







28个常用的损失函数介绍以及Python代码实现总结
最近在做多分类的研究,总是遇到这么多损失函数,应该挑选哪一个损失函数呢?这样的问题。于是心血来潮便想着对损失函数进行总结。
以下是一个预览总结:
| 损失函数名称 | 问题类型 |
|---|---|
| L1范数损失 | 回归问题 |
| L2范数损失 | 回归问题 |
| 平滑L1范数损失 | 目标检测 |
| 均方误差损失(MSE Loss) | 评估模型 |
| 均方根误差损失(RMSE) | 评估模型 |
| 平均绝对误差损失(MAE) | 评估模型 |
| 交叉熵损失(CE Loss) | 多分类问题 |
| 二元交叉熵损失(BCE) | 二分类问题 |
| Logits二元交叉熵损失 | 二分类问题 |
| KL散度损失 | 概率分布差异 |
| 边际排序损失 | 排名学习 |
| 合页损失(Hinge Loss) | 分类问题(支持向量机) |
| 合页嵌入损失 | 分类问题 |
| 软边际损失 | 分类问题(逻辑回归) |
| 多标签边际损失 | 多标签分类 |
| 分类交叉熵损失 | 多分类问题(互斥类别) |
| Softmax交叉熵损失 | 多分类问题 |
| 多标签软边际损失 | 多标签分类 |
| 多边际损失 | 多分类问题(多类别支持) |
| 三元组损失 | 特征学习(图像检索、人脸识别等) |
| 余弦嵌入损失 | 特征学习(面部识别、推荐系统等) |
| CTC损失 | 序列建模(语音识别、手写识别等) |
| 负对数似然损失 | 多分类问题(多类别支持) |
| 泊松负对数似然损失 | 计数数据预测(时间序列预测等) |
| 焦点损失(Focal Loss) | 分类问题(目标检测、不平衡数据集) |
| IoU损失 | 目标检测、图像分割 |
| Dice损失 | 图像分割 |
| 生成对抗网络损失(GAN) | 生成对抗网络 |
下面我来详细介绍每一个损失函数
1. L1范数损失 — L1 Loss
L1范数损失,也称为曼哈顿距离损失或绝对值损失。如下:

它衡量的是其实就是真实值和预测值之间的绝对值,再求和。
特点:
- 稀疏性:当使用L1范数作为正则化项时,它可以导致模型参数的稀疏性,即某些参数可能会变为零,这有助于特征选择。
- 对异常值不敏感:与L2范数(欧几里得距离)相比,L1范数对异常值的敏感度较低,因为它只计算差的绝对值,而不是平方。
- 非光滑性:L1范数损失函数在 𝑦𝑖 = y ^ \hat{y} y^𝑖 时不可导,这在优化过程中可能需要特别的处理方法,如使用次梯度。
使用:
import torch
import torch.nn as nn
criterion = nn.L1Loss() # 初始化
l1_loss = criterion(y_pred, y_true) # 计算L1范数损失
L1范数损失常用于回归问题,特别是在模型需要对异常值具有较强鲁棒性或需要稀疏解时。然而,由于其非光滑性,优化过程可能比使用L2范数损失更加复杂。
2. L2范数损失 — L2 Loss
L2损失,也称为欧几里得损失或平方损失,是回归问题中最常用的损失函数之一。
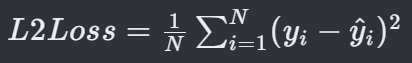
显而易见,它衡量的是预测值与真实值之间差的平方的总和。
特点:
- 敏感性:L2损失对异常值(outliers)非常敏感,因为异常值会导致损失函数的值显著增加。
- 平滑性:L2损失在整个定义域内都是平滑的,这使得它在优化过程中易于使用梯度下降算法。
- 最小二乘法:L2损失是最小二乘法的基础,它试图最小化预测误差的平方和。
使用:
import torch
import torch.nn as nn
criterion = nn.MSELoss() # 初始化
l2_loss = criterion(y_pred, y_true) # 计算L2范数损失
L2损失在许多实际应用中都非常有效,特别是在数据集相对干净,没有太多异常值的情况下,多用于回归问题。然而,当数据集中包含异常值时,可能需要考虑使用对异常值不那么敏感的损失函数,如L1损失、Huber损失等。
3. 平滑L1范数损失 — Smooth L1 Loss
Smooth L1 Loss 是 L1 损失的一种变体,它结合了 L1 损失和 L2 损失的优点,以解决 L1 损失在优化过程中的非光滑性问题。
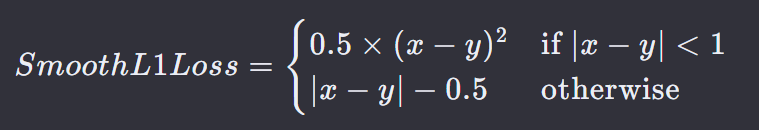
- 在 ∣𝑥 − 𝑦∣ < 1 时,表现为 L2 损失,这使得它在预测值接近真实值时平滑且易于优化。
- 当 ∣𝑥 − 𝑦∣ > 1 时,表现为 L1 损失,这有助于减少对异常值的敏感性,并且能够保持 L1 损失的一些特性,如稀疏性。
特点:
- 平滑性:在 ∣𝑥 − 𝑦∣< 1 的范围内,损失函数是平滑的,这使得梯度下降算法更容易找到最小值。
- 鲁棒性:当 ∣𝑥 − 𝑦∣ > 1 时,损失函数变为 L1 形式,这减少了对异常值的敏感性。
- 易于优化:由于损失函数在整个定义域内都是可导的,这使得它在优化过程中更加稳定。
使用:
import torch
import torch.nn as nn、
criterion = nn.SmoothL1Loss(beta=1.0) #初始化
smooth_l1_loss = criterion(y_pred, y_true) # 计算Smooth L1 Loss
Smooth L1 损失函数通常用于目标检测任务中,特别是在训练 Fast R-CNN 这类模型时。
4. 均方误差损失 — MSE Loss
MSE损失,即均方误差损失(Mean Squared Error Loss)。
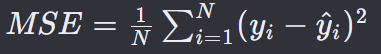
计算所有样本的预测值与真实值之间差的平方的平均值
特点:
- 直观性:MSE损失直观地表示了预测值与真实值之间的平均误差。
- 敏感性:MSE损失对异常值(outliers)非常敏感,因为异常值会导致损失函数的值显著增加。
- 可微性:MSE损失在整个定义域内都是平滑且可微的,这使得它在优化过程中易于使用梯度下降算法。
- 统计特性:MSE损失是预测误差的期望值,因此在统计学中具有很好的特性。
使用:
import torch
import torch.nn as nn
criterion = nn.MSELoss() # 创建一个MSE损失实例
mse_loss = criterion(y_pred, y_true) # 计算MSE Loss
MSE损失通常用于评估模型的预测性能,特别是在需要最小化预测误差的场景中。
由于其对异常值的敏感性,当数据集中存在异常值时,可能需要考虑使用其他损失函数,如MAE损失或Huber损失等,以提高模型的鲁棒性。
5. 均方根误差损失 — RMSE Loss
均方根误差(Root Mean Squared Error,简称RMSE)是一种常用的统计度量,用于评估回归模型的预测精度。
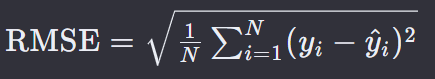
RMSE提供了预测误差的标准度量,它是均方误差(Mean Squared Error,MSE)的平方根。
特点:
- 量纲一致性:RMSE的单位与原始数据的单位相同,这使得它更易于直观理解。
- 敏感性:与MSE一样,RMSE对异常值(outliers)也很敏感。
- 正数:RMSE总是非负的,它可以直观地表示预测误差的大小。
- 可解释性:RMSE提供了预测误差的直观度量,可以很容易地向非专业人士解释。
使用:
import torch
import torch.nn as nn
criterion = nn.MSELoss() # 创建一个均方误差损失实例
mse_loss = criterion(y_pred, y_true) # 计算MSE Loss
rmse_loss = torch.sqrt(mse_loss) # 计算RMSE Loss
RMSE是一种常用的评估指标,特别是在需要量化预测误差的场景中。
由于其对异常值的敏感性,当数据集中存在异常值时,可能需要考虑使用其他评估指标,如平均绝对误差(Mean Absolute Error,MAE)等,以提高模型评估的鲁棒性。
RMSE平方了误差,因此它对较大的误差给予了更大的权重,而MAE直接计算误差的绝对值,对所有误差赋予相同的权重。
6. 平均绝对误差损失 — MAE Loss
MAE(Mean Absolute Error,均方绝对误差)是一种衡量模型预测精度的统计度量。MAE是回归问题中常用的损失函数之一,特别是在需要快速计算和对异常值不太敏感的情况下。
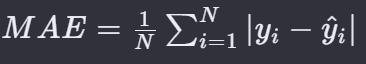
计算了预测值与真实值之间差的绝对值的平均。
特点:
- 直观性:MAE提供了预测误差的简单度量,易于理解和解释。
- 稳健性:与均方误差(MSE)相比,MAE对异常值(outliers)的敏感性较低,因为它不平方误差值。
- 非负性:MAE总是非负的,它直接反映了预测误差的大小。
- 计算简单:MAE的计算不需要进行平方或开方操作,因此在某些情况下计算上更高效。
使用:
import torch
import torch.nn as nn
criterion = nn.L1Loss() # 初始化
loss = criterion(model_predictions, true_values) # 计算损失
MAE常用于评估模型的性能,尤其是在数据集中存在异常值或者我们希望模型对异常值不那么敏感时。
由于MAE没有平方误差,它不会像MSE那样强烈地惩罚较大的误差,这可能会影响模型在最小化较大误差方面的性能。
7. 交叉熵损失 — CE Loss
交叉熵损失(Cross-Entropy Loss),也称为对数损失(Logarithmic Loss),是分类问题中常用的损失函数,特别是在多分类问题中。
它衡量的是模型输出的概率分布与真实标签的概率分布之间的差异。
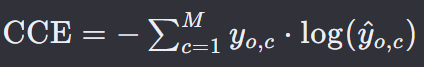
M 是类别的总数。
yo,c 是一个二进制指示器(one-hot),正确为1,错误为0。
y ^ \hat{y} y^o,c 是模型预测样本 o 属于类别 c 的概率。
特点:
- 概率度量:交叉熵损失基于概率,因此它适用于输出概率的模型。
- 敏感性:它对预测概率的准确性非常敏感,特别是对于正确类别的预测。
- 非负性:理论上,交叉熵损失是非负的,并且当模型的预测与真实标签完全一致时,损失为0。
- 可微性:交叉熵损失在整个定义域内都是可微的,这使得它在优化过程中可以使用梯度下降算法。
使用:
import torch
import torch.nn as nn
import torch.nn.functional as F
log_probabilities = F.log_softmax(model_logits, dim=1) # 转化模型输出值
criterion = nn.CrossEntropyLoss() # 初始化
loss = criterion(model_logits, true_labels) # 计算损失
交叉熵损失在深度学习中非常流行,特别是在使用Softmax函数进行多分类的神经网络中。
当处理概率接近 0 或 1 时,交叉熵损失可能会导致数值稳定性问题,因为对数函数在0处是未定义的。在实际应用中,可以通过使用数值稳定的实现来避免这些问题。
8. 二元交叉熵损失 — BCE Loss
二元交叉熵损失(Binary Cross-Entropy Loss)是用于二分类问题中的损失函数,它衡量了模型预测的概率分布与真实标签的概率分布之间的差异。这种损失函数特别适用于当输出层只有一个神经元,并且使用 Sigmoid 激活函数时的情况。
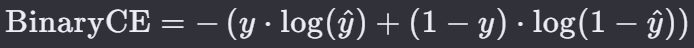
y 是真实标签,通常取值为0或1。
y ^ \hat{y} y^ 是模型预测样本为类别 1(正类)的概率,即 y ^ \hat{y} y^ = σ(z),其中 σ 是 Sigmoid 函数,z 是模型的原始输出(即未经激活函数处理的输出)。
特点:
- 概率解释:损失函数基于概率,可以解释为模型预测正确类别的概率的对数损失。
- 敏感性:对于正确类别的预测,损失函数非常敏感,鼓励模型输出接近 0 或 1 的概率。
- 数值稳定性:当 y ^ \hat{y} y^ 接近 0 或 1 时,对数函数可能导致数值问题。在实践中,通常会对预测值进行小的调整以避免对数为负无穷的情况。
- 可微性:损失函数在整个定义域内都是可微的,这使得它适用于使用梯度下降的优化算法。
使用:
import torch
import torch.nn as nn
import torch.nn.functional as F
predicted_probs = torch.sigmoid(model_logits) # 先转换概率值
criterion = nn.BCELoss() # 初始化
loss = criterion(predicted_probs, true_labels) # 计算损失
在实际应用中,二元交叉熵损失通常与Sigmoid激活函数结合使用,以确保模型输出的概率在0到1之间。这种组合在逻辑回归和二分类神经网络中非常常见。
二元交叉熵损失也是多分类问题中使用的更一般形式的交叉熵损失的基础。
9. logits二元交叉熵损失 — BCE With Logits Loss
BCEWithLogitsLoss 是 PyTorch 中的一个损失函数,它结合了 Sigmoid 激活函数和二元交叉熵损失(Binary Cross-Entropy Loss)。

y 是真实标签,取值为 0 或 1。
z 是模型的原始输出(logits)。
σ(z) 是 Sigmoid 函数,将 logits 转换为概率
特点:
它在数值上更稳定,特别是在处理概率接近 0 或 1 的情况时。这是因为 Sigmoid 函数的导数在输入值非常大或非常小的时候会变得非常小,这可能导致在反向传播过程中的梯度消失问题。通过在损失函数内部应用 Sigmoid,BCEWithLogitsLoss 可以减少这种数值不稳定性。
使用:
import torch.nn as nn
loss_function = nn.BCEWithLogitsLoss() # 定义
loss = loss_function(predictions, targets) #(模型的原始输出,真实的二进制标签)
loss.backward() # 反向传播
这种损失函数特别适用于处理二分类问题,因为它在内部将模型的原始输出(即未经激活函数处理的输出,称为 logits)通过 Sigmoid 函数转换为概率,然后计算与真实标签之间的二元交叉熵损失。
10. KL散度损失 — KL Divergence Loss
KL散度(Kullback-Leibler Divergence),也称为相对熵,是衡量两个概率分布 P 和 Q 差异的一种度量方式。在机器学习中,KL 散度常用于衡量模型预测的概率分布与真实分布之间的差异。
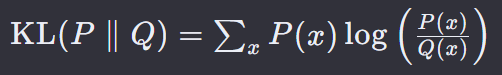
P(x) 是真实的概率分布。
Q(x) 是模型预测或近似的概率分布。
x 是概率分布中的事件或类别。
特点:
- 非对称性:KL散度从 P 到 Q 的度量与从 Q 到 P 的度量不同,即 KL(P∥Q) ≠ KL(Q∥P)。
- 非负性:KL 散度总是非负的,当且仅当 P 和 Q 完全相同时,它为 0。
- 度量差异:KL 散度提供了一种度量两个概率分布差异的方法,差异越大,KL 散度的值越大。
- 信息量度:KL 散度可以被看作是将分布 Q 转换为分布 P 所需的信息量,或者说是 Q 对 P 的信息损失。
使用:
import torch
import torch.nn as nn
criterion = nn.KLDivLoss(reduction='batchmean') # 初始化
loss = criterion(torch.log(predicted_distribution), true_distribution)
在机器学习中,KL散度常用于:最大化似然估计、正则化和模型选择。
KL散度在机器学习中的应用非常广泛,但由于其非对称性,说是一种距离度量,实际上是一种方向性的度量。
11. 边际排序损失 — Margin Ranking Loss
MarginRankingLoss 是一个在机器学习中用于学习对两个输入进行排名的损失函数。
MarginRankingLoss 的目标是使得具有较高目标值的输入实例的预测值比具有较低目标值的实例的预测值至少高出一个预定的边界(margin)。
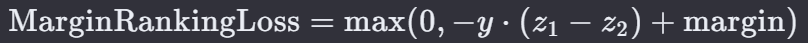
z1 和 z2 是模型对两个输入实例的预测值(logits)。
y 是一个指示变量,如果 z1 应该排在 z2 前面,则 y*=1;如果 z2 应该排在 z1 前面,则 y*=−1。
margin 是一个非负实数,表示排名正确时需要超过的最小差距。
特点:
- 排名学习:该损失函数专门用于排名学习任务,鼓励模型根据真实标签的相对顺序来调整预测值。
- 边界(Margin):通过设置 margin 参数,可以控制预测值之间需要保持的最小差距,这有助于提高模型对排名的敏感度。
- 非对称性:损失函数对 y =1 和 y = −1 的处理是不同的,这反映了不同排名情况下的不同重要性。
使用:
import torch
import torch.nn as nn
criterion = nn.MarginRankingLoss(margin=margin) # 初始化
loss = criterion(scores, labels) # 计算损失
它通常用于那些需要模型能够对两个实例进行比较并输出相对顺序的任务,例如在推荐系统中对商品进行排序,或者在计算机视觉中对图像进行相似性排序。很多需要精细排序的任务中是非常有用的。
12. 合页损失 — Hinge Loss
Hinge Loss 是一种在机器学习中常用的损失函数,特别是在支持向量机(SVM)和最大间隔分类器中。Hinge Loss 旨在通过最大化不同类别之间的间隔来提高模型的泛化能力。
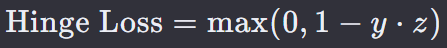
y 是真实标签,通常取值为 +1 或 -1,表示正类或负类。
z 是模型对样本的预测值(也称为 logits),即模型预测样本属于正类的程度。
y ⋅ z 表示预测值和真实标签的乘积,如果预测值与真实标签一致,则乘积为正。
特点:
- 最大间隔:Hinge Loss 鼓励模型预测值与真实标签的乘积尽可能大,从而最大化正负样本之间的间隔。
- 非负损失:只有当 y ⋅ z 小于 1 时,Hinge Loss 才会产生损失,即当模型预测的间隔小于1时。
- 非线性:虽然 Hinge Loss 本身是线性的,但它通常与非线性激活函数结合使用,以学习复杂的非线性决策边界。
它不直接提供概率输出,只关注间隔,而 Sigmoid 和 Softmax 还考虑了概率的输出。Hinge Loss 通常用于二分类问题,而 Sigmoid 或 Softmax 激活函数通常用于二元或多分类问题。
13. 合页嵌入损失 — Hinge Embedding Loss
HingeEmbeddingLoss 和 HingeLoss 在概念上是相似的,因为它们都来源于同一个基本思想:通过最大化不同类别之间的间隔来提高模型的分类性能。然而,它们在实现和应用上有一些细微的差别。
它用于学习一个可以区分两个类别的线性边界或超平面。通常用于训练支持向量机(SVM)或深度学习模型中的某些层,以确保模型能够区分不同类别的样本。
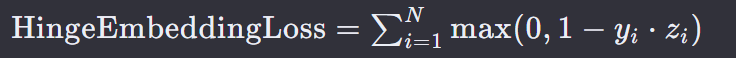
N 是样本的总数。
yi 是第 i 个样本的真实标签,通常取值为 +1 或 -1。
zi是模型对第 i* 个样本的预测值(也称为 logits),它表示样本属于类别 +1 的预测强度。
特点:
- 最大边界:该损失函数鼓励模型学习一个最大化边界的决策边界,使得不同类别之间的间隔尽可能大。
- 非负损失:损失函数只对那些**预测错误的样本或边界内样本计算损失**,即当 𝑦𝑖 ⋅ 𝑧𝑖 ≤ 1 时。
- 非线性:虽然 HingeEmbeddingLoss 本身是线性的,但它经常与非线性激活函数结合使用,以学习非线性决策边界。
使用:
import torch.nn as nn
loss_function = nn.HingeEmbeddingLoss() # 定义
loss = loss_function(predictions, targets) #(模型的原始输出,真实的二进制标签)
loss.backward() # 反向传播
HingeEmbeddingLoss 可以帮助模型学习区分不同类别的样本,特别是在需要最大化边界宽度的场景中。
14. 软边际损失 — Soft Margin Loss
它适用于那些模型输出连续值(如:Sigmoid 转换后的值),并且这些值可以被解释为概率的情况。
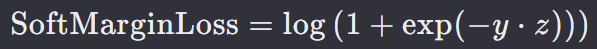
y 是真实标签,通常取值为 +1 或 -1。
z 是模型对样本的预测值(logits)。
特点:
- 连续概率输出:与 HingeLoss 不同,SoftMarginLoss 适用于那些模型输出连续概率值的情况。
- 对数损失:损失函数使用对数来计算损失,这有助于平衡正负样本的惩罚。
- 非线性:损失函数是非线性的,它通过指数函数来调整损失值。
- 可微性:损失函数在整个定义域内都是可微的,这使得它适用于使用梯度下降的优化算法。
SoftMarginLoss 常用于逻辑回归模型。
使用:
import torch.nn as nn
loss_function = nn.SoftMarginLoss() # 定义
loss = loss_function(predictions, targets) #(模型的原始输出,真实的二进制标签)
loss.backward() # 反向传播
使用 SoftMarginLoss 可以帮助模型学习区分不同类别的样本,同时输出概率预测。
15. 多标签边际损失 — Multi Label Margin Loss
MultiLabelMarginLoss 是一种在深度学习中用于多标签分类问题的损失函数。与标准的分类损失函数不同,多标签分类问题中一个样本可以同时属于多个类别。
MultiLabelMarginLoss 旨在为每个标签类别学习一个单独的决策边界,并通过最大化正确类别和错误类别之间的间隔来提高分类的准确性。
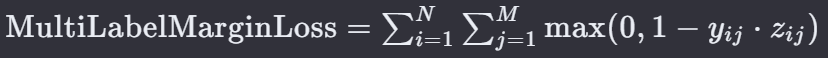
N 是样本的总数。M 是类别的总数。
yij 是第 i 个样本在第 j 个类别上的真实标签,如果样本属于该类别,则为 +1;否则为 -1。
zij 是模型对第 i 个样本在第 j 个类别上的预测值(logits)。
特点:
- 多标签分类:适用于每个样本可以同时属于多个类别的分类问题。
- 间隔最大化:通过最大化正确类别和错误类别之间的间隔,提高分类的鲁棒性。
- 非对称性:损失函数对正确类别和错误类别的惩罚是不对称的,更关注于正确类别的预测准确性。
- 可微性:损失函数在整个定义域内都是可微的,适用于使用梯度下降的优化算法。
使用:
import torch
import torch.nn as nn
criterion = nn.MultiLabelMarginLoss() # 初始化
loss = criterion(model_logits, true_labels) # 计算损失
MultiLabelMarginLoss 可以用于各种多标签分类任务,通常与 Sigmoid 激活函数结合使用,因为 MultiLabelMarginLoss 需要模型输出每个类别的未归一化预测值(logits)。
16. 分类交叉熵损失 — Categorical Cross-Entropy Loss
是一种在多分类问题中常用的损失函数。这种损失函数适用于目标类别是互斥的情况,即每个样本只属于一个类别。
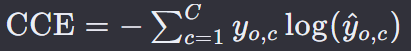
C 是类别的总数。
𝑦o,c 是一个二进制指示器(0或1),如果类别 c 是样本 o 的正确分类,则为1,否则为0。
y ^ \hat{y} y^o,c 是模型预测样本 o 属于类别 c 的概率。
特点:
- 概率度量:损失函数基于概率,适用于输出概率的模型,模型输出经过激活后才能用。
- 互斥性:每个样本只属于一个类别,损失函数对每个样本只计算一个类别的损失。
- 非负性:理论上,交叉熵损失是非负的,当模型的预测与真实标签完全一致时,损失为0。
- 可微性:损失函数在整个定义域内都是可微的,适用于使用梯度下降的优化算法。
使用:
import torch.nn as nn
import torch.nn.functional as F
log_probabilities = F.log_softmax(model_logits, dim=1) # 模型输出转换为概率
criterion = nn.CrossEntropyLoss() # 初始化
loss = criterion(model_logits, true_labels) # 计算损失
分类交叉熵损失通常与 Softmax 激活函数结合使用。用于多分类任务。
17. Softmax 交叉熵损失 — Softmax Cross-Entropy Loss
Softmax Cross-Entropy Loss 是一种在多分类问题中常用的损失函数,特别是在神经网络的输出层。
与 Categorical Cross-Entropy Loss 类似,Softmax 交叉熵损失也用于衡量模型预测的概率分布与真实标签的概率分布之间的差异。
包括两部分:Softmax 函数 和 交叉熵损失函数
首先,Softmax 函数将模型的原始输出(logits)转换为概率分布:
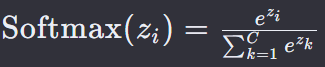
再计算交叉熵损失:
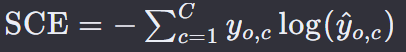
𝑦o,c 是一个二进制指示器(0或1),如果类别 c 是样本 o 的正确分类,则为1,否则为0。
y ^ \hat{y} y^o,c 是 Softmax 函数输出的样本 o 属于类别 c 的概率。
特点:
- 概率解释:损失函数基于概率,可以解释为模型预测正确类别的概率的对数损失。
- 多类别:适用于样本可以属于多个互斥类别中的任意一个的场景。
- 数值稳定性:Softmax 函数在计算过程中可能会导致数值稳定性问题,特别是在 zi 值非常大或非常小的情况下。通常需要采取措施来避免数值溢出或下溢。
- 可微性:损失函数在整个定义域内都是可微的,适用于使用梯度下降的优化算法。
使用:
import torch.nn as nn
import torch.nn.functional as F
probabilities = F.softmax(model_logits, dim=1) # 原始输出转换为概率
criterion = nn.CrossEntropyLoss() # 初始化
loss = criterion(model_logits, true_labels) # 计算损失
通常用于输出层,进行多分类任务时使用。
18. 多标签软边际损失 — Multi Label Soft Margin Loss
多标签软边际损失(Multi Label Soft Margin Loss)是一种用于多标签分类问题的损失函数,它允许每个样本同时属于多个类别。
每个类别的标签是二元的(0 或 1),表示样本是否属于该类别。多标签软边际损失通过对所有类别的损失求和来计算总损失。
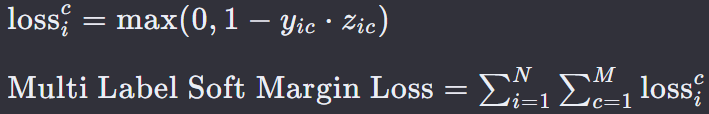
N 是样本的总数。
M 是类别的总数。
𝑦𝑖𝑐 是第 i 个样本在第 c 个类别上的真实标签,取值为 0 或 1。
𝑧𝑖𝑐 是模型对第 i 个样本属于第 c 个类别的预测值(logits)。
特点:
- 多标签兼容性:适用于每个样本可以同时属于多个非互斥类别的情况。
- 软间隔:允许模型输出一个连续的值来表示样本属于每个类别的程度,而不是硬性的分类。
- 可微性:损失函数是可微的,适用于梯度下降和其他基于梯度的优化算法。
这种损失函数在实现时通常需要对每个类别的预测值 𝑧𝑖𝑐 应用 Sigmoid 函数,以确保预测值在 0 到 1 之间,表示概率。它内部结合了 Sigmoid 激活和二元交叉熵损失。
使用:
nn.MultiLabelSoftMarginLoss(weight=None, reduction='mean')
适用于多标签分类。
19. 多边际损失 — Multi Margin Loss
MultiMarginLoss 是 PyTorch 中的一种损失函数,用于多分类问题,特别是当类别数非常多时。这种损失函数可以看作是 Hinge Loss 的扩展,它为每个类别学习一个单独的决策边界,并且通过最大化正确类别和最近的错误类别之间的间隔来提高分类的准确性。
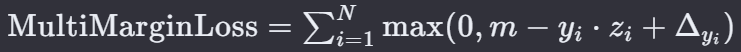
N 是样本的总数。
m 是正则化参数,控制间隔的宽度。
yi 是第 i 个样本的真实标签,通常是独热编码的,只有一个类别为 1,其余为 0。
zi 是模型对第 i 个样本的预测值(logits)。
Δyi 是一个修正项,确保对于非正确类别的 j,有 Δ𝑦𝑖 ≥ max( 0, 𝑧𝑗 − 𝑧𝑖 + 𝑚 )。
特点:
- 多类别支持:适用于类别数非常多的多分类问题。
- 最大间隔:通过最大化正确类别和错误类别之间的间隔来提高分类的鲁棒性。
- 非对称性:损失函数对正确类别和错误类别的惩罚是不对称的,更关注于正确类别的预测准确性。
- 可微性:损失函数在整个定义域内都是可微的,适用于使用梯度下降的优化算法。
使用:
import torch.nn as nn
criterion = nn.MultiMarginLoss(p=1, margin=1.0) # p 是每个类别的输出维度 # margin 是正则化参数
MultiMarginLoss 可以用于各种多分类任务.这种损失函数鼓励模型为每个类别学习一个清晰的边界,从而提高多分类任务的性能。
20. 三元组损失 — Triplet Loss
Triplet Loss(三元组损失)是一种在深度学习中用于学习特征表示的损失函数,特别是在训练深度度量学习模型时。
这种损失函数基于成对的距离比较,但它考虑了三个样本:一个锚点样本、一个正样本和一个负样本。三元组损失的目标是使得锚点样本与正样本之间的距离尽可能小,同时与负样本之间的距离尽可能大。这样,模型学习的特征表示能够反映出样本之间的相对关系。
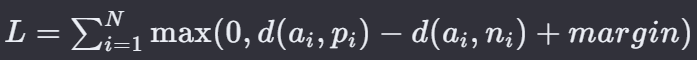
N 是三元组的总数。
ai 是第 i 个三元组的锚点样本的特征表示。
pi 是第 i 个三元组的正样本的特征表示,通常与锚点样本属于同一类别。
ni 是第 i 个三元组的负样本的特征表示,与锚点样本属于不同类别。
𝑑(⋅,⋅) 是样本对之间的距离度量,通常是欧几里得距离。
𝑚𝑎𝑟𝑔𝑖𝑛 是正负样本对之间需要保持的最小距离。
特点:
- 相对距离:三元组损失关注样本之间的相对距离,而不是绝对距离。
- 间隔:通过引入间隔(margin),三元组损失鼓励模型学习区分不同类别的特征表示。
- 鲁棒性:三元组损失可以帮助模型学习更加鲁棒的特征表示,减少噪声和异常值的影响。
- 可微性:损失函数是可微的,适用于使用梯度下降的优化算法。
使用:
import torch.nn as nn
loss = torch.clamp(distance_positive - distance_negative + 1.0, min=0.0).mean() # (样本对的欧氏距离,margin 设置为 1.0)
Triplet Loss 常用于图像检索、人脸识别、签名验证等任务
21. 余弦嵌入损失 — Cosine Embedding Loss
CosineEmbeddingLoss 是一种在深度学习中用于学习特征表示的损失函数,特别是在需要模型学习到的向量能够通过余弦相似度度量其相似性的场景中。这种损失函数鼓励模型使得相似的样本在特征空间中具有更接近的余弦角,而不相似的样本则有更大的余弦角。
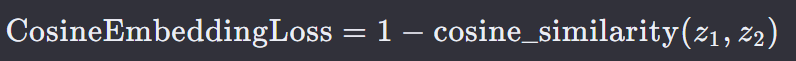
如果 y 为 1(表示正样本,即相似样本),损失函数变为:

如果 y 为 -1(表示负样本,即不相似样本),损失函数变为:
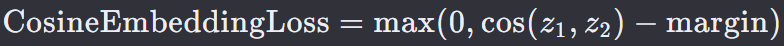
z1 和 z2 是模型输出的两个样本的特征向量。
cos(𝑧1 , 𝑧2) 是 z1 和 z2 之间的余弦相似度。
margin 是一个超参数,用于控制正负样本对之间最小余弦相似度的边界。
特点:
- 余弦相似度:损失函数基于余弦相似度,适用于度量样本间的相似性。
- 间隔边界:通过引入间隔(margin),损失函数鼓励模型学习区分不同类别的特征表示。
- 非负损失:损失函数通常只对负样本对计算损失,且损失值非负。
- 可微性:损失函数是可微的,适用于使用梯度下降的优化算法。
使用:
import torch.nn as nn
criterion = nn.CosineEmbeddingLoss(margin=0.5) # margin 是余弦相似度的边界
loss = criterion(feature_vector1, feature_vector2, label) # 计算损失
CosineEmbeddingLoss 可以用于诸如面部识别、相似性度量、推荐系统等,其中需要模型学习到的特征向量能够反映出样本之间的相似度。
22. 连接时序分类损失 — CTC Loss
CTCLoss(Connectionist Temporal Classification Loss)是一种在序列建模任务中常用的损失函数。允许模型的输出与真实标签之间的序列长度不同,并且可以处理标签错位的情况。
核心思想是引入一个特殊的符号(如空白符号),用于区分不同的时间段。
它的计算涉及到动态规划算法,通过比较模型输出的概率序列和真实标签序列,找到最佳的对齐方式,从而计算损失。损失函数鼓励模型学习到能够正确预测序列中每个元素(包括空白符号)的概率。
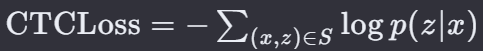
S 是训练样本集合,它是总体分布的一个子集。
(𝑥,𝑧)∈𝑆,x 是输入数据经过模型后的输出,z 是与 x 相对应的目标序列。
𝑝(𝑧∣𝑥) 表示给定输入 x,输出序列 z 的概率。
特点:
- 序列对齐:CTCLoss 能够自动对齐模型输出和真实标签,即使它们的长度不同。
- 空白符号:使用空白符号来处理序列中的不同时间段,允许模型输出在时间上错位的预测。
- 可微性:损失函数是可微的,适用于使用梯度下降的优化算法。
使用:
import torch.nn as nn
criterion = nn.CTCLoss() # 初始化 CTCLoss
loss = criterion(log_probs.transpose(0, 1), targets, input_lengths, target_lengths) # (模型输出的概率矩阵,目标标签序列,输入序列的长度,目标序列的长度)
CTCLoss 通过比较模型输出的概率矩阵和目标标签序列,使用动态规划算法找到最佳对齐方式,并计算损失。多处理序列预测问题。
23. 负对数似然损失 — NLL Loss
负对数似然损失(Negative Log Likelihood Loss),是一种在分类问题中常用的损失函数,特别是在目标类别是互斥的情况下,如多类分类问题。
NLL Loss 衡量的是模型输出的概率分布与真实标签的一致性。
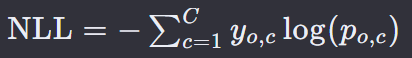
C 是类别的总数。
𝑦𝑜,𝑐 是一个二进制指示器(0或1),如果类别 c 是样本 o 的正确分类,则为1,否则为0。
𝑝𝑜,𝑐 是模型预测样本 o 属于类别 c 的概率。
特点:
- 概率度量:损失函数基于概率,适用于输出概率的模型。
- 互斥性:每个样本只属于一个类别,损失函数对每个样本只计算一个类别的损失。
- 非负性:理论上,NLL Loss 是非负的,当模型的预测与真实标签完全一致时,损失为0。
- 可微性:损失函数在整个定义域内都是可微的,适用于使用梯度下降的优化算法。
使用:
import torch.nn as nn
criterion = nn.NLLLoss() # 初始化
loss = criterion(log_probs, targets) # (输出的概率,目标标签)
NLL Loss 通常与 Softmax 激活函数结合使用,特别是在神经网络的输出层。使用之前要将模型输出值使用激活函数转换为概率。从而提高分类任务的性能。
24. 泊松负对数似然损失 — Poisson NLL Loss
PoissonNLLLoss(泊松负对数似然损失)是一种在统计学和机器学习中使用的损失函数,特别适用于那些预测结果为计数数据的情况。
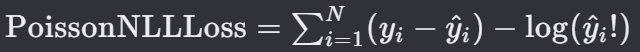
N 是样本的总数。
𝑦𝑖 是第 i 个样本的真实观测值(计数数据)。
y ^ \hat{y} y^ i 是模型预测的 i 个样本的期望值(通常由泊松分布的参数 λ 给出)。
特点:
- 计数数据:适用于预测结果为非负整数的计数数据。
- 概率分布:基于泊松分布,该分布通常用于描述在固定时间或空间内发生的事件数量。
- 非负性:损失函数是针对非负整数的观测值设计的。
- 可微性:损失函数是可微的,适用于使用梯度下降的优化算法。
使用:
import torch.nn as nn
criterion = nn.PoissonNLLLoss()
loss = criterion(log_lambda_pred, y_true) # (模型输出转换为log的值,真实值)
25. 焦点损失 — Focal Loss
Focal Loss 是一种在深度学习中用于分类问题,特别是目标检测和不平衡数据集问题的损失函数。Focal Loss 的目的是解决类别不平衡问题,同时减少对易分类样本的关注,增加模型对困难样本的关注。
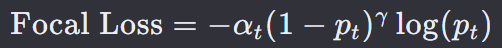
𝑝𝑡 是模型对于实际类别的预测概率。
𝛼𝑡 是一个调节因子,用于平衡类别不平衡,通常对于类别 t 来说是一个常数或者根据类别的频率进行调整。
𝛾 是一个调节指数,用于减少对易分类样本的关注,通常设置为一个大于 0 的值,如 2 或 5。
特点:
- 减少对易分类样本的关注:通过引入调节指数 γ,Focal Loss 减少了对那些模型已经预测得很准确的样本的关注。
- 平衡类别不平衡:通过 𝛼𝑡,Focal Loss 可以为不同类别的样本分配不同的权重,以减轻类别不平衡的影响。
- 改善模型性能:在目标检测和其他分类任务中,Focal Loss 可以帮助模型更快地收敛,并且提高对小对象和困难样本的检测性能。
使用:
import torch.nn as nn
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, reduction='mean'):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.reduction = reduction
def forward(self, inputs, targets):
bce_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction='none')
pt = torch.exp(-bce_loss) # 预测正确的概率
focal_loss = self.alpha * (1 - pt) ** self.gamma * bce_loss
if self.reduction == 'mean':
return torch.mean(focal_loss)
elif self.reduction == 'sum':
return torch.sum(focal_loss)
else:
return focal_loss
Focal Loss并没有作为torch.nn模块的一部分直接提供,以上是一种自定义编写。
多用于分类问题,特别是目标检测和不平衡数据集问题的损失函数。
26. 交并比损失 — IoU Loss
IoU(Intersection over Union)损失,是一种在计算机视觉任务中常用的损失函数,特别是在目标检测和图像分割领域。
它衡量的是预测的区域与真实标注区域之间的重叠程度。
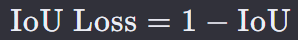
其中 IoU 计算公式为:

Area of Overlap 是预测区域与真实区域相交部分的面积。
Area of Union 是预测区域与真实区域并集的面积。
特点:
- 直观性:IoU 损失直观地衡量了预测区域与真实区域的重叠程度。
- 非负性:IoU 损失值始终在 0 到 1 之间,0 表示没有重叠,1 表示完全重叠。
- 对称性:IoU 损失是对称的,即预测和真实区域可以互换而不影响损失值。
- 不同尺度的敏感性:IoU 损失对预测区域的大小和位置都敏感。
IoU 损失通常与其他损失函数结合使用,以提高模型的性能。它不是处处可微的,特别是在预测区域和真实区域没有重叠时。
使用:
import torch
def iou_loss(predicted_boxes, true_boxes):
intersection = torch.max(predicted_boxes[:, None, :, :], true_boxes[:, :, None, :]).prod(dim=-1) # 计算交集的面积
union = predicted_boxes.prod(dim=-1) + true_boxes.prod(dim=-1) - intersection # 计算并集的面积
iou = intersection / union # 计算 IoU
loss = 1 - iou # 计算 IoU 损失
return loss.mean() # 返回损失的平均值
以上是简单案例。适用于目标检测和图像分割领域。
27. Dice损失 — Dice Loss
Dice Loss(也称为 Sørensen-Dice Loss 或 F1-Score Loss)是一种在机器学习中,特别是在处理图像分割任务时常用的损失函数。它基于 Dice 系数(Sørensen-Dice 系数),该系数衡量了两个样本集合的相似度。
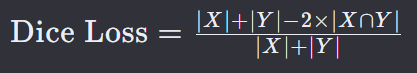
X 是预测的样本集合。
Y 是真实的样本集合。
∣𝑋∩𝑌∣ 是集合 X 和 Y 的交集的大小。
∣𝑋∣ 和 ∣𝑌∣ 分别是集合 X 和 Y 的大小。
特点:
- 对不平衡数据敏感:Dice Loss 对于预测集合和真实集合的大小不平衡较为敏感。
- 对重叠敏感:Dice Loss 高度依赖于预测集合和真实集合的重叠程度。
- 非负性:Dice Loss 是非负的,并且当预测集合和真实集合完全相同时,损失为0。
- 可微性:Dice Loss 是可微的,适用于使用梯度下降的优化算法。
使用:
import torch
def dice_loss(input_tensor, target_tensor):
input_tensor = input_tensor.float()
target_tensor = target_tensor.float() # 确保预测和目标是浮点数
intersection = (input_tensor * target_tensor).sum()
sum_ = (input_tensor + target_tensor).sum() # 计算Dice系数的分子和分母
dice_score = (2. * intersection) / sum_ # 计算Dice系数
loss = 1 - dice_score # 计算Dice Loss
return loss
多用于处理图像分割任务。
28. 生成对抗网络损失 — GAN Loss
生成对抗网络(GAN)中的损失函数是训练过程中的核心部分,它定义了生成器(Generator)和判别器(Discriminator)之间的对抗性竞争。
1.判别器损失(Discriminator Loss): 判别器的目标是正确区分真实数据和生成器生成的假数据。判别器损失由两部分组成:对真实数据的损失和对假数据的损失。
真实数据损失:

假数据损失:

总的判别器损失是这两部分的和:
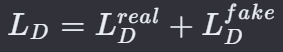
2.生成器损失(Generator Loss): 生成器的目标是生成尽可能让判别器判断为真实的数据。生成器损失基于判别器对生成数据的判断。相当于欺骗判别器的能力。

使用真实数据和生成的假数据更新判别器,目的是最小化判别器损失 𝐿𝐷。
使用生成器生成的假数据更新生成器,目的是最小化生成器损失 𝐿𝐺。


















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











