






目录
引言
在深度学习中,神经网络的初始化是训练的重要一环。PyTorch提供了model.apply()方法,它是一个强大的工具,可以方便地应用函数到神经网络的各个模块上,包括网络本身。本文将深入介绍model.apply()的使用方法,并通过代码实例演示如何利用这一方法优雅地初始化神经网络的权值。
正文
了解model.apply()方法
在PyTorch中,model.apply(fn)方法的作用是将函数fn应用到神经网络的各个模块上,包括网络本身。这为我们提供了一个简洁而灵活的方式来操作神经网络的组件,特别是在初始化参数的情景下,能够使代码更加清晰易懂。
使用方法详解
# 例:定义一个初始化权值的函数
def weights_init_normal(module):
if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
nn.init.normal_(module.weight, mean=0, std=0.01)
nn.init.constant_(module.bias, 0)
# 创建神经网络实例
model = MyAwesomeModel()
# 应用初始化权值函数到神经网络上
model.apply(weights_init_normal)
在上述例子中,我们首先定义了一个weights_init_normal函数,该函数接受一个模块作为参数,然后根据模块的类型进行相应的权值初始化操作。接着,我们创建了一个神经网络实例model,最后通过model.apply(weights_init_normal)一行代码,将初始化权值的操作应用到整个神经网络上。
优势和应用场景
-
清晰而简洁的代码结构: 使用
model.apply()可以将特定操作集中到一个函数中,使代码更易读、更易维护。 -
灵活性: 可以根据需要定义不同的初始化函数,并通过
model.apply()轻松应用到不同的神经网络上,而无需逐层逐层设置。 -
初始化策略统一性: 对于整个神经网络使用相同的初始化策略,提高了训练的一致性。
实例应用
import torch.nn as nn
import torch
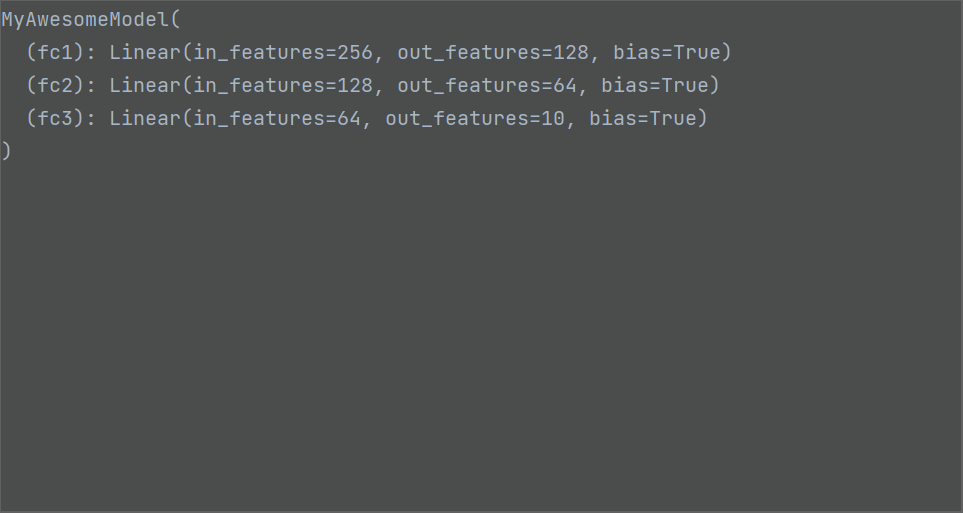
class MyAwesomeModel(nn.Module):
def __init__(self):
super(MyAwesomeModel, self).__init__()
self.fc1 = nn.Linear(256, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
# 定义初始化函数
@torch.no_grad()
def init_weights(m):
print(m)
if type(m) == nn.Linear:
m.weight.fill_(1.0)
print(m.weight)
# 创建神经网络实例
model = MyAwesomeModel()
# 应用初始化权值函数到神经网络上
model.apply(init_weights)
输出结果:
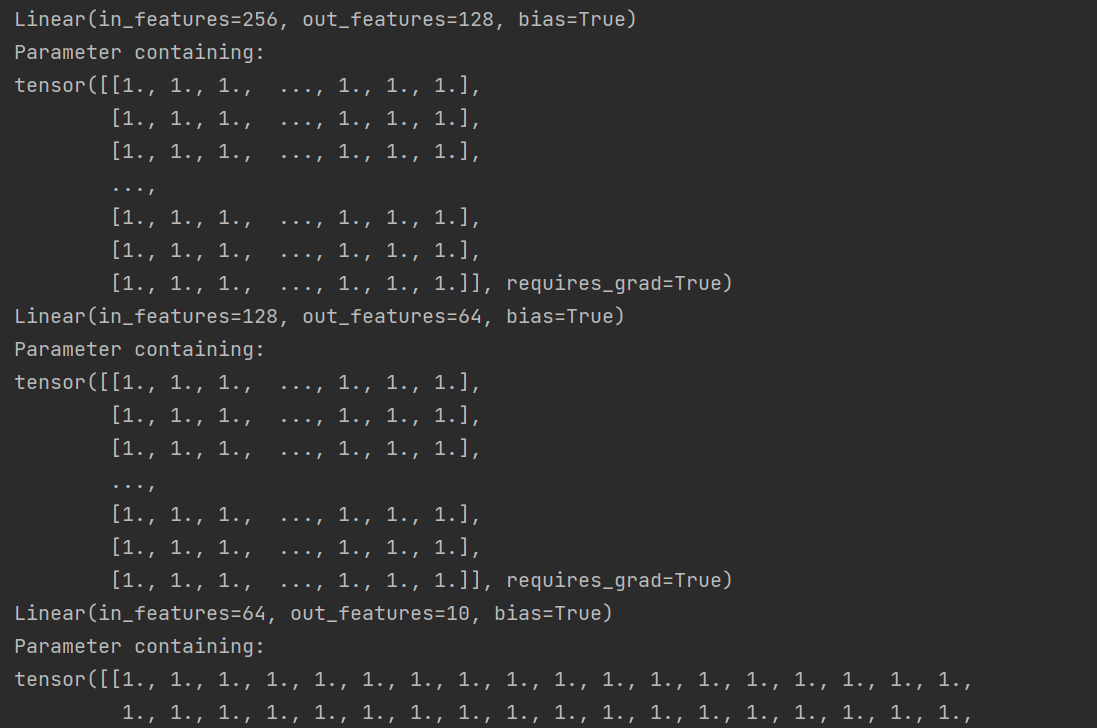
在这个例子中,我们定义了一个新的初始化函数weights_init_xavier,并将其应用到MyAwesomeModel实例上。这展示了model.apply()的灵活性,可以轻松切换不同的初始化策略。
结语
通过model.apply()方法,我们可以更加好地对整个神经网络进行操作,特别是在初始化权值的场景下。这一方法不仅使代码结构更清晰,而且提高了代码的灵活性和可维护性。希望本文对读者理解并应用model.apply()提供了一些帮助。如果有任何疑问或建议,欢迎在评论区留言。感谢阅读!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









