







链式存取的基本结构是:
typedef struct Lnode{
ElemType data;
struct Lnode *next;
}ListSq,*Linklist; //其中定义两种表示方式是为了再后来分配空间时方便操作
//因为在实际应用中带头结点的链表更易于操作所以经常建表时令头结点不带关键字
建表的时候注意是逆序建表还是顺序建表两者的算法不同
//逆序建表
void CreateList_L(LinkList &L, int n)
{ L = (LinkList) malloc (sizeof (LNode));
L->next = NULL; //建立一个带头结点的单链表
for (i = n; i>0; --i)
{ p = (LinkList) malloc (sizeof (LNode));//生成新结点
scanf(&p->data); //插入元素值
p->next = L->next;
L->next = p;} //插入到表头
}
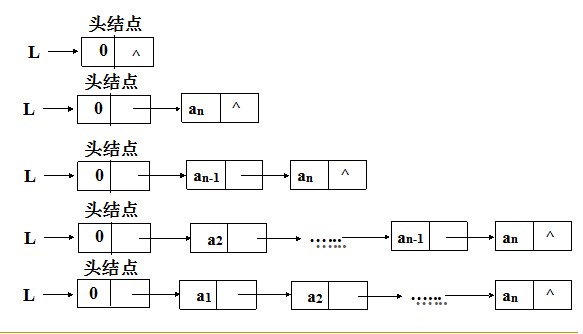
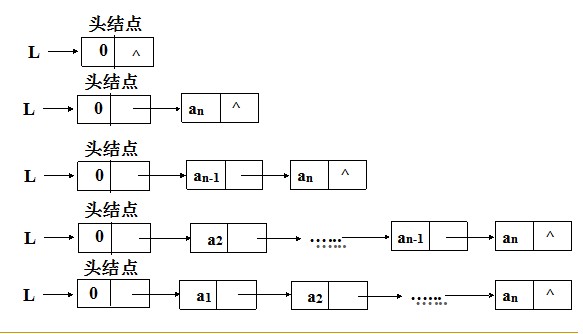
一下是顺序建表的算法及过程
void CreateList_L(LinkList &L, int n)
{ LinkList p,q; //其中q为辅助记录表尾的指针
int n;
L = (LinkList) malloc (sizeof (LNode));
L->next = NULL; //建立一个带头结点的单链表
q = L;
for (i = 0; i < n; i++)
{ p = (LinkList) malloc (sizeof (LNode)); //生成新结点
scanf(“%d”,&p->data); //插入元素值
q->next = p;
p->next = NULL; //插入到表尾
q = p;} //q始终指向表尾
}
再下来是其他几种类型的链表如循环链表,双向链表。
循环链表:区别在于可以在任意一个结点都可以遍历所有元素,而且在空表的判断方面也有所不同,其他基本一致。

双向链表:从一个结点就可以遍历所有结点而且很方便,分别有前驱和后继的特点。
结构如下
typedef struct node {
struct node * prior,*next;
ElemType data;
}JD;
//可以参考插入操作来理解双向链表算法如下
//插入一个元素
void ins_dulist(JD* p,int x)
{ JD *s;
s=(JD*)malloc(sizeof(JD));
s->element=x;
s->prior=p->prior;//s的前驱是p的前驱先保存好
p->prior->next=s;//找到p的前驱改变其next为s
s->next=p; //改变s的next
p->prior=s;//改变p的前驱
}
//删除一个元素
void del_dulist(JD *p)
{ p->prior->next=p->next;
p->next->prior=p->prior;
free(p);
} 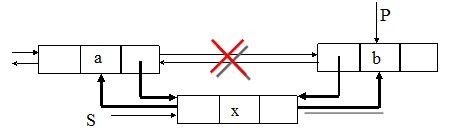
插入一个元素
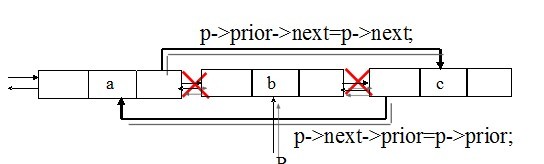
删除一个元素
其他的链表操作如 链表的逆置和链表的遍历查找等暂时保留更新















 1233
1233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









