






Overview
概述
Protocol Buffers are a language-neutral, platform-neutral extensible mechanism for serializing structured data.
协议缓冲区是一种与语言无关、与平台无关的可扩展机制,用于序列化结构化数据。
It’s like JSON, except it’s smaller and faster, and it generates native language bindings. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
它类似于JSON,只是它更小更快,而且它生成本地语言绑定。可以定义一次数据的结构化方式,然后使用特殊生成的源代码,使用各种语言,轻松地将结构化数据写入各种数据流和从各种数据流读取结构化数据。
Protocol buffers are a combination of the definition language (created in .proto files), the code that the proto compiler generates to interface with data, language-specific runtime libraries, and the serialization format for data that is written to a file (or sent across a network connection).
协议缓冲区是定义语言(在.proto文件中创建)、proto编译器生成的与数据接口的代码、特定于语言的运行库以及写入文件(或通过网络连接发送)的数据的序列化格式的组合。
What Problems do Protocol Buffers Solve?
协议缓冲区解决了哪些问题?
Protocol buffers provide a serialization format for packets of typed, structured data that are up to a few megabytes in size. The format is suitable for both ephemeral network traffic and long-term data storage. Protocol buffers can be extended with new information without invalidating existing data or requiring code to be updated.
协议缓冲区为大小高达几兆字节的类型化结构化数据包提供序列化格式。该格式既适用于短暂的网络流量,也适用于长期的数据存储。协议缓冲区可以用新信息进行扩展,而不会使现有数据无效或需要更新代码。
Protocol buffers are the most commonly-used data format at Google. They are used extensively in inter-server communications as well as for archival storage of data on disk. Protocol buffer messages and services are described by engineer-authored .proto files. The following shows an example message:
协议缓冲区是谷歌最常用的数据格式。它们广泛用于服务器间通信以及磁盘上数据的存档存储。协议缓冲区消息和服务由工程师编写的.proto文件描述。下面显示了一个示例消息:
message Person {
optional string name = 1;
optional int32 id = 2;
optional string email = 3;
}
The proto compiler is invoked at build time on .proto files to generate code in various programming languages (covered in Cross-language Compatibility later in this topic) to manipulate the corresponding protocol buffer. Each generated class contains simple accessors for each field and methods to serialize and parse the whole structure to and from raw bytes. The following shows you an example that uses those generated methods:
proto编译器在.proto文件上的构建时被调用,以生成各种编程语言的代码(在本主题后面的跨语言兼容性中介绍),从而操作相应的协议缓冲区。每个生成的类都包含每个字段的简单访问器,以及将整个结构序列化到原始字节和从原始字节解析整个结构的方法。下面显示了一个使用这些生成方法的示例:
Person john = Person.newBuilder()
.setId(1234)
.setName("John Doe")
.setEmail("jdoe@example.com")
.build();
output = new FileOutputStream(args[0]);
john.writeTo(output);
Because protocol buffers are used extensively across all manner of services at Google and data within them may persist for some time, maintaining backwards compatibility is crucial. Protocol buffers allow for the seamless support of changes, including the addition of new fields and the deletion of existing fields, to any protocol buffer without breaking existing services. For more on this topic, see Updating Proto Definitions Without Updating Code, later in this topic.
由于协议缓冲区在谷歌的各种服务中广泛使用,其中的数据可能会持续一段时间,因此保持向后兼容性至关重要。协议缓冲区允许在不中断现有服务的情况下,无缝支持对任何协议缓冲区的更改,包括添加新字段和删除现有字段。有关此主题的更多信息,请参阅本主题后面的更新协议定义而不更新代码。
What are the Benefits of Using Protocol Buffers?
使用协议缓冲区有什么好处?
Protocol buffers are ideal for any situation in which you need to serialize structured, record-like, typed data in a language-neutral, platform-neutral, extensible manner. They are most often used for defining communications protocols (together with gRPC) and for data storage.
协议缓冲区非常适合任何需要以与语言无关、与平台无关、可扩展的方式序列化结构化、类似记录、类型化数据的情况。它们最常用于定义通信协议(与gRPC一起)和数据存储。
Some of the advantages of using protocol buffers include:
使用协议缓冲区的一些优点包括:
- Compact data storage
- 紧凑的数据存储
- Fast parsing
- 快速解析
- Availability in many programming languages
- 可用于多种编程语言
- Optimized functionality through automatically-generated classes
- 通过自动生成的类优化了功能
Cross-language Compatibility
跨语言兼容性
The same messages can be read by code written in any supported programming language. You can have a Java program on one platform capture data from one software system, serialize it based on a .proto definition, and then extract specific values from that serialized data in a separate Python application running on another platform.
用任何支持的编程语言编写的代码都可以读取相同的消息。可以让一个平台上的Java程序从一个软件系统捕获数据,根据.proto定义对其进行序列化,然后在另一个平台运行的单独Python应用程序中从序列化的数据中提取特定值。
The following languages are supported directly in the protocol buffers compiler, protoc:
协议缓冲区编译器protoc直接支持以下语言:
The following languages are supported by Google, but the projects’ source code resides in GitHub repositories. The protoc compiler uses plugins for these languages:
谷歌支持以下语言,但项目的源代码位于GitHub存储库中。协议编译器使用这些语言的插件:
Additional languages are not directly supported by Google, but rather by other GitHub projects. These languages are covered in Third-Party Add-ons for Protocol Buffers.
其他语言不是谷歌直接支持的,而是其他GitHub项目支持的。协议缓冲区的第三方附加组件中涵盖了这些语言。
Cross-project Support
跨项目支持
You can use protocol buffers across projects by defining message types in .proto files that reside outside of a specific project’s code base. If you’re defining message types or enums that you anticipate will be widely used outside of your immediate team, you can put them in their own file with no dependencies.
通过在位于特定项目代码库之外的.proto文件中定义message类型,可以跨项目使用协议缓冲区。如果正在定义message类型或枚举,预计这些类型或枚举将在直属团队之外广泛使用,那么可以将它们放在自己的文件中,而不需要依赖项。
A couple of examples of proto definitions widely-used within Google are timestamp.proto and status.proto.
谷歌中广泛使用的原型定义的几个例子是时间戳原型和状态原型。
Updating Proto Definitions Without Updating Code
在不更新代码的情况下更新协议定义
It’s standard for software products to be backward compatible, but it is less common for them to be forward compatible. As long as you follow some simple practices when updating .proto definitions, old code will read new messages without issues, ignoring any newly added fields. To the old code, fields that were deleted will have their default value, and deleted repeated fields will be empty. For information on what “repeated” fields are, see Protocol Buffers Definition Syntax later in this topic.
软件产品向后兼容是标准的,但向前兼容则不太常见。只要在更新.proto定义时遵循一些简单的做法,旧代码就会毫无问题地读取新消息,忽略任何新添加的字段。对于旧代码,已删除的字段将具有其默认值,并且已删除的重复字段将为空。有关什么是“重复”字段的信息,请参阅本主题后面的协议缓冲区定义语法。
New code will also transparently read old messages. New fields will not be present in old messages; in these cases protocol buffers provide a reasonable default value.
新代码也将透明地读取旧消息。新字段将不会出现在旧消息中;在这些情况下,协议缓冲区提供了合理的默认值。
When are Protocol Buffers not a Good Fit?
什么时候协议缓冲区不适合?
Protocol buffers do not fit all data. In particular:
协议缓冲区不适合所有数据。特别是:
- Protocol buffers tend to assume that entire messages can be loaded into memory at once and are not larger than an object graph. For data that exceeds a few megabytes, consider a different solution; when working with larger data, you may effectively end up with several copies of the data due to serialized copies, which can cause surprising spikes in memory usage.
- 协议缓冲区倾向于假设整个消息可以一次加载到内存中,并且不大于对象图。对于超过几兆字节的数据,请考虑不同的解决方案;当处理较大的数据时,由于序列化的副本,可能会有效地得到多个数据副本,这可能会导致内存使用率的惊人峰值。
- When protocol buffers are serialized, the same data can have many different binary serializations. You cannot compare two messages for equality without fully parsing them.
- 当协议缓冲区被序列化时,相同的数据可以有许多不同的二进制序列化。如果不完全解析两条消息,就无法比较它们是否相等。
- Messages are not compressed. While messages can be zipped or gzipped like any other file, special-purpose compression algorithms like the ones used by JPEG and PNG will produce much smaller files for data of the appropriate type.
- 消息未压缩。虽然消息可以像任何其他文件一样进行压缩或gzip压缩,但JPEG和PNG使用的专用压缩算法将为适当类型的数据生成更小的文件。
- Protocol buffer messages are less than maximally efficient in both size and speed for many scientific and engineering uses that involve large, multi-dimensional arrays of floating point numbers. For these applications, FITS and similar formats have less overhead.
- 对于涉及浮点数的大的多维数组的许多科学和工程用途来说,协议缓冲消息在大小和速度上都不如最大效率。对于这些应用,FITS和类似格式的开销较小。
- Protocol buffers are not well supported in non-object-oriented languages popular in scientific computing, such as Fortran and IDL.
- 在科学计算中流行的非面向对象语言(如Fortran和IDL)中,协议缓冲区没有得到很好的支持。
- Protocol buffer messages don’t inherently self-describe their data, but they have a fully reflective schema that you can use to implement self-description. That is, you cannot fully interpret one without access to its corresponding
.protofile. - 协议缓冲区消息本身并不自我描述其数据,但它们有一个完全反射的模式,可以用来实现自我描述。也就是说,如果不访问相应的.proto文件,就无法完全解释一个。
- Protocol buffers are not a formal standard of any organization. This makes them unsuitable for use in environments with legal or other requirements to build on top of standards.
- 协议缓冲区不是任何组织的正式标准。这使得它们不适合在有法律或其他要求的环境中使用,以建立在标准之上。
Who Uses Protocol Buffers?
谁使用协议缓冲区?
Many projects use protocol buffers, including the following:
许多项目使用协议缓冲区,包括以下内容:
How do Protocol Buffers Work?
协议缓冲区是如何工作的?
The following diagram shows how you use protocol buffers to work with your data.
下图显示了如何使用协议缓冲区处理数据。
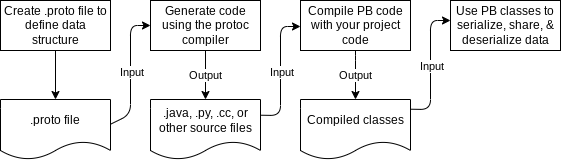
Figure 1. Protocol buffers workflow
图1。协议缓冲区工作流
The code generated by protocol buffers provides utility methods to retrieve data from files and streams, extract individual values from the data, check if data exists, serialize data back to a file or stream, and other useful functions.
协议缓冲区生成的代码提供了从文件和流中检索数据、从数据中提取单个值、检查数据是否存在、将数据序列化回文件或流以及其他有用功能的实用方法。
The following code samples show you an example of this flow in Java. As shown earlier, this is a .proto definition:
下面的代码示例向您展示了Java中此流的一个示例。如前所述,这是一个.proto定义:
message Person {
optional string name = 1;
optional int32 id = 2;
optional string email = 3;
}
Compiling this .proto file creates a Builder class that you can use to create new instances, as in the following Java code:
编译这个.proto文件会创建一个Builder类,可以使用它来创建新的实例,如以下Java代码所示:
Person john = Person.newBuilder()
.setId(1234)
.setName("John Doe")
.setEmail("jdoe@example.com")
.build();
output = new FileOutputStream(args[0]);
john.writeTo(output);
You can then deserialize data using the methods protocol buffers creates in other languages, like C++:
然后,可以使用协议缓冲区在其他语言(如C++)中创建的方法来反序列化数据:
Person john;
fstream input(argv[1], ios::in | ios::binary);
john.ParseFromIstream(&input);
int id = john.id();
std::string name = john.name();
std::string email = john.email();
Protocol Buffers Definition Syntax
协议缓冲区定义语法
When defining .proto files, you can specify that a field is either optional or repeated (proto2 and proto3) or leave it set to the default, implicit presence, in proto3. (The option to set a field to required is absent in proto3 and strongly discouraged in proto2. For more on this, see “Required is Forever” in Specifying Field Rules.)
在定义.proto文件时,可以指定一个字段是optional或repeated(proto2和proto3),或者在proto3中将其设置为默认的隐式存在。(将字段设置为required字段的选项在proto3中不存在,在proto2中强烈不鼓励。有关此方面的详细信息,请参阅指定字段规则中的“Required is Forever”。)
After setting the optionality/repeatability of a field, you specify the data type. Protocol buffers support the usual primitive data types, such as integers, booleans, and floats. For the full list, see Scalar Value Types.
设置字段的可选性/可重复性后,可以指定数据类型。协议缓冲区支持常见的基元数据类型,如整数、布尔值和浮点值。有关完整列表,请参见标量值类型。
A field can also be of:
字段也可以是:
- A
messagetype, so that you can nest parts of the definition, such as for repeating sets of data. message类型,以便可以嵌套定义的部分,例如用于重复数据集。- An
enumtype, so you can specify a set of values to choose from. - 枚举类型,因此可以指定一组可供选择的值。
- A
oneoftype, which you can use when a message has many optional fields and at most one field will be set at the same time. - 类型为的
oneof,当消息具有多个可选字段,并且最多同时设置一个字段时,可以使用该字段。 - A
maptype, to add key-value pairs to your definition. - 映射类型,用于将键值对添加到定义中。
In proto2, messages can allow extensions to define fields outside of the message, itself. For example, the protobuf library’s internal message schema allows extensions for custom, usage-specific options.
在proto2中,消息可以允许扩展定义消息本身之外的字段。例如,protobuf库的内部消息模式允许扩展自定义的、特定于用途的选项。
For more information about the options available, see the language guide for proto2 or proto3.
有关可用选项的更多信息,请参阅proto2或proto3的语言指南。
After setting optionality and field type, you assign a field number. Field numbers cannot be repurposed or reused. If you delete a field, you should reserve its field number to prevent someone from accidentally reusing the number.
设置可选性和字段类型后,将分配一个字段编号。字段号不能重新调整用途或重复使用。如果删除字段,则应保留其字段编号,以防止有人意外重复使用该编号。
Additional Data Type Support
额外的数据类型支持
Protocol buffers support many scalar value types, including integers that use both variable-length encoding and fixed sizes. You can also create your own composite data types by defining messages that are, themselves, data types that you can assign to a field. In addition to the simple and composite value types, several common types are published.
协议缓冲区支持许多标量值类型,包括使用可变长度编码和固定大小的整数。还可以通过定义消息来创建自己的复合数据类型,这些消息本身就是可以分配给字段的数据类型。除了简单值类型和复合值类型外,还发布了几种常见的类型。
Common Types
常见类型
- Duration is a signed, fixed-length span of time, such as 42s.
- 持续时间是一个有符号的、固定长度的时间跨度,例如42秒。
- Timestamp is a point in time independent of any time zone or calendar, such as 2017-01-15T01:30:15.01Z.
- 时间戳是一个独立于任何时区或日历的时间点,例如2017-01-15T01-30:15.01Z。
- Interval is a time interval independent of time zone or calendar, such as 2017-01-15T01:30:15.01Z - 2017-01-16T02:30:15.01Z.
- 间隔是一个独立于时区或日历的时间间隔,例如2017-01-15T001:30:15.01Z-2017-01-16T02:30:15.01Z。
- Date is a whole calendar date, such as 2025-09-19.
- 日期是一个完整的日历日期,例如2025-09-19。
- DayOfWeek is a day of the week, such as Monday.
- DayOfWeek是一周中的一天,例如星期一。
- TimeOfDay is a time of day, such as 10:42:23.
- TimeOfDay是一天中的时间,例如10:42:23。
- LatLng is a latitude/longitude pair, such as 37.386051 latitude and -122.083855 longitude.
- LatLng是一对纬度/经度,例如纬度37.386051和经度-122.083855。
- Money is an amount of money with its currency type, such as 42 USD.
- 货币是一种货币类型的货币,例如42美元。
- PostalAddress is a postal address, such as 1600 Amphitheatre Parkway Mountain View, CA 94043 USA.
- PostalAddress是一个邮政地址,例如1600 Amphitheatre Parkway Mountain View,CA 94043 USA。
- Color is a color in the RGBA color space.
- 颜色是RGBA颜色空间中的一种颜色。
- Month is a month of the year, such as April.
- 月份是一年中的一个月,例如四月。
History
历史
To read about the history of the protocol buffers project, see History of Protocol Buffers.
要了解协议缓冲区项目的历史记录,请参阅协议缓冲区的历史记录。
Protocol Buffers Open Source Philosophy
协议缓冲区开源理念
Protocol buffers were open sourced in 2008 as a way to provide developers outside of Google with the same benefits that we derive from them internally. We support the open source community through regular updates to the language as we make those changes to support our internal requirements. While we accept select pull requests from external developers, we cannot always prioritize feature requests and bug fixes that don’t conform to Google’s specific needs.
协议缓冲区于2008年开源,为谷歌以外的开发人员提供了与我们内部从中获得的好处相同的好处。我们通过定期更新语言来支持开源社区,同时进行这些更改以支持我们的内部需求。虽然我们接受外部开发人员的select pull请求,但我们不能总是优先考虑不符合谷歌特定需求的功能请求和错误修复。
Developer Community
开发者社区
To be alerted to upcoming changes in Protocol Buffers and to connect with protobuf developers and users, join the Google Group.
要了解协议缓冲区即将发生的变化,并与protobuf开发人员和用户联系,请加入谷歌小组。














 939
939











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









