






六.调试代码
针对提取详细数据的代码,如果每次都debug调试,看是否能够正确的提取出来,则会发过多的请求.
scrapy提供一种方法,可以直接调试

当程序运行到此处时会阻塞,这时你可以尽情的调试。当调试完成后按Ctrl-D(Windows下Ctrl-Z)退出后继续运行,当下一次运行此处时又会阻塞在这里供你调试
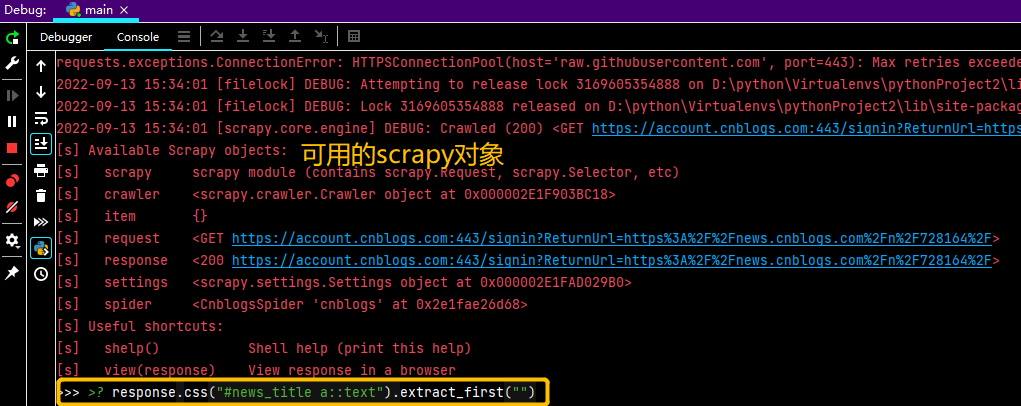
另外,在cmd命令行输入scrapy shell 网址也可以实现相同的调试目的,将可以正确提取数据的代码拷贝到程序中
如果要在程序中debug,则不需要yield太多的url给scrapy,只需一个url即可 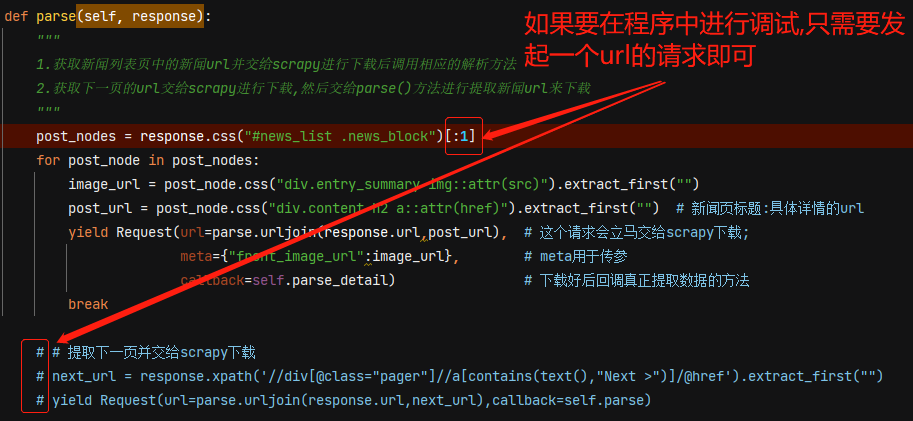
补充一个小知识点:
#针对动态网页,评论数点赞数等需要分析出url重新请求,来获取数据
html = requests.get(parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)))
#1.这是一个同步的代码,会等待结果返回后在往下执行,优点在于好理解,但一般不用在异步框架scrapy中
#2./NewsAjax...这里前面加/号,则会拼接在主域名下面,如果没有加/号,则拼接在该url下面
def parse_detail(self, response):
match_re = re.match(".*?(\d+)", response.url) #提取url最后面的id
if match_re: #有id值才是真正的文章,不是中间插入的广告
post_id = match_re.group(1) #文章id
title = response.css("#news_title a::text").extract_first("") #标题
create_data = response.css("#news_info .time::text").extract_first("")
match_re = re.match(".*?(\d+.*)", create_data)
if match_re:
create_date = match_re.group(1) #发布日期
content = response.css("#news_content").extract()[0] #文章内容
tag_list = response.css(".news_tags a::text").extract()
tags = ",".join(tag_list) #标签
#同步请求代码,在并发要求不是很高时可以采用
html = requests.get(parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)))
j_data = json.loads(html.text)
praise_nums = j_data["DiggCount"] # 点赞数
fav_nums = j_data["TotalView"] # 查看数
comment_nums = j_data["CommentCount"] # 评论数
七.items组件
items可以解决字段过多时的,用于承载数据,在各个方法/组件中统一传递数据的问题;
class CnblogsArticleItem(scrapy.Item):
title = scrapy.Field() # 标题
create_date = scrapy.Field() # 发布日期
url = scrapy.Field()
url_object_id = scrapy.Field() # url的MD5生成,把url限定在一定的长度内,作为数据库主键
front_image_url = scrapy.Field() # 图片url(scrapy可自动下载)
front_image_path = scrapy.Field() # 图片下载在电脑上的路径
praise_nums = scrapy.Field() # 点赞数
comment_nums = scrapy.Field() # 评论数
fav_nums = scrapy.Field() # 查看数
tags = scrapy.Field() # 标签
content = scrapy.Field() # 文章内容
from ArticleSpider.items import CnblogsArticleItem
...
def parse_detail(self, response):
article_item = CnblogsArticleItem()
...
article_item["title"] = title
article_item["create_date"] = create_date
article_item["content"] = content
article_item["tags"] = tags
article_item["url"] = response.url
# 重要:通过scrapy自动下载图片,这个存储图片url的值一定要是一个列表,如果列表有多个值,scrapy就会循环把图片全部下载下来
article_item["front_image_url"] = [response.meta.get("front_image_url", "")]
# 通过article_item传递数据
yield Request(url=parse.urljoin(response.url, "/NewsAjax/GetAjaxNewsInfo?contentId={}".format(post_id)),
meta={"article_item": article_item}, callback=self.parse_nums)
# 处理动态网页的数据提取,将article_item传递进来并填充数据
def parse_nums(self, response):
j_data = json.loads(response.text)
# 通过article_item取出数据
article_item = response.meta.get("article_item", "")
praise_nums = j_data["DiggCount"]
fav_nums = j_data["TotalView"]
comment_nums = j_data["CommentCount"]
article_item["praise_nums"] = praise_nums
article_item["fav_nums"] = fav_nums
article_item["comment_nums"] = comment_nums
article_item["url_object_id"] = common.get_md5(article_item["url"]) # url的MD5生成,把url限定在一定的长度内,作为数据库主键
#已经将所有的值全部提取出来,存放于item中
yield article_item
scrapy任何地方都可以yield一个Request与item
yield Request可以交给scrapy去下载url
yield item可以交给pipelines做持久化操作
八.pipelines 管道
打开项目目录下settings.py文件
ITEM_PIPELINES = {
'ArticleSpider.pipelines.ArticlespiderPipeline': 300,
}
这是系统默认的配置,代表一个个"管道",路径是写在项目目录下pipelines.py中的类
class ArticlespiderPipeline(object):
def process_item(self, item, spider):
return item
每一个被yield出来的item,会依次进入这些管道类,执行process_item()方法,方法的参数item是scrapy注入进来的.
方法执行完毕后return item,item会进入下一个管道(顺序跟配置的数值有关),如果不return item,则不会在进来之后的pipelines.
一般在pipeline中做保存数据的处理;
以上,主要介绍了数据的提取,及携带数据的item的传递,传递到pipeline
九.如何让scrapy帮我们自动下载文件/图片
首先在settings.py中加上内置的pipeline,
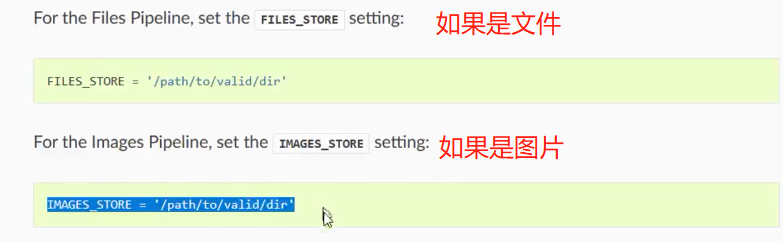
然后配置上存储的路径,
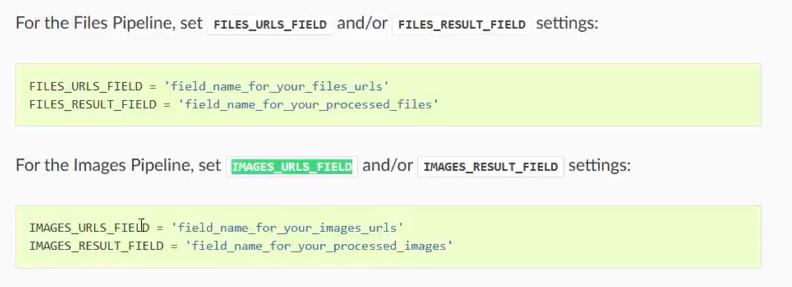
还需要指出存储图片url的字段(人家才知道去哪里下载)
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline': 1, # 1.内置的pipeline
}
IMAGES_URLS_FIELD = "front_image_url" # 3.指出存储图片url的字段(人家才知道去哪里下载)
project_dir = os.path.abspath(os.path.dirname(__file__))
IMAGES_STORE = os.path.join(project_dir, 'images') # 2.配置上存储的路径
注意点:
1.python环境中需要事先安装pillow
2.通过scrapy自动下载图片,这个存储图片url的字段值一定要是一个列表,如果列表有多个值,scrapy就会循环把图片全部下载下来
article_item["front_image_url"] = [response.meta.get("front_image_url", "")]
这样配置之后,默认的pipeline就会下载图片,并保存到对应的路径当中
3.如果我们需要存储文件的下载路径,则需要继承内置的pipeline,重写某个方法
#pipelines.py
class ArticleImagePipeline(ImagesPipeline):
def item_completed(self, results, item, info):
if "front_image_url" in item:
for ok, value in results:
image_file_path = value["path"] ###
item["front_image_path"] = image_file_path
return item
#settings.py
ITEM_PIPELINES = {
# ArticleImagePipeline继承了内置的pipeline:ImagesPipeline
'ArticleSpider.pipelines.ArticleImagePipeline': 1,
}
本文由 mdnice 多平台发布















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









