







一、搜索查询强化
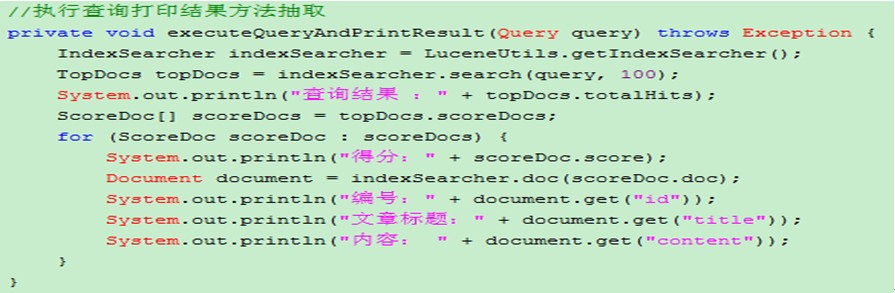
执行查询步骤
第一步 : 获得 Query查询对象
第二步 : 获得IndexSearcher 通过Query对象进行查询
为了方便,每次都打印结果,就抽取了功能为方法
Lucene内建的Query对象
1、TermQuery 词条搜索
词条term是分词最小单位,不能再分词

2、NumericRangeQuery范围搜索
* TermRangeQuery 按照词条范围搜索 ----- 比较字符串
* NumericRangeQuery 按照数字范围搜索 ---- 比较数字
使用NumericRangeQuery ,索引必须 以数字格式存储
NumericField numericField =new NumericField("id", Store.YES, true);
numericField.setIntValue(article.getId());
doc.add(numericField);

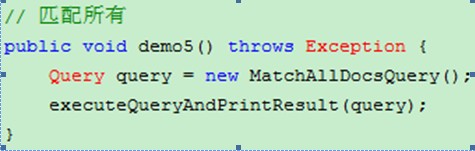
3、MatchAllDocsQuery匹配所有搜索
* 查询索引库 所有内容
4、WildcardQuery模糊搜索 (通配符查询)
使用统配符 进行查询
? 一个字符 * 任意个字符

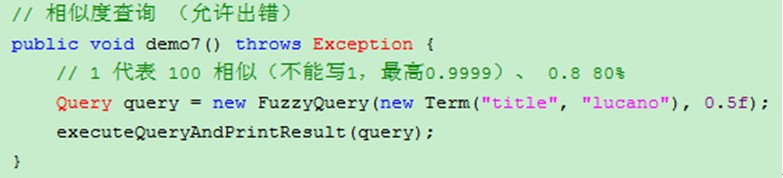
5、FuzzyQuery相似度
主要用于查找不结果时,建议查询内容
6、BooleanQuery布尔搜索
多个Query 组合条件
使用时注意:
1)、单独使用MUST_NOT:无意义,检索无结果。(也不报错)
2)、单独使用SHOULD:结果相当于MUST。
3)、MUST_NOT和MUST_NOT:无意义,检索无结果。(也不报错)
4)、SHOULD和MUST_NOT: 此时SHOULD相当于MUST,结果同MUST和MUST_NOT。
5)、MUST和SHOULD:此时SHOULD无意义,结果为MUST子句的检索结果。
常用组合 :MUST+MUST 、SHOULD+SHOULD、 MUST+MUST_NOT

二、 排序、过滤、分页
1、 检索结果的排序
数据检索结果都是根据得分进行排序的,得分高结果排在前面
搜索排名时,常用算法 tf-idf 算法

SEO 搜索引擎优化 ---- 词频的增加
例子:有很多不同的数学公式可以用来计算TF-IDF。这边的例子以上述的数学公式来计算。词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是lg(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03 * 4=0.12。
boost (激励因子) --- 权重分数
手动设置激励因子:
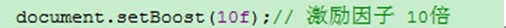
lengthNorm(t.fieldin d) 这个参数和boost一样,在建立索引时,存储在索引库中,1.0/Math.sqrt(numTerms) 和词条数量成反比
存储时设置 Index.ANALYZED_NO_NORMS Index.NO_TANALYZED_NO_NORMS ---- 此时norm 值为1
排序
默认查询是按照得分高低排序,也可以为查询指定 sort对象,完成排序功能,当指定规则后得分将被忽略
Sort sort = new Sort(new SortField(“id”,SortField.INT)); ----- id 升序
Sort sort = new Sort(newSortField("title", SortField.STRING, true)); ------ title 降序
2、过滤 (了解)
过滤器可以对查询结果进行过滤,缩小结果数据范围
过滤器对性能影响很大,一般可以使用查询实现相同的效果
Filter filter =NumericRangeFilter.newIntRange("id", 5, 15, false, true);
TopDocs topDocs =indexSearcher.search(query, filter, 100);
3、 分页查询 (了解)
indexSearcher.search(query, n); 表示查询前多少条, 通过n 完成分页

三、 分词器
Analyzer(分词器)的作用是把一段文本中的词按规则取出所包含的所有词。对应的是Analyzer类,这是一个抽象类,切分词的具体规则是由子类实现的,所以对于不同的语言(规则),要用不同的分词器
分词器两个应用
1) 创建索引时,需要中文分词
2) 搜索索引时, QueryParser.parse(string) 需要分词后再查找。
lucene 提供的分词器就是Analyzer 类的子类对象
工作流程 :
1) 切分关键词 :
例:我是一个好人 , I am a good man .
英文分词 按照空格和标点分词: I 、am 、a 、good 、man
中文分词默认分词器一个字是一个词 : 我、是、一、个、好、人
2) 去除停用词
例:的、了、是、好、 人 good 、 man(一般不查询的词)
主流分词器(第三方) : paoding、 imdict 、 mmseg4j、 ik
以 IK 分词器为例 进行分词讲解
测试 : 测试下lucene自带的ChineseAnalyzer和CJKAnalyzer
需要导入 lucene-analyzers-3.6.2.jar
使用 IK分词器
1、 下载 jar包 IKAnalyzer2012_u6.zip
2、 安装部署
将IKAnalyzer2012.jar 部署于项目的lib目录中
IKAnalyzer.cfg.xml 与stopword.dic 文件放置在src下
3、 IKAnalyzer.cfg.xml配置分析
<entrykey="ext_dict">ext.dic;</entry> 扩展词典(加入我们自己的词汇)
<entry key="ext_stopwords">stopword.dic;</entry> 停用词典
自定义词典 ext.dic编码设置 utf-8 ,如果使用记事本编辑(默认 gbk)

四、 高亮结果显示
1、 相关概念
检索数据时,搜索引擎,针对目标文件,生成一段固定长度的摘要内容,用于搜索结果列表的显示, 在显示过程中将关键字标记为高亮显示,摘要默认大小是 100 字符。
高亮显示原理:在高亮内容两端添加<em></em>标签, 再通过css修饰 em 标记为高亮
2、 使用lucene框架提供高亮器进行高亮显示
导入lucene-highlighter-3.6.2.jar、lucene-memory-3.6.2.jar
3、 创建高亮器Highlighter
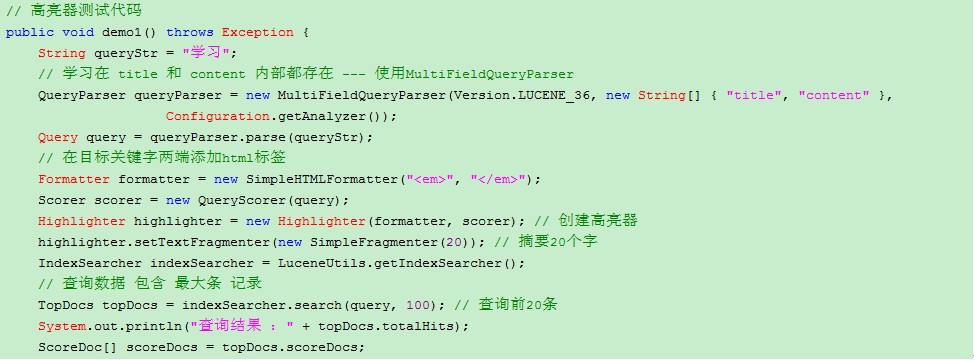

highlighter.setTextFragmenter(newNullFragmenter());把全部文本进行高亮返回,此时摘要大小将不再起作用
4、 使用高亮器去查询索引库,返回高亮标记后摘要内容
String text =highlighter.getBestFragment(Configuration.getAnalyzer(), "content",doc.get("content"));
使用上面方法获得BestFragment(关键字最集中的一段),如果查找title和content多个字段,出现title中查找内容,content中没有内容,所以要判断是否为空,空就截取一部分为内容,不为空就替换摘要。















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









