






在最近的学习中,接触到了语义分割网络FCN,在阅读论文和相关博客后,将自己的所得和代码实现记录在此。也请阅读到此篇微博的读者不吝赐教,批评指正。
本文借鉴了http://www.bubuko.com/infodetail-1895847.html的英文翻译来与自己的理解相互印证。
同时也阅读了http://blog.csdn.net/meanme/article/details/50858240来解决自己对论文中的相关要点的疑惑。
FCN网络是一种端到端,像素到像素的全卷积网络。将任意尺寸的图像输入在经过有效推理和学习之后会产生相应尺寸的输出。
在这个工作之前,也有很多工作将卷积网络运用于dense prediction。比如Ning团队,Farabet团队以及Pinheiro和Collobert提出的语义分割;Ciresan团队提出的电子显微镜中的边界预测,Gainin和Lempitsky提出的通过混合神经网络或最近邻处理自然场景图像;Eigen团队提出的图像修复和深度估计。这些工作的常见要素包含如下
- 限制了容量和感受域的小模型
- Patchwise训练(预测指定像素时,只将此像素和其周围像素作为输入送入模型里训练,即每一个像素都会作为中心像素被训练来预测这个像素所属的分类)
- 超像素投射的预处理,随机场正则化,滤波或局部分类
- 由OverFeat引入的密度输出的输入移位和输出交错
- 多尺度金字塔处理
- 饱和双曲线正切非线性
- 集成
作者虽然没有采用这些机制,但是却研究了patchwise training和FCNs的角度出发的”shift-and-stitch”密度输出。
Shift-and-stitch是稀疏滤波
设输出图与原图之间的降采样因子为f,将输入图像往右平移x像素,向下平移y个像素,对于每个x,y都满足(x,y)∈{0,…,f-1}×{0,…,f-1}。这些f^2个输入通过卷积网络,并使输出交错以使得预测点与他们的接受域的中心像素点一致。
考虑一个输入步长为s的层(卷积层或池化层)以及其后的滤波权重为f_ij(省略特征维度,在这里无关紧要)的卷积层。设置更低一层的输入步长为1以s为因子对输出进行上采样。然而原始filter和输出的上采样进行卷积使用shift-and-stitch并不能产生同样的结果,因为原始的filter只能看到它的(已上采样的)输入减少后的部分。为了重新使用这一技巧,通过放大filter来稀疏filter,如下:
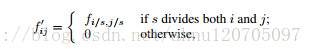
使用该技巧重新生成全网输出需要在每一层重复filter扩大直到所有上采样被消除。
在网络中简单的减少二次采样是一种折中的方法:filter包含更佳的信息,但是却有更小的感受域而且需要更多的时间来计算。我们所见的shift-and-stitck是另一种折中方法:不需要减少filter的感受域尺寸就可以使输出更加密集,但是这种处理后的filter相比于原始的设计无法感受更佳的信息。
作者虽然使用shift-and-stitch做了一些试验,但是在模型中并没有使用这一技巧。而是通过更有效和高效的上采样的学习来处理。
Patchwise训练是一种损失采样
在随机优化中,梯度计算由训练分布驱动的。尽管patchwise训练和全卷积网络训练的相对的计算效率依赖于重叠和minibatch的尺寸,他们却都能够用于产生任意分布。当所有可接受域均由处于一张图像(或图像集合)的损失之下的单元组成时,整张图像的全卷积训练是等价于patchwise训练的。由于它减少了possible batch的数量,所以相比于patch中的均匀采样要更加的有效。然而,在一张图片中的随机对patch进行选择很容易发生重复。对其空间子集的随机采样约束损失(或者等价为输出与损失之间应用一个DropConnect mask)不包括梯度计算的patches。
如果这样得到的patches仍然有重叠,全卷积网络仍然可以加速训练。如果梯度在多个反向通道上累积,batch就会包含从多个image中的patch。
patchwise训练中的采样可以修正类失衡,并且可以减轻密集patch的空间相关性。在全卷积训练中,类均衡可以用给损失赋权重的方法来实现,并且损失采样可以被用于定位这种空间相关性。
作者发现上采样对于密度预测既快且有效。在FCN中,上采样是通过反卷积来实现的。原文中提到,以因子f进行的上采样是输入步长为1/f的卷积。只要f为整数,上采样一个自然而然的方式就是用输出步长为f来进行反卷积
作者挑选了AlexNet,VGGNet,GoogleNet(仅使用了最后的损失层,并且抛弃了平均池化层)作为基础分别实现FCN网络。具体做法如下:
-丢弃最后的分类层
-将所有的的全连接层改为卷积层
-在每个粗糙的输出位置的上加一个通道维度为21的1×1的卷积层来预测每个类(包括背景)的分数,接下来是一个反卷积层来双线性上采样这个粗糙输出到pixel-dense输出
这三种设计在PASCAL VOC 2011数据集上的表现如下:
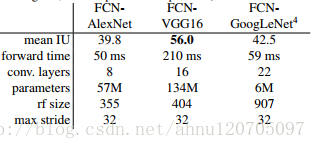
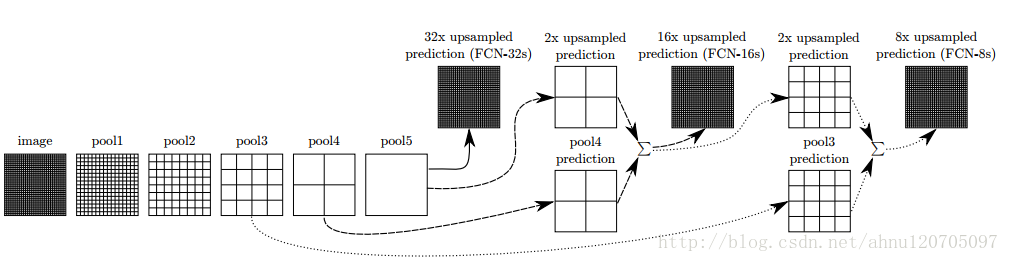
作者分析在最后的预测层上32像素步长限制了上采样输出中细节的比例(FCN-32s),所以用更佳的步长引入了更低的层,形成了FCN-16s。
-在pool4上加入一个1×1的卷积层。然后在步长32的conv7上加入一个2×的上采样层并对两者的predictions进行求和以融合计算出的predictions。初始化2×的上采样层为双线性插值,并允许参数可被学习
-以步长16上采样回原图像尺寸
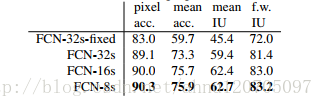
在进一步融入更低的层后,形成了FCN-8s,其在FCN-16s的基础上,
-将conv7和pool4的融合的predictions与经过2×的上采样层处理的pool3进行融合
这三种结构在PASCAL VOC2011的表现如下:
整个网络结构图如下:
根据论文,我使用tensorflow简单实现了FCN网络。代码如下:
def inference(images,keep_prob=0.85):
channel=images.get_shape()[-1].value
with tf.name_scope('conv1_1') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,channel,64],dtype=tf.float32,stddev=1e-1),name='weights')
conv=tf.nn.conv2d(images,kernel,[1,1,1,1],padding='SAME')
biases=tf.Variable(tf.constant(0.0,shape=[64],dtype=tf.float32),trainable=True,name='biases')
bias=tf.nn.bias_add(conv,biases)
conv1_1=tf.nn.relu(bias,name=scope)
with tf.name_scope('conv1_2') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,64,64],dtype=tf.float32,stddev=1e-1),name='weights')
conv=tf.nn.conv2d(conv1_1,kernel,[1,1,1,1],padding='SAME')
biases=tf.Variable(tf.constant(0.0,shape=[64],dtype=tf.float32),trainable=True,name='biases')
bias=tf.nn.bias_add(conv,biases)
conv1_2=tf.nn.relu(bias,name=scope)
pool1=tf.nn.max_pool(conv1_2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME',name='pool2')
#print('conv1',pool1.shape)
with tf.name_scope('conv2_1') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,64,128],dtype=tf.float32,stddev=1e-1),name='weights')
conv=tf.nn.conv2d(pool1,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[128], dtype=tf.float32), trainable=True, name='biases')
bias=tf.nn.bias_add(conv,biases)
conv2_1=tf.nn.relu(bias,name=scope)
with tf.name_scope('conv2_2') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,128,128],dtype=tf.float32,stddev=1e-1),name='weights')
conv=tf.nn.conv2d(conv2_1,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[128], dtype=tf.float32), trainable=True, name='biases')
bias=tf.nn.bias_add(conv,biases)
conv2_2=tf.nn.relu(bias,name=scope)
pool2=tf.nn.max_pool(conv2_2,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME',name='pool2')
#print('conv2',pool2.shape)
with tf.name_scope('conv3_1') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,128,256],dtype=tf.float32,stddev=1e-1),name='weights')
conv=tf.nn.conv2d(pool2,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases')
bias=tf.nn.bias_add(conv,biases)
conv3_1=tf.nn.relu(bias,name=scope)
with tf.name_scope('conv3_2') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,256,256],dtype=tf.float32,stddev=1e-1),name='weights')
conv=tf.nn.conv2d(conv3_1,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3_2=tf.nn.relu(bias,name=scope)
with tf.name_scope('conv3_3') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,256,256],dtype=tf.float32,stddev=1e-1),name='weights')
conv=tf.nn.conv2d(conv3_2,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv3_3=tf.nn.relu(bias,name=scope)
pool3=tf.nn.max_pool(conv3_3,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME',name='pool3')
#print('conv3',pool3.shape())
with tf.name_scope('conv4_1') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,256,512],dtype=tf.float32,stddev=1e-1),name='weights')
conv=tf.nn.conv2d(pool3,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases')
bias=tf.nn.bias_add(conv,biases)
conv4_1=tf.nn.relu(bias,name=scope)
with tf.name_scope('conv4_2') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,512,512],dtype=tf.float32,stddev=1e-1),name='weights')
conv=tf.nn.conv2d(conv4_1,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv4_2=tf.nn.relu(bias,name=scope)
with tf.name_scope('conv4_3') as scope:
kernel=tf.Variable(tf.truncated_normal([3,3,512,512],dtype=tf.float32,stddev=1e-1),name='weights')
conv=tf.nn.conv2d(conv4_2,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv4_3=tf.nn.relu(bias,name=scope)
pool4=tf.nn.max_pool(conv4_3,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME',name='pool4')
#print('conv4',pool4.shape())
with tf.name_scope('conv5_1') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool4, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv5_1 = tf.nn.relu(bias, name=scope)
with tf.name_scope('conv5_2') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv5_1, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv5_2 = tf.nn.relu(bias, name=scope)
with tf.name_scope('conv5_3') as scope:
kernel = tf.Variable(tf.truncated_normal([3, 3, 512, 512], dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv5_2, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[512], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv5_3 = tf.nn.relu(bias, name=scope)
pool5 = tf.nn.max_pool(conv5_3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name='pool5')
#print('conv5',pool5.shape)
with tf.name_scope('conv6') as scope:
kernel = tf.Variable(tf.truncated_normal([7, 7, 512, 4096], dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(pool5, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[4096], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv6=tf.nn.relu(bias,name=scope)
conv6_dropout=tf.nn.dropout(conv6,keep_prob=keep_prob)
#print('conv6',conv6_dropout.shape)
with tf.name_scope('conv7') as scope:
kernel = tf.Variable(tf.truncated_normal([1, 1, 4096, 4096], dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv6_dropout, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[4096], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv7=tf.nn.relu(bias,name=scope)
conv7_dropout=tf.nn.dropout(conv7,keep_prob=keep_prob)
#print('conv7',conv7_dropout.shape)
with tf.name_scope('conv8') as scope:
kernel = tf.Variable(tf.truncated_normal([1, 1, 4096, NUM_OF_CLASSESS], dtype=tf.float32, stddev=1e-1), name='weights')
conv = tf.nn.conv2d(conv7_dropout, kernel, [1, 1, 1, 1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[NUM_OF_CLASSESS], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
conv8=tf.nn.relu(bias,name=scope)
conv8_dropout=tf.nn.dropout(conv8,keep_prob=keep_prob)
#print('conv8',conv8_dropout.shape)
with tf.name_scope('deconv1') as scope:
deconv_shape1 = pool4.get_shape()
kernel=tf.Variable(tf.truncated_normal([4,4,deconv_shape1[3].value,NUM_OF_CLASSESS],stddev=0.02),name='weights')
conv = tf.nn.conv2d_transpose(conv8_dropout,kernel,tf.shape(pool4),strides=[1,2,2,1],padding='SAME')
biases=tf.Variable(tf.constant(0.0, shape=[deconv_shape1[3].value], dtype=tf.float32), trainable=True, name='biases')
bias = tf.nn.bias_add(conv, biases)
fuse_1=tf.add(bias,pool4,name='fuse_1')
#print('deconv1',fuse_1.shape)
with tf.name_scope('deconv2') as scope:
deconv_shape2=pool3.get_shape()
kernel = tf.Variable(tf.truncated_normal([4, 4, deconv_shape2[3].value,deconv_shape1[3].value],stddev=0.02), name='weights')
conv = tf.nn.conv2d_transpose(fuse_1, kernel, tf.shape(pool3),strides=[1,2,2,1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[deconv_shape2[3].value], dtype=tf.float32), trainable=True,name='biases')
bias = tf.nn.bias_add(conv, biases)
fuse_2 = tf.add(bias, pool3,name='fuse_2')
#print('deconv2',fuse_2.shape)
with tf.name_scope('deconv3') as scope:
shape=tf.shape(images)
print(images.shape)
deconv_shape3=tf.stack([shape[0],shape[1],shape[2],NUM_OF_CLASSESS])
kernel=tf.Variable(tf.truncated_normal([16, 16, NUM_OF_CLASSESS,deconv_shape2[3].value],stddev=0.02),name='weights')
conv=tf.nn.conv2d_transpose(fuse_2, kernel,deconv_shape3,strides=[1,8,8,1], padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[NUM_OF_CLASSESS], dtype=tf.float32), trainable=True,name='biases')
bias_final = tf.nn.bias_add(conv, biases)
#print('deconv3',bias_final.shape)
annotation_pred=tf.argmax(bias_final,dimension=3,name='prediction')
return tf.expand_dims(annotation_pred,dim=3),bias_final














 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









