







UiPath-浅谈自带OCR
缘起
OCR ,全名Optical Character Recognition(光学字符识别),实现方法各家不同,从业务层面讲就是识别图片文字。有些朋友可能会感觉这技术是近几年才耳熟起来的,但实际上OCR是二战前就诞生的老家伙了,而且针对中文的OCR也是文革前就有人在搞的。多亏了现代发展的AI buff,这位老大哥的才渐渐崭露头角,这些年宣传的人尽皆知的支付宝扫福就是由机器学习技术支撑的超大型文字识别项目。感慨到此为止,下面简单讲讲OCR在RPA中的表现。
常见形式
- 国内宣传的最厉害的就是百度、阿里、讯飞、Abbyy这些个巨头,最常见的使用方法,就是利用网络请求把图片的数据传给他们的服务器,然后坐等识别结果。这个在UiPath里使用请求活动就可以在流程中实现
好处是图片识别功能的培训几位霸霸已经做好了,不需要占用太大的本地空间部署,可以不用指定识别目标,而且可以享受到AI buff,真香。
坏处嘛,信息稍微涉密都不要想用这种方法。 - 使用本地引擎,比如UiPath自身就可以使用微软、谷歌还有Tesseract的引擎;或者本地下载别的OCR产品,UiPath可以使用命令行去指挥。
好处首先就是安全,也不会受网络状况影响。
坏处就是需要相应的语言包,本地占地大一些,环境的配置会比较麻烦。而且,没有AI助攻。 - 第三种对使用方要求比较高,需要把一整套产品放在自己的内网服务器上,以上好处几乎全占!就是AI的助攻程度受培训程度影响,而单家公司自己培训的话材料会相对没那么丰富。
UiPath+本地引擎
水文至此为止,下面以微软引擎为例拎出UiPath+自带引擎的实现方式来讲。
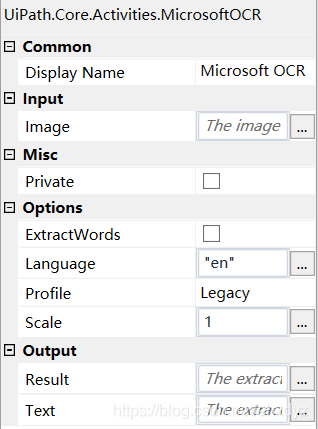
上面是Microsoft OCR的属性面板,官方文档(https://docs.uipath.com/activities/docs/microsoft-ocr)介绍的很详细,里面需要注意的是三个小东西:
- Input\Image: 要识别谁
- Options\Language: 用什么标准识别
- Output\Text: 交作业
好了,那我们就用纯中文与纯英文例子看一下自带的微软引擎性能。
- 纯英文,来一段小诗:

这是结果,可以看到,两秒就ok了,而且识别率为100%:

- 纯中文,让我们来段价值观:

同样是两秒,识别率同样是100%

些蜜汁空格影响心情,略微处理一下:

不错,以上测试用的Language分别是"chi_sim"和"en",示例程序我简单的打包了下,以供交流,下载的朋友请按照自己系统的语言版本相应的调整Process中的。另外,如果需要识别更的语言版本,可以参考此文献:https://docs.uipath.com/studio/docs/installing-ocr-languages
限制
上面讲了这么多,很多人可能会觉得OCR这么快又这么准,然后产生这个技术很万能的错觉,然而细心的朋友肯定注意到了,上面测试的图片都有着最常规的电脑字体、有最单纯的底色、还有最好的清晰度,更重要的是,内容涉及的语言种类非常单一。这些要素有哪怕一个不理想,OCR都很难提供又快又好的结果,比如这个我在之前文章发的一张表格:
这是识别结果,感觉可以打碎很多人的幻想。。。

但是这种集合了复合型信息的图片也不是完全无解,最省力的就是买OCR产品的定制服务;单纯利用UiPath自带的功能的话,也可以集合Image Exists,Set Clipping Region等实现不同样式的分类也相应的拒识,不过运行时间会长很多。

















 2302
2302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









