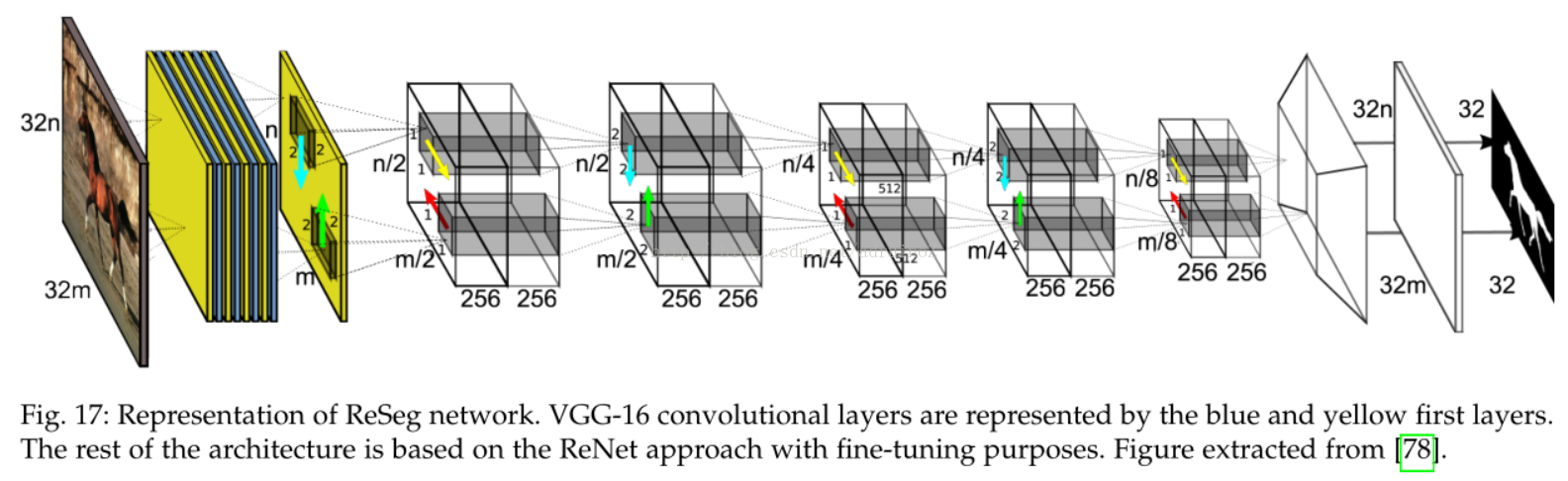
4.3实例分割
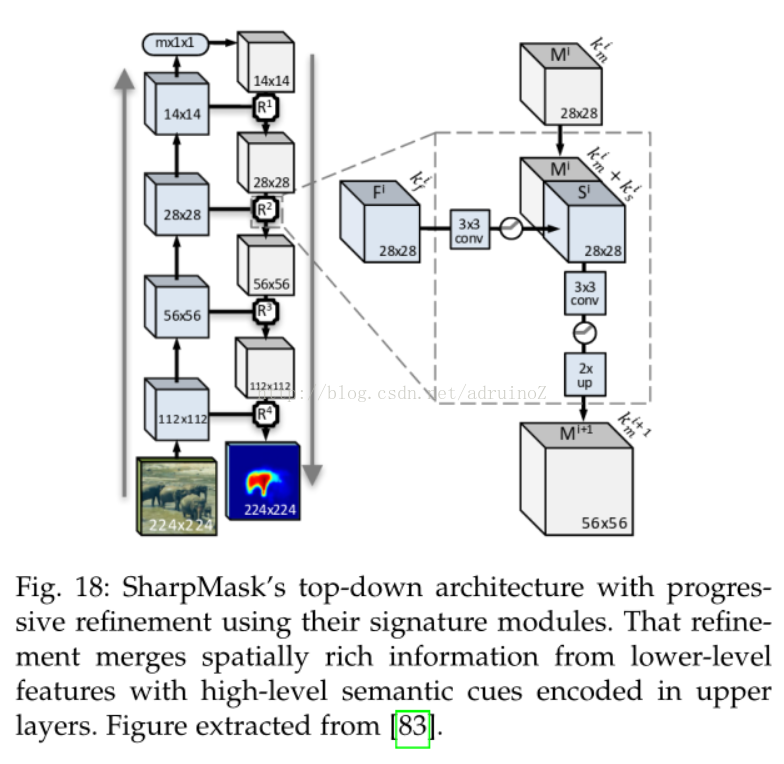
实例分割的主要目的是将同一个类别的不同物体分割为各个实例,它可以为我们分析遮挡情况提供额外信息,也可以输出统一类别中物体的个数。
4.4 RGB-D数据
廉价传感器的推广促进了结构化信息的使用,它可以提供来自于深度信息的有用的几何线索。我们可以向为RGB数据设计的模型中输入带有深度信息的图片,并通过结构化信息学习新的特征来提高模型性能。
4.5 3D数据
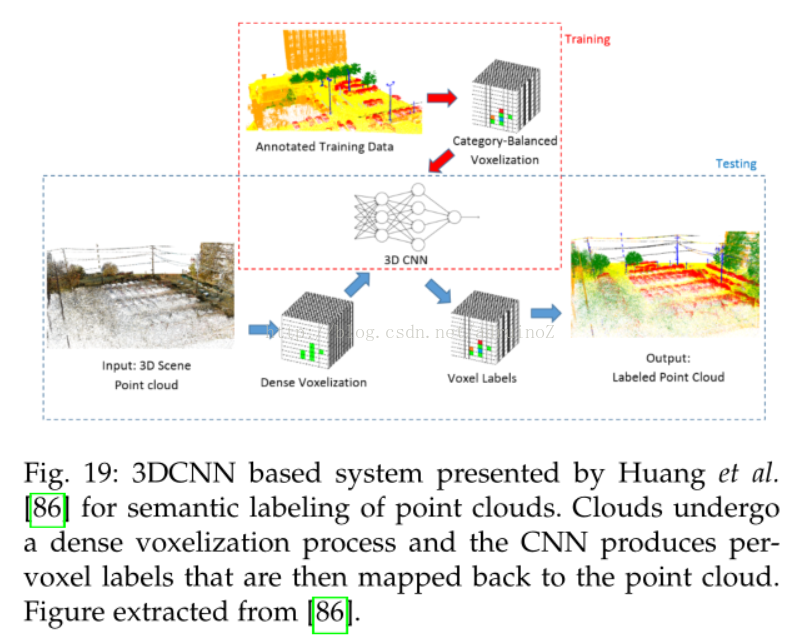
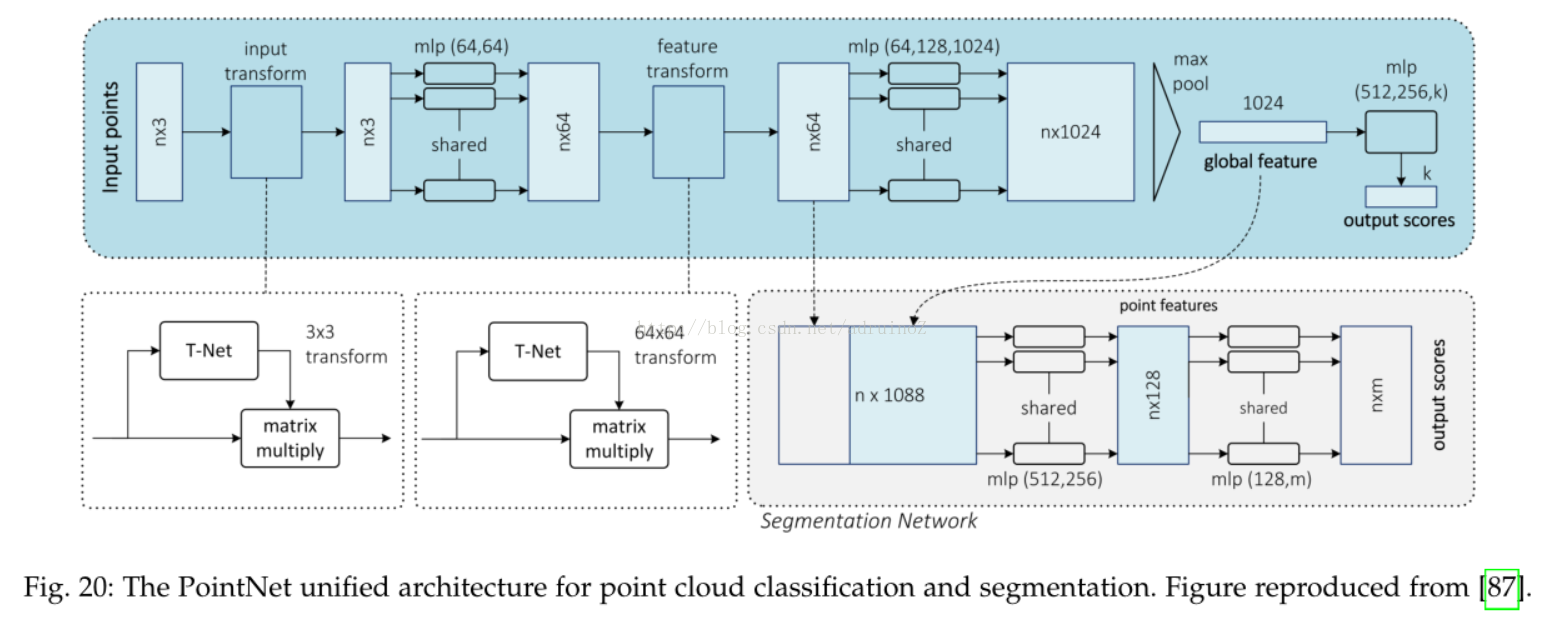
4.6视频序列
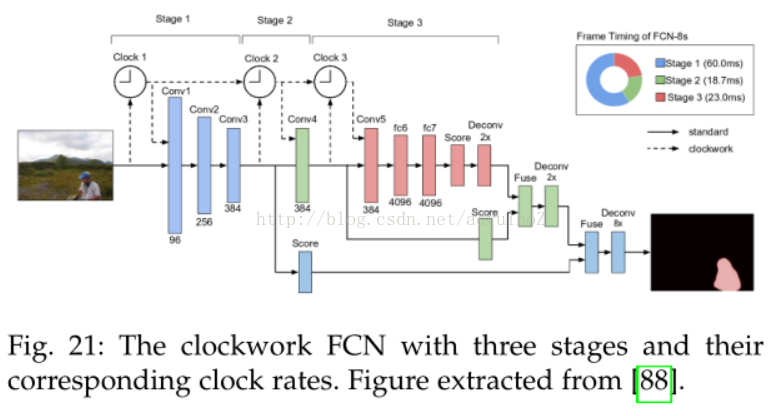
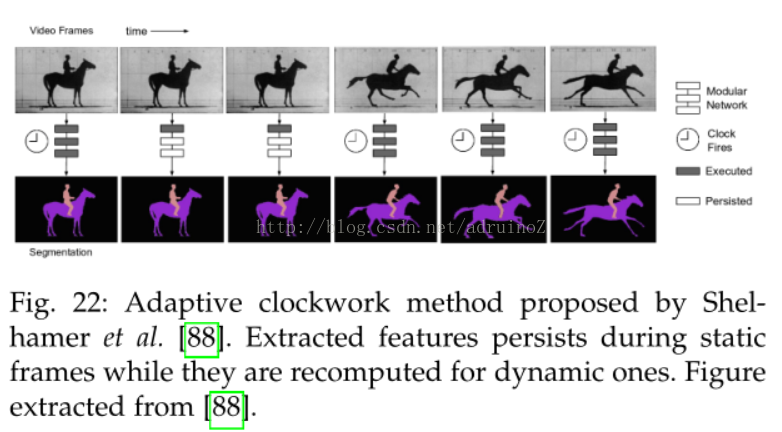
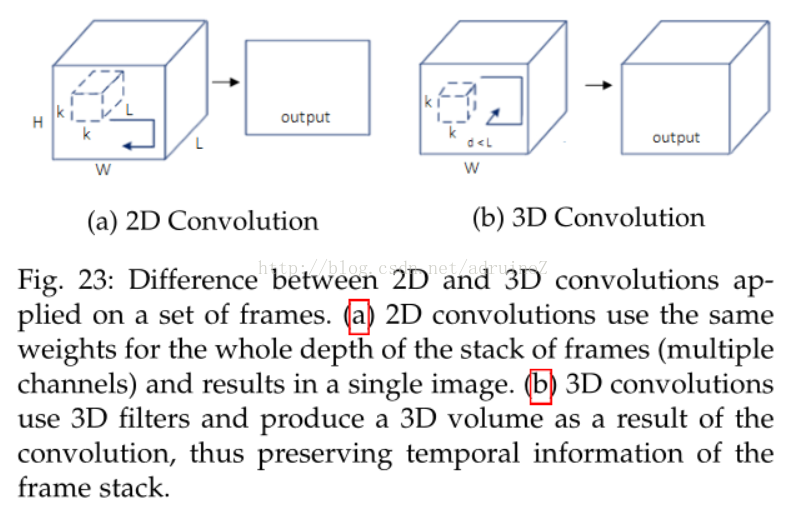
5讨论
5.1评价指标
5.1.1运行时间
5.1.2占用存储空间
5.1.3精度
我们假设一共有k+1类(从L0到Lk包括一个空类或背景),Pij是第i类被分到第j类的像素数量。
1)Pixel Accuracy (PA)
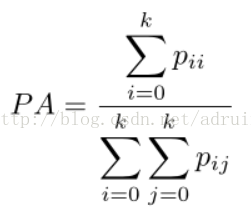
2)Mean Pixel Accuracy (MPA)
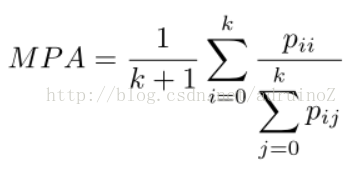
3)Mean Intersection over Union(MIoU)
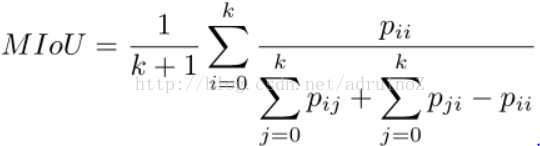
4)Frequency Weighted Intersectionover Union (FWIoU)
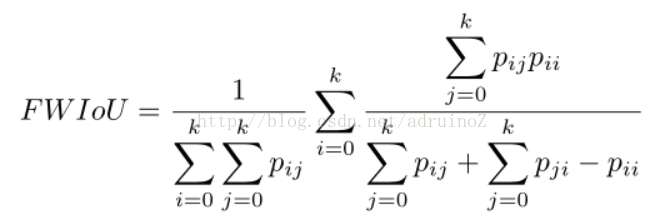
5.2结果
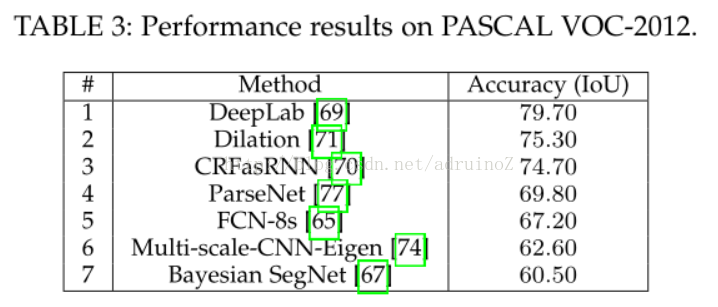
5.2.1 RGB
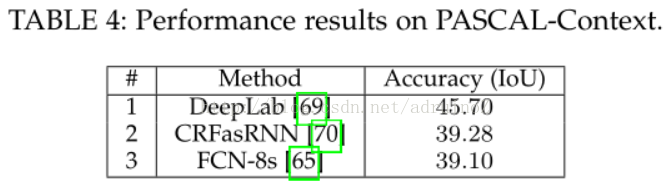


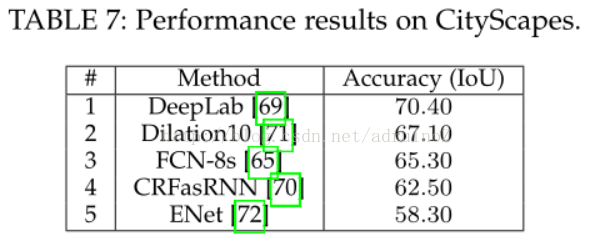

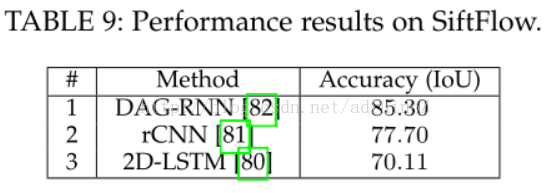
5.2.2 2.5D



5.2.3 3D
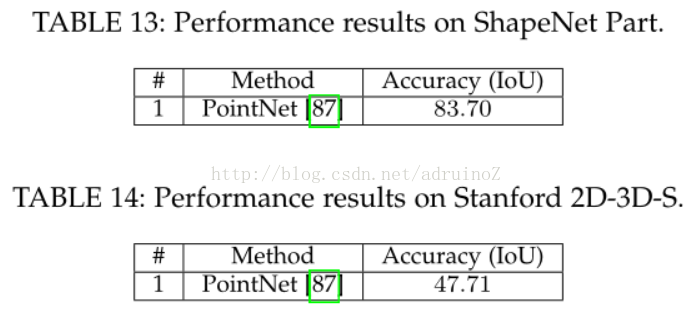
5.2.4序列
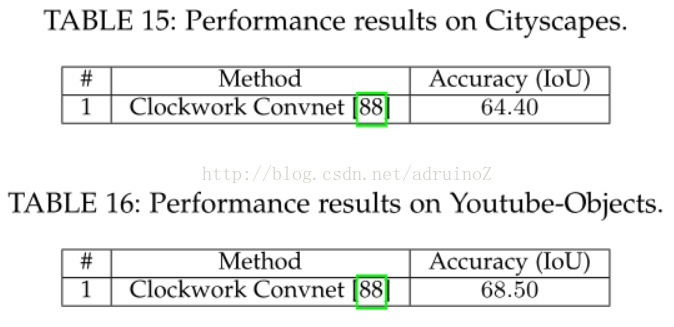
5.3总结
各种方法都应该公开它们在标准数据集上的训练结果,尽可能详细描述它们的训练过程,公开它们的模型和权重。
二维数据分割中,DeepLab是最可靠的方法,其在几乎每个RGB图像数据集上都远远超过了其他方法。2.5维和多模态数据集上,循环的网络如LSTM-CF起到了主导作用。三维数据的分割问题仍有很长的路要走,PointNet为解决无序点云的分割问题开辟了道路。最后,处理视频序列同样作为一个待开发区域,至今并没有明确的方向,但是,时钟卷积神经网络凭借其效率和准确率还是成为了最可靠的方法。由于其强大的功能及对多通道输入数据的可扩展性,三维卷积是值得关注的,且三维卷积可以同时捕获时间空间信息。
5.4未来研究方向
1)三维数据集
2)序列数据集
3)使用图卷积网络(GCN)对点云进行分割
4)上下文知识
5)实时分割
6)存储空间
7)序列数据的时间一致性
8)多视角整合
6结论
语义分割问题已经被很多不错的方法所解决,但是仍然存在着开放的问题,这些问题一旦解决将会对真实场景的应用产生较大的帮助。另外,深度学习技术被证明了对于解决语义分割问题的强大性,因此,我们期待接下来几年各种创新和研究的不断涌现。
参考资料
论文地址:https://arxiv.org/abs/1704.06857
论文翻译:http://www.cnblogs.com/Jie-Liang/p/6902375.html
论文概述:http://blog.csdn.net/u014451076/article/details/71101850














 106
106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









