







TiDB CDC
1.1 简介
之前做了TiDB的CDC功能测试,是为了测试TiDB的CDC功能是否满足我们的需求。
这次做了TiDB接入CDC后的性能测试,对比下之前未接cdc和tiflash是否会影响吞吐、延迟、以及看下cdc本身同步的延迟。
1.2 测试逻辑
- TiDB准备2张完全一样的表(都有主键,方便走cdc,都同步tiflash),一张走cdc,一张不走cdc(走不走cdc根据cdc同步任务时配置的过滤器有关)
- 准备另外一个表,记录每次插入两个表的耗时,不走cdc
- 创建tiflash同步任务,创建cdc同步任务
- 接入kafka测试数据,灌入TiDB(同一批次数据,既灌入走cdc,也灌入不走cdc的表,并记录两次耗时)
- 统计分析特定批次的平均耗时,比对两者延迟
- 将cdc to kafka的数据同步到clickhouse或者其他组件,分析cdc延迟(cdc使用canal-json格式,其中es是数据库处理时间,再获取进入kafka时间,两个时间相减获取同步延迟)
- 将cdc同步任务线程数增加或减少,分析线程数对同步延迟的影响
1.3 POC测试
-
本次POC测试机器3台,配置:4核/16g内存/500g硬盘,集群规划如下:

-
机器之间配置SSH免密登录、关闭防火墙、最好使用root安装。
-
本次POC测试是基于V4.0.10版本的,主要是使用cdc的canal-json格式
1.3.1 集群搭建
准备:
- 使用命令安装 TiUP 工具:
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh - 按如下步骤设置 TiUP 环境变量:
source .bash_profile - 安装 TiUP cluster 组件
tiup cluster - 如果已经安装,则更新 TiUP cluster 组件至最新版本:
tiup update --self && tiup update cluster - 验证当前 TiUP cluster 版本信息。执行如下命令查看 TiUP cluster 组件版本:
tiup --binary cluster
部署集群和启动:
- 配置集群配置文件, topology.yaml
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb-deploy"
data_dir: "/data/tidb-data"
# # Monitored variables are applied to all the machines.
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
# deploy_dir: "/tidb-deploy/monitored-9100"
# data_dir: "/tidb-data/monitored-9100"
# log_dir: "/tidb-deploy/monitored-9100/log"
server_configs:
tidb:
log.slow-threshold: 300
tikv:
readpool.storage.use-unified-pool: false
readpool.coprocessor.use-unified-pool: true
pd:
schedule.leader-schedule-limit: 4
schedule.region-schedule-limit: 2048
schedule.replica-schedule-limit: 64
replication.enable-placement-rules: true
tiflash:
# Maximum memory usage for processing a single query. Zero means unlimited.
profiles.default.max_memory_usage: 0
# Maximum memory usage for processing all concurrently running queries on the server. Zero means unlimited.
profiles.default.max_memory_usage_for_all_queries: 0
pd_servers:
- host: xxx
- host: xxx
- host: xxx
tidb_servers:
- host: xxx
- host: xxx
tikv_servers:
- host: xxx
- host: xxx
- host: xxx
tiflash_servers:
- host: xxx
- host: xxx
- host: xxx
cdc_servers:
- host: xxx
port: 8300
deploy_dir: "/data/tidb-deploy/cdc-8300"
log_dir: "/data/tidb-deploy/cdc-8300/log"
- host: xxx
port: 8300
deploy_dir: "/data/tidb-deploy/cdc-8300"
log_dir: "/data/tidb-deploy/cdc-8300/log"
monitoring_servers:
- host: xxx
grafana_servers:
- host: xxx
2.部署
tiup cluster deploy cdc-test v4.0.10 ./topology.yaml --user root
3.查看集群状况
tiup cluster list
4.检查部署情况
tiup cluster display cdc-test
5.启动集群
tiup cluster start cdc-test
6.验证集群状态
tiup cluster display cdc-test
7.使用mysql客户端登录验证
mysql -u root -h 10.18.254.42 -P 4000
1.3.2 创建CDC同步任务和验证
- 创建同步任务,指定配置文件
tiup ctl cdc changefeed create --pd=http://10.18.255.83:2379 \
--sink-uri="kafka://xxx:9092,xxx:9092,xxx:9092/temp_tidb_poc_20120219?kafka-version=0.11.0.2&max-message-bytes=1073741824&replica.fetch.max.bytes=1073741824&fetch.message.max.bytes=1073741824&partition-num=10" \
--changefeed-id="cdc-kafka-canal-json" --sort-engine="memory" --config cdc_canal_json.conf
- 配置文件内容
# 指定配置文件中涉及的库名、表名是否为大小写敏感
# 该配置会同时影响 filter 和 sink 相关配置,默认为 true
case-sensitive = true
# 是否输出 old value,从 v4.0.5 开始支持,从 v5.0.0-rc 开始默认为 true
enable-old-value = true
[filter]
# 忽略指定 start_ts 的事务
ignore-txn-start-ts = [1, 2]
# 过滤器规则
# 过滤规则语法:https://docs.pingcap.com/zh/tidb/stable/table-filter#表库过滤语法
rules = ['test*.cdc*']
[mounter]
# mounter 线程数,用于解码 TiKV 输出的数据
worker-num = 6
[sink]
# 对于 MQ 类的 Sink,可以通过 dispatchers 配置 event 分发器
# 支持 default、ts、rowid、table 四种分发器,分发规则如下:
# - default:有多个唯一索引(包括主键)时按照 table 模式分发;只有一个唯一索引(或主键)按照 rowid 模式分发;如果开启了 old value 特性,按照 table 分发
# - ts:以行变更的 commitTs 做 Hash 计算并进行 event ���发
# - rowid:以所选的 HandleKey 列名和列值做 Hash 计算并进行 event 分发
# - table:以表的 schema 名和 table 名做 Hash 计算并进行 event 分发
# matcher 的匹配语法和过滤器规则语法相同
dispatchers = [
{matcher = ['test*.cdc*'], dispatcher = "rowid"},
]
# 对于 MQ 类的 Sink,可以指定消息的协议格式
# 目前支持 default、canal、avro 和 maxwell 四种协议。default 为 TiCDC Open Protocol
protocol = "canal-json"
[cyclic-replication]
# 是否开启环形同步
enable = false
# 当前 TiCDC 的复制 ID
replica-id = 1
# 需要过滤掉的同步 ID
filter-replica-ids = [2,3]
# 是否同步 DDL
sync-ddl = true
- 查看changefeed状态
tiup ctl cdc changefeed list --pd=http://xxx:2379
tiup ctl cdc changefeed query -s --pd=http://xxx:2379 --changefeed-id=cdc-kafka-canal-json
- 查看processor状态
tiup ctl cdc processor list --pd= http://xxx:2379
tiup ctl cdc processor query --pd= http://xxx:2379 --changefeed-id=cdc-kafka-canal-json
- 我这里因为需要测试cdc同步线程数的影响,所以我同时起了3个cdc同步任务,一个使用了3线程,一个使用6线程,一个使用12线程
- 这里需要注意的是kafka的连接参数上最好带上max-message-bytes=1073741824&replica.fetch.max.bytes=1073741824&fetch.message.max.bytes=1073741824&partition-num=10这三个配置参数,并且调大,防止cdc同步kafka时一次性发送大量数据导致被broker拒绝而失败
- 可以看到此配置文件只会cdc同步test开头的库,且是cdc开头的表,所以我们之前创建的表,cdc_download会走cdc,而download表和timing表则不会走cdc
1.3.3 创建TiFlash同步任务
- 为了测试公平,应该给两张表都增加同步TiFlash任务
- 创建TiFlash同步任务
ALTER TABLE testdb.download SET TIFLASH REPLICA 2;
ALTER TABLE testdb.cdc_download SET TIFLASH REPLICA 2;
1.3.4 启动kafka消费程序往TiDB灌测试数据
- 启动自己的kafka消费程序,将大批量数据持续灌入TiDB中,观察耗时
- 连接TiDB,可以直接使用jdbc连接,走4000端口,批量插入
- 走批量插入时,在jdbc的连接上加入rewriteBatchedStatements=true参数,不然即使使用executeBatch的API,也只是把请求暂存本地,然后一次性发给tidb,tidb也是一条一条插入,而加入上面的参数,是把请求暂存本地,且优化插入sql语句,一次性发送,tidb也是一次性插入
- 我这里控制了每1w条数据批量插入download表,也插入cdc_download表,并向timing表记录这两次的耗时
1.3.5 启动kafka消费程序接收CDC数据写入DB
- 我这里是接CDC流入的kafka数据,持久化到CK中方便统计分析了
1.4 结论
1.4.1 观察和统计分析Timing表延迟
- 我这里统计分析了当数据达到一定量级时的开启cdc和未开启cdc的耗时,如下:
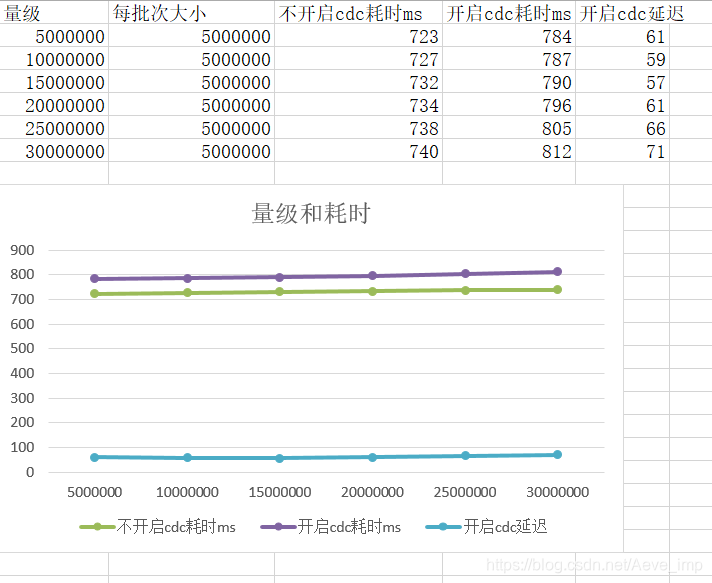
- 从上图可以看到,当量级从500w上升到3000w的过程中,开启cdc和不开启cdc都没有特别明显的增加延迟,且插入tidb延迟都在1s以内。
- 可以看到,开启cdc后,确实比不开启cdc耗时要增加,大概60ms,且随着量级的增加这个延迟也并没有大幅增加。
- 结论:开启CDC的延迟并没有明显的增加,在可接受范围内,符合需求
1.4.2 观察和统计分析CDC同步延迟
- 我这里是将CDC同步到kafka后的数据持久化到CK中进行统计分析,如下:
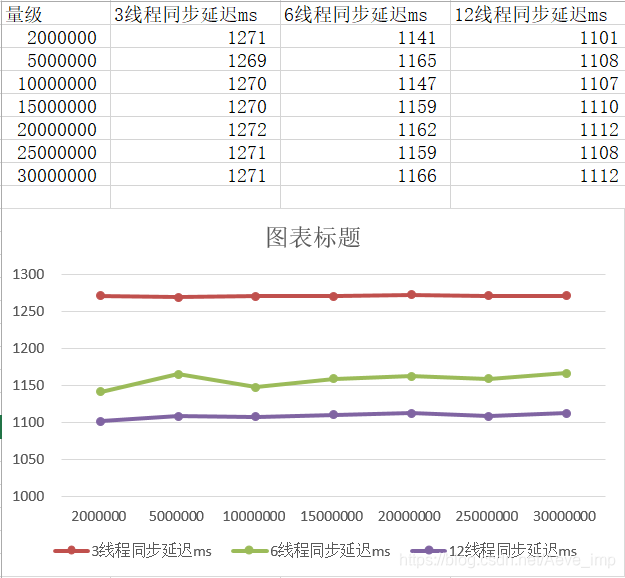
- 从上图可以看到,当量级从200w上升到3000w的过程中,使用3线程,6线程,12线程的同步延迟大概是在1s左右,且三者随着数据量级的增加都没有明显的加大延迟。
- 可以看到,随着cdc同步线程数的增加,确实会减少同步延迟,虽然不是很明显,但是是有提升的。
- 结论:CDC的同步延迟大概是在1s左右,且增加线程是可以减少同步延迟的,符合需求














 415
415











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









