







TiDB CDC
1.1 简介
TiCDC 是一款通过拉取 TiKV 变更日志实现的 TiDB 增量数据同步工具,具有将数据还原到与上游任意 TSO 一致状态的能力,同时提供开放数据协议 (TiCDC Open Protocol),支持其他系统订阅数据变更。
1.1.1 TiCDC 架构
TiCDC 运行时是一种无状态节点,通过 PD 内部的 etcd 实现高可用。TiCDC 集群支持创建多个同步任务,向多个不同的下游进行数据同步。
TiCDC 的系统架构如下图所示:
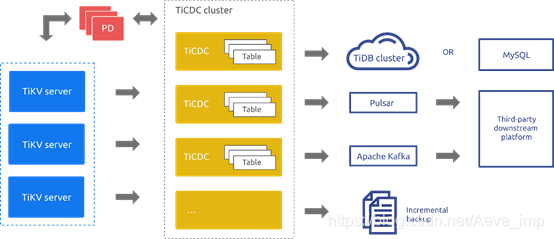
1.1.2系统角色
TiKV CDC 组件:只输出 key-value (KV) change log。
- 内部逻辑拼装 KV change log。
- 提供输出 KV change log 的接口,发送数据包括实时 change log 和增量扫的 change log。
Capture:TiCDC 运行进程,多个 capture 组成一个 TiCDC 集群,负责 KV change log 的同步。
- 每个 capture 负责拉取一部分 KV change log。
- 对拉取的一个或多个 KV change log 进行排序。
- 向下游还原事务或按照 TiCDC Open Protocol 进行输出。
1.1.3同步功能介绍
sink 支持:
- MySQL 协议兼容的数据库,提供最终一致性支持。
- 以 TiCDC Open Protocol 输出到 Kafka,可实现行级别有序、最终一致性或严格事务一致性三种一致性保证。
同步限制: TiCDC 只能同步至少存在一个有效索引的表,有效索引的定义如下:
- 主键 (PRIMARY KEY) 为有效索引。
- 同时满足下列条件的唯一索引 (UNIQUE INDEX) 为有效索引:
TiCDC 从 4.0.8 版本开始,可通过修改任务配置来同步没有有效索引的表,但在数据一致性的保证上有所减弱
暂不支持的场景:
- 暂不支持单独使用 RawKV 的 TiKV 集群
- 暂不支持 TiDB 4.0 中创建 SEQUENCE 的 DDL 操作 和 SEQUENCE 函数。在上游 TiDB 使用 SEQUENCE 时,TiCDC 将会忽略掉上游执行的 SEQUENCE DDL 操作/函数,但是使用 SEQUENCE 函数的 DML 操作可以正确地同步
- 暂不支持 TiKV Hibernate Region。TiCDC 会使 Region 无法进入静默状态
- 对上游存在较大事务的场景提供部分支持
1.2 安装部署
由于V4.0.9较好的支持了canal-json格式输出到kafka,本次环境搭建和测试是以V4.0.9环境和单机环境为基准的。
1.2.1 前期准备
- 执行如下命令安装 TiUP 工具:
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh - 按如下步骤设置 TiUP 环境变量:
source .bash_profile - 安装 TiUP cluster 组件
tiup cluster - 如果已经安装,则更新 TiUP cluster 组件至最新版本:
tiup update --self && tiup update cluster - 验证当前 TiUP cluster 版本信息。执行如下命令查看 TiUP cluster 组件版本:
tiup --binary cluster
1.2.2 配置模板
创建topo.yaml文件,其中包含了监控、tidb、tikv、pd、tiflash、cdc模块。
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/user/nb_wang/bin/tidb/tidb-deploy"
data_dir: "/data/user/nb_wang/bin/tidb/tidb-data"
# # Monitored variables are applied to all the machines.
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
server_configs:
tidb:
log.slow-threshold: 300
tikv:
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
pd:
replication.enable-placement-rules: true
replication.location-labels: ["host"]
tiflash:
logger.level: "info"
pd_servers:
- host: xxx
tidb_servers:
- host: xxx
tikv_servers:
- host: xxx
port: 20160
status_port: 20180
config:
server.labels: { host: "logic-host-1" }
- host: xxx
port: 20161
status_port: 20181
config:
server.labels: { host: "logic-host-2" }
- host: xxx
port: 20162
status_port: 20182
config:
server.labels: { host: "logic-host-3" }
cdc_servers:
- host: xxx
port: 8300
deploy_dir: "/data/user/nb_wang/bin/tidb/tidb-deploy/cdc-8300"
log_dir: "/data/user/nb_wang/bin/tidb/tidb-deploy/cdc-8300/log"
- host: xxx
port: 8301
deploy_dir: "/data/user/nb_wang/bin/tidb/tidb-deploy/cdc-8301"
log_dir: "/data/user/nb_wang/bin/tidb/tidb-deploy/cdc-8301/log"
monitoring_servers:
- host: xxx
grafana_servers:
- host: xxx
1.2.3 部署启动
1.部署
tiup cluster deploy tidb-test v4.0.9 ./topo.yaml --user root –i /root/.ssh/id_rsa
2.查看集群状况
tiup cluster list
3.检查部署情况
tiup cluster display tidb-test
4.启动集群
tiup cluster start tidb-test
5.验证集群状态
tiup cluster display tidb-test
6.使用mysql客户端登录验证
mysql -u root -h xxx -P 4000
1.3 创建CDC同步任务和验证
同步任务可以同步至mysql、tidb、kafka,这里测试采用sink to kafka。
Sink to kafka 包含四种数据格式:default(open protocol),avro、canal、maxwell。
- default(open protocol)
TiCDC Open Protocol 是一种行级别的数据变更通知协议,为监控、缓存、全文索引、分析引擎、异构数据库的主从复制等提供数据源。TiCDC 遵循 TiCDC Open Protocol,向 MQ(Message Queue) 等第三方数据媒介复制 TiDB 的数据变更
格式如下:需单独解析(官网有demo,但是不建议在生产使用)
1. [partition=0] [key="{\"ts\":415508856908021766,\"scm\":\"test\",\"tbl\":\"t1\",\"t\":2}"] [value="{\"q\":\"CREATE TABLE test.t1(id int primary key, val varchar(16))\",\"t\":3}"]
2. [partition=0] [key="{\"ts\":415508856908021766,\"t\":3}"] [value=]
3. [partition=1] [key="{\"ts\":415508856908021766,\"scm\":\"test\",\"tbl\":\"t1\",\"t\":2}"] [value="{\"q\":\"CREATE TABLE test.t1(id int primary key, val varchar(16))\",\"t\":3}"]
4. [partition=1] [key="{\"ts\":415508856908021766,\"t\":3}"] [value=]
- canal
本次测试使用canal格式,且在V4.0.9版本增加了canal-json格式,即将CDC变更数据以canal格式的json字符串进行数据到wkafka。无需二次解析,方便快捷。下面的同步操作以canal-json为基准。
1.3.1 同步任务相关指令
- 创建同步任务,指定配置文件
tiup ctl cdc changefeed create --pd=http://xxx:2379 \
--sink-uri="kafka://xxx:9092/test_cdc_canal_json?kafka-version=0.11.0.2&partition-num=1&max-message-bytes=67108864&replication-factor=1" \
--changefeed-id="cdc-kafka-canal-json" \
--sort-engine="memory" \
--config cdc_canal_json.conf
- 配置文件内容
# 指定配置文件中涉及的库名、表名是否为大小写敏感
# 该配置会同时影响 filter 和 sink 相关配置,默认为 true
case-sensitive = true
# 是否输出 old value,从 v4.0.5 开始支持,从 v5.0.0-rc 开始默认为 true
enable-old-value = true
[filter]
# 忽略指定 start_ts 的事务
ignore-txn-start-ts = [1, 2]
# 过滤器规则
# 过滤规则语法:https://docs.pingcap.com/zh/tidb/stable/table-filter#表库过滤语法
rules = ['test*.*']
[mounter]
# mounter 线程数,用于解码 TiKV 输出的数据
worker-num = 1
[sink]
# 对于 MQ 类的 Sink,可以通过 dispatchers 配置 event 分发器
# 支持 default、ts、rowid、table 四种分发器,分发规则如下:
# - default:有多个唯一索引(包括主键)时按照 table 模式分发;只有一个唯一索引(或主键)按照 rowid 模式分发;如果开启了 old value 特性,按照 table 分发
# - ts:以行变更的 commitTs 做 Hash 计算并进行 event ���发
# - rowid:以所选的 HandleKey 列名和列值做 Hash 计算并进行 event 分发
# - table:以表的 schema 名和 table 名做 Hash 计算并进行 event 分发
# matcher 的匹配语法和过滤器规则语法相同
dispatchers = []
# 对于 MQ 类的 Sink,可以指定消息的协议格式
# 目前支持 default、canal、avro 和 maxwell 四种协议。default 为 TiCDC Open Protocol
protocol = "canal-json"
[cyclic-replication]
# 是否开启环形同步
enable = false
# 当前 TiCDC 的复制 ID
replica-id = 1
# 需要过滤掉的同步 ID
filter-replica-ids = [2,3]
# 是否同步 DDL
sync-ddl = true
- 查看changefeed状态
tiup ctl cdc changefeed list --pd=http://xxx:2379
tiup ctl cdc changefeed query -s --pd=http://xxx:2379 --changefeed-id=cdc-kafka-canal-json
- 查看processor状态
tiup ctl cdc processor list --pd=http://xxx:2379
tiup ctl cdc processor query --pd=http://xxx:2379 --changefeed-id=cdc-kafka-canal-json
1.4 测试CDC
- 建库
SQL:
create database testdb;
Kafka内容:
{"id":0,"database":"testdb","table":"","pkNames":null,"isDdl":true,"type":"QUERY","es":1612833986834,"ts":0,"sql":"create database testdb","sqlType":null,"mysqlType":null,"data":null,"old":null}
- 建表
SQL:
CREATE TABLE person ( id INT(11) primary key, name VARCHAR(255), birthday DATE );
Kafka内容:
{"id":0,"database":"testdb","table":"person","pkNames":null,"isDdl":true,"type":"CREATE","es":1612834082034,"ts":0,"sql":"CREATE TABLE person ( id INT(11) primary key, name VARCHAR(255), birthday DATE )","sqlType":null,"mysqlType":null,"data":null,"old":null}
- 插入数据
SQL:
INSERT INTO person VALUES("1","tom","20170912");
Kafka内容:
{"id":0,"database":"testdb","table":"person","pkNames":["id"],"isDdl":false,"type":"INSERT","es":1612834116884,"ts":0,"sql":"","sqlType":{"birthday":91,"id":-5,"name":12},"mysqlType":{"birthday":"date","id":"int","name":"varchar"},"data":[{"birthday":"2017-09-12","id":"1","name":"tom"}],"old":[null]}
- 插入数据2
SQL:
INSERT INTO person(id,name) VALUES("2","bob");
Kafka内容:
{"id":0,"database":"testdb","table":"person","pkNames":["id"],"isDdl":false,"type":"INSERT","es":1612834145534,"ts":0,"sql":"","sqlType":{"birthday":91,"id":-5,"name":12},"mysqlType":{"birthday":"date","id":"int","name":"varchar"},"data":[{"birthday":null,"id":"2","name":"bob"}],"old":[null]}
- 修改数据
SQL:
UPDATE person SET birthday="20180808" WHERE id=2;
Kafka内容:
{"id":0,"database":"testdb","table":"person","pkNames":["id"],"isDdl":false,"type":"UPDATE","es":1612834170784,"ts":0,"sql":"","sqlType":{"birthday":91,"id":-5,"name":12},"mysqlType":{"birthday":"date","id":"int","name":"varchar"},"data":[{"birthday":"2018-08-08","id":"2","name":"bob"}],"old":[{"birthday":null,"id":"2","name":"bob"}]}
- 删除数据
SQL:
DELETE FROM person WHERE id=2;
Kafka内容:
{"id":0,"database":"testdb","table":"person","pkNames":["id"],"isDdl":false,"type":"DELETE","es":1612834206234,"ts":0,"sql":"","sqlType":{"birthday":91,"id":-5,"name":12},"mysqlType":{"birthday":"date","id":"int","name":"varchar"},"data":[{"birthday":"2018-08-08","id":"2","name":"bob"}],"old":[{"birthday":"2018-08-08","id":"2","name":"bob"}]}
1.5 结论
通过上面canal-json输出的内容可以看到,每次DDL、DML时会抓取cdc变更日志推送到kafka、且会带有当前表的所有字段,如果是修改还会额外带着修改前的值,符合需求。














 412
412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









