






-
构造验证集
在模型的训练过程中,模型只能利用训练数据来进行训练,模型并不能接触到测试集上的样本。因此模型如果将训练集学的过好,模型就会记住训练样本的细节,导致模型在测试集的泛化效果较差,这种现象称为过拟合(Overfitting)。与过拟合相对应的是欠拟合(Underfitting),即模型在训练集上的拟合效果较差。
随着模型复杂度和模型训练轮数的增加,CNN模型在训练集上的误差会降低,但在测试集上的误会逐渐降低,然后逐渐升高,而我们为了追求的是模型在测试集上的精度越高越好。
导致模型过拟合的情况有很多种原因,其中最为常见的情况是模型复杂度(Model
Complexity )太高,导致模型学习到了训练数据的方方面面,学习到了一些细枝末节的规律。
解决上述问题最好的解决方法:构建一个与测试集尽可能分布一致的样本集(可称为验证集),在训练过程中不断验证模型在验证集上的精度,并以此控制模型的训练。
验证集的划分有如下几种方式:
-
留出法:直接将训练集划分成两部分,新的训练集和验证集。这种划分方式的优点是最为直接简单;缺点是只得到了一份验证集,有可能导致模型在验证集上过拟合。留出法应用场景是数据量比较大的情况。 -
交叉验证法:将训练集划分成K份,将其中的K-1份作为训练集,剩余的1份作为验证集,循环K训练。这种划分方式是所有的训练集都是验证集,最终模型验证精度是K份平均得到。这种方式的优点是验证集精度比较可靠,训练K次可以得到K个有多样性差异的模型;CV验证的缺点是需要训练K次,不适合数据量很大的情况。 -
自助采样法:通过有放回的采样方式得到新的训练集和验证集,每次的训练集和验证集都是有区别的。这种划分方式一般适用于数据量较小的情况。
2.模型训练与验证
构造训练集和验证集,代码如下:
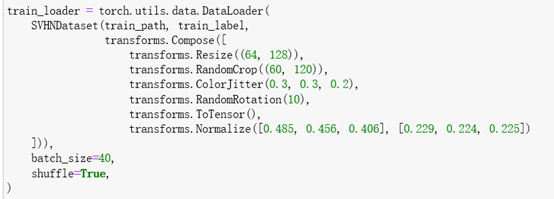
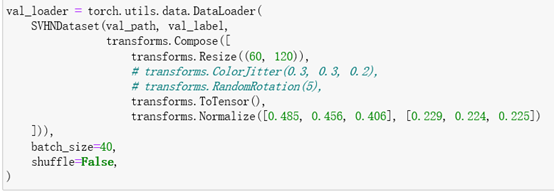
然后开始训练N个epoch,损失函数为交叉熵损失,优化器用Adam,代码如下:
















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









