







一、 搜索引擎的历史
萌芽:Archie、Gopher
起步:Robot(网络机器人)的出现与spider(网络爬虫)
发展:excite、galaxy、yahoo
繁荣:infoseek,altaVista,Google和baidu
搜索技术发展依赖网络机器人和网络爬虫
网络机器人:互联网上完成特定功能的程序
网络爬虫:专门用于搜索领域程序,主要目的,去互联网上 下载需要资源
二、 搜索技术在日常中应用
本地软件 : 文档内检索、本地文件检索、 myeclipse 帮助文档索引
站内检索 : BBS和BLOG 提供文章搜索功能 (贴吧)
垂直网站资源检索 : 818 工作网 (显示智联招聘、前程无忧等招聘网站的查询结果 )
互联网中各种资源的搜索 : baidu、google (所有领域的资源)
信息检索的过程
1)构建文本库
2)建立索引
3)进行搜索
4)对结果进行排序
三、 倒排索引
传统查找采用线性查询,从前向后查找
使用倒排索引,将关键单词出现位置建立索引,通过查询索引库,获知内容位置,对于文档很大的情况,检索效率也是非常高的
四、 lucene 快速入门
Lucene:一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供,Lucene提供了一 个简单却强大的应用程式接口,能够做全文索引和搜寻,在Java开发环境里Lucene是一个成 熟的免费开放源代码工具
注:Lucene并不是现成的搜索引擎产品,但可以用来制作搜索引擎产品,lucene可以对任何资源建立索引, 前提必须要获得资源对应文本内容
课程以3.6.2 讲解, 最新版本 lucene4.3 (lucene4 和 lucene3 开发差别很大 )
ApacheSolr: Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器
什么是全文检索
全文检索:计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章 中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查 找的结果反馈给用户的检索方式
入门步骤
1、 去官网下载 lucene 开发包
lucene目录: 开发核心包 lucene-core-3.6.2.jar
contrib目录:存放插件包
docs目录:存放文档
2、 使用lucene 在原有数据存储上, 对数据建立索引
软件开发,数据应该保存在数据库, 数据库中提供索引技术
lucene索引与数据库的索引功能的区别
数据库不可能对所有字段建立索引(默认根据主键、外键有约束列检索索引),数据库建立索引并没 有采用分词算法(也不是全文索引),lucene可以对目标文件分层进行全文检索,lucene在做模糊查询 的时候,数据库是不能做索引的,而lucene的优点主要发生在模糊查询上的索引建立上。
3、 对存储数据转换Document(lucene框架中可以被索引的数据对象 )
Field(Stringname, String value, Field.Store store, Field.Index index) 代表一个字段

4、 生成索引
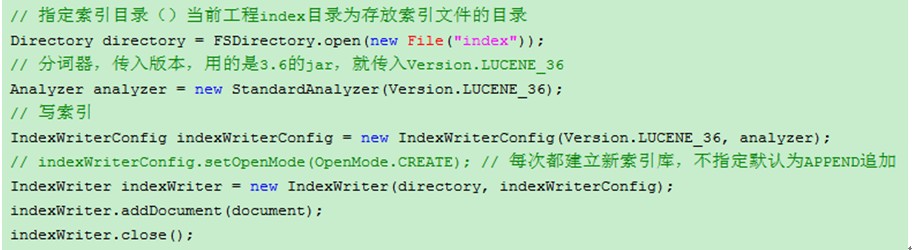
5、 通过第三方工具 Luke 查看索引文件内容
注:luke 只能支持到 lucene3.x
lukeall-3.5.0.jar可执行jar文件 、 DOS命令行运行方式java -jar 文件名
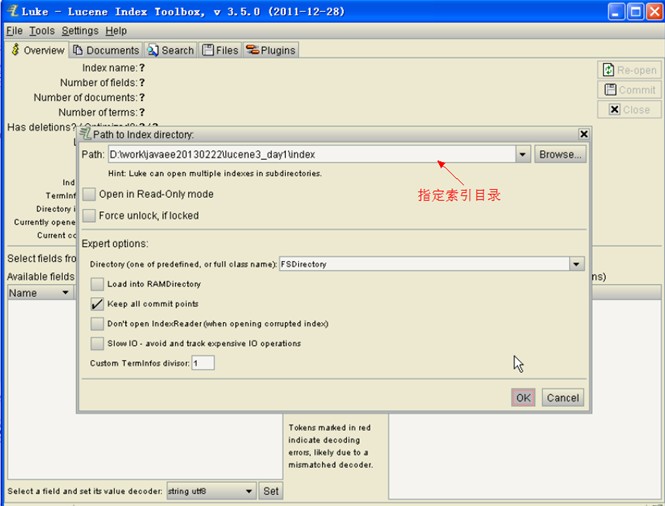
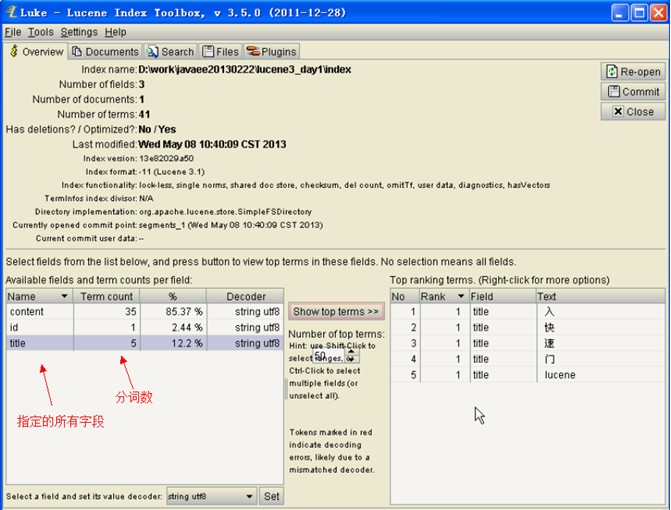
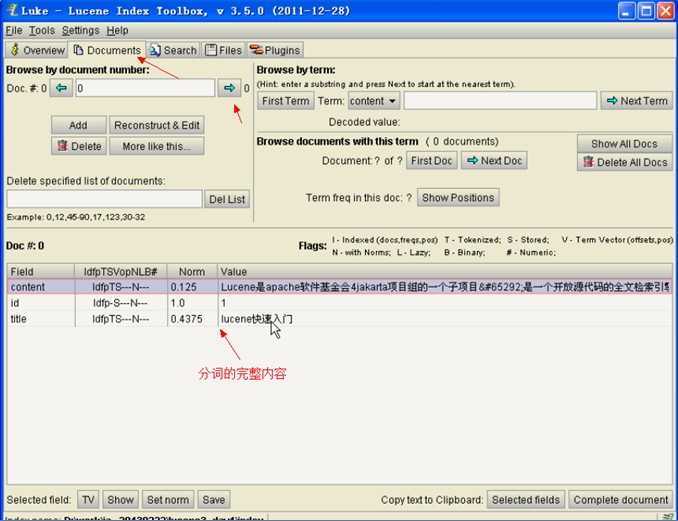
6、 索引库的查询

Lucene开发 API详细分析
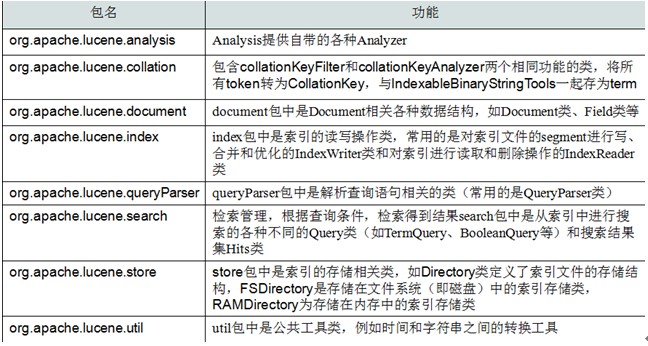
1、 包结构
2、 创建索引相关 API
Directory 索引操作目录
Analyzer 分词器
Document索引中文档对象
Field文档内部数据信息
IndexWriterConfig索引生成配置信息
IndexWriter 索引生成对象
基本步骤:
·第一步 : 指定创建索引目录
Directorydirectory = FSDirectory.open(new File("index")); // FSDirectory 打开磁盘目录
·第二步 : 指定分词器
new StandardAnalyzer(Version.LUCENE_36); 建立标准分词器
使用不同版本lucene 需要传入不同 Version对象
·第三步 : 转换数据为Document对象
document.add(new Field(name, value ,store, index)) ;
name : 通常实体类属性名
value : 属性值
store : Store.YES 存储 、Store.NO 不存储
注:这里存储指的就是,是否将数据保存到document文档数据区
index : 是否索引
Index.NO 不建立索引 (在索引区没有数据,该字段不可以查询)
Index.ANALYZED分词建立索引 "lucene入门" ----- "lucene","入" ,"门"
Index.NOT_ANALYZED不分词建立索引 "lucene入门" ---- "lucene入门"
Index.ANALYZED_NO_NORMS 分词建立索引,不存放权重信息
Index.NOT_ANALYZED_NO_NORMS不分词建立索引,不存放权重信息
注:NORMS(权重):影响排名,计算得分,如果 ANALYZED_NO_NORMS不存放权重信息,默认 值为1.0。NORM 由分词频率决定,如果不存放权重,性能更好
·第四步 创建索引
indexWriterConfig.setOpenMode(OpenMode.APPEND);//默认索引追加
indexWriterConfig.setOpenMode(OpenMode.CREATE);//每次新建索引库
案例: 通过图书案例,了解哪些数据需要存储的,哪些数据需要索引的
书号:存储、索引、不分词(用户输入完整书号,不用模糊查询)
书名:存储、索引、分词(用户输入部分书名模糊查询)
作者名:存储、索引、不分词
书的出版日期:存储(用户没有查询要求)
书的摘要:索引、分词(没有完整显示信息需要)
书的价格:存储(不查询、需要显示)
注:数据要不要被查询 -----要就索引,不要就不索引
数据查询时是完整查询还是模糊查询 ----完整查询就不分词,模糊查询就分词
查询数据结果中要不要有该数据 ----有就存储,没有就不存储
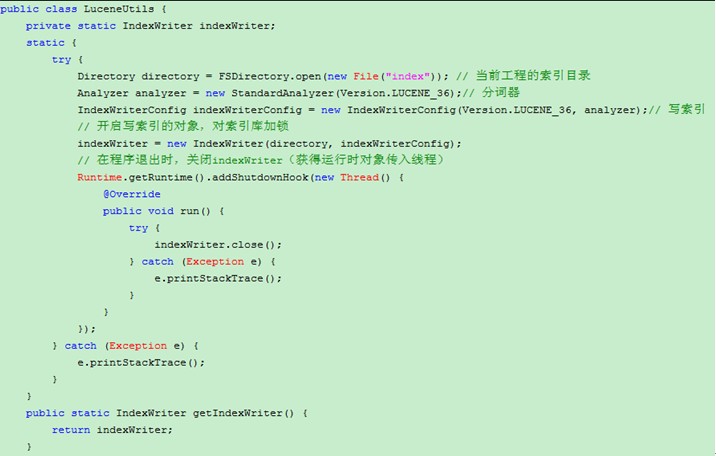
3、 如果多个线程同时对一个索引库进行写入,是不可以的
当创建一个 IndexWriter的时候,就会对索引库进行加锁,确保同一时间只能由一个IndexWriter向索引库写入,如果当对一个索引库创建了多个 IndexWriter时会发生异常:org.apache.lucene.store.LockObtainFailedException: Lock obtain timed out:NativeFSLock@D:\work\javaee20130222\lucene3_day1\index\write.lock
解决方法:确保一个索引库只能有一个IndexWriter对象,需要创建工具类,将其放到static块中
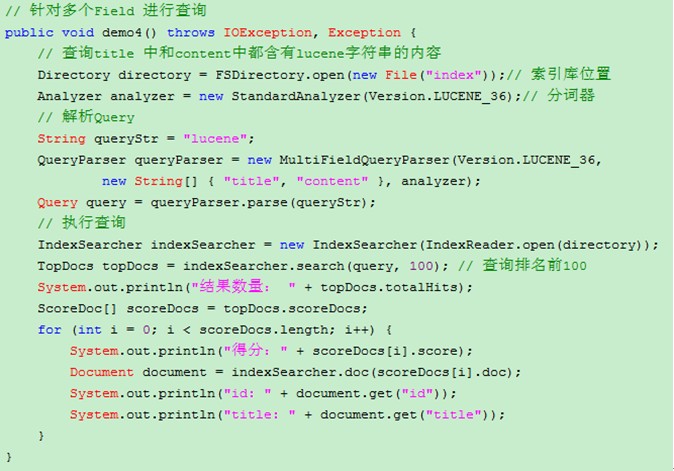
4、 查询索引API 详细分析
QueryParser 查询解析器,将查询字符串解析为Query对象
* MultiFieldQueryParser 可以匹配多个Field
默认QueryParser 只能查询 一个Field,如果要从多个Field中进行查询,使用 MultiFieldQueryParser
Term 搜索分词的最小单位
一个Term对象有两个String类型的域组成:字段的名称和字段的值
TermQuery 搜索最小单位的查询(不用分词器)
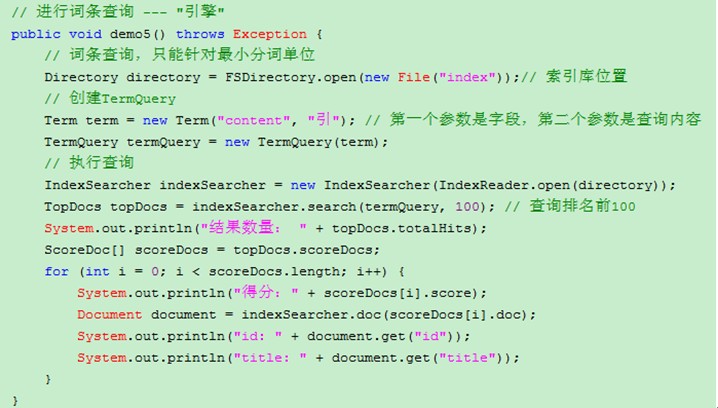
IndexSearcher 索引查询对象
对于IndexSearcher 对象没有线程安全问题,如果将IndexSearch获得写入工具方法,该对象无需static
TopDocs 查询结果排名前n文档对象
totalHits属性:代表查询的总结果数
scoreDocs属性:返回得分文档数组
ScoreDoc 得分文档对象
store属性 查询得分
doc属性 文档内部编号
ssh环境中使用 lucene对数据进行索引(提高hibernate检索性能)
注:需要在进行数据表增删改查同时, 维护索引库的增删改查
1、 实现SSH 的CURD 操作
2、 在CURD 数据库表的同时, 操作索引库
导入 lucene-core-3.6.2.jar
3、 在保存Article文章数据时,为Article对象数据创建索引
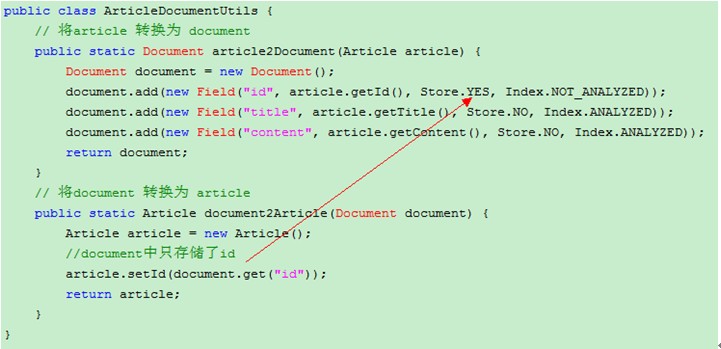
编写工具类ArticleDocumentUtils ,完成 Article对象 和 Document 相互转换
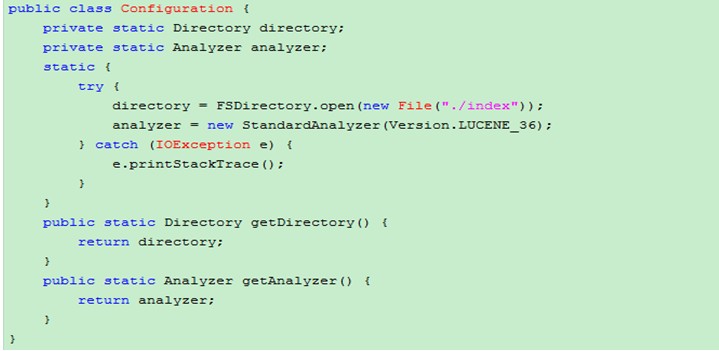
编写工具类Configuration提供获得索引Directory对象和 Analyzzer 分词器
编写工具类LuceneUtils 获得 IndexWriter和IndexSearcher

4、 索引CURD
添加索引 indexWriter.addDocument(document);

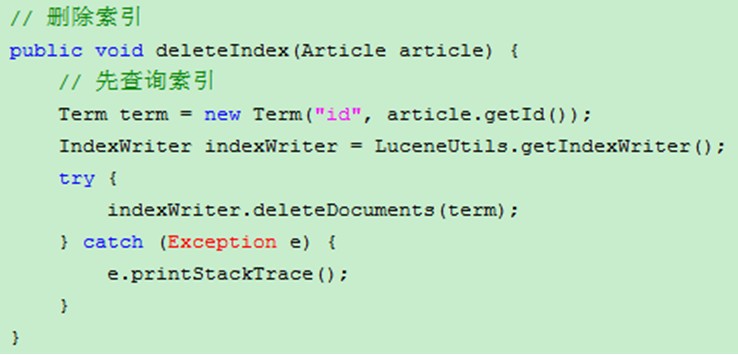
删除索引
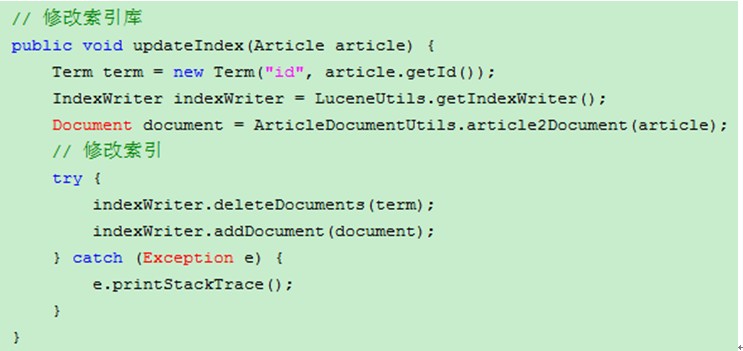
修改索引 indexWriter.updateDocument(term,document);
注:(不进行修改,因为性能很差),一般都是先删除再创建。
查询索引 (用于非主键字段 like模糊查询,先查询索引库获得数据id ,再通过id 查询数据表)
注:根据id 查询基本上不用索引库,因为数据库的本身对 id 有索引,只需查询数据库就行了。
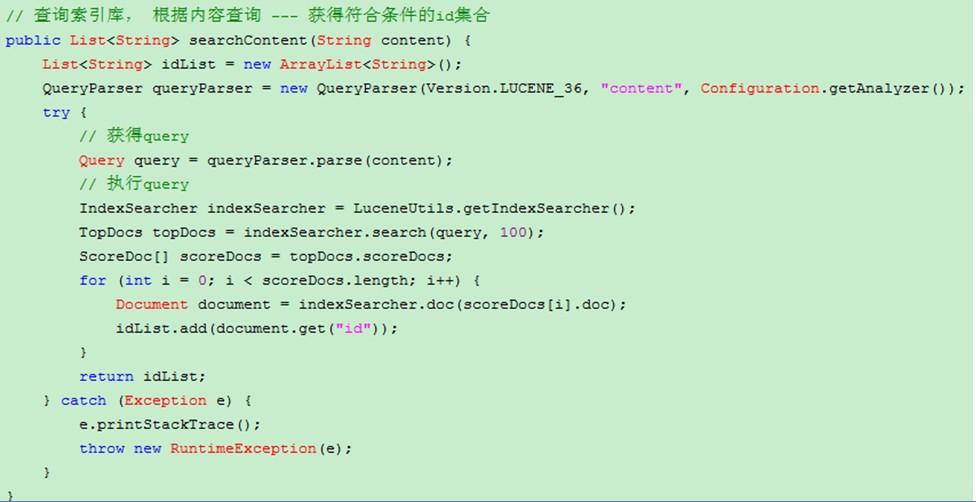
索引的调优
1、 合并因子 mergeFactor
默认情况下,每创建一个对象就会创建一组索引文件
例:通过 mergePolicy.setMergeFactor(4); 设置合并因子(四个对象以上创建索引就合并)

手动合并索引方法 LuceneUtils.get IndexWriter().optimize();(已过时)
好处: 减少硬盘上索引文件数量
2、 使用RAMDirectory
RAMDirectory是内存的一个区域,当虚拟机退出后,里面的内容也会随之消失,RAMDirectory的性能 要好于FSDirectory, 因此可以结合使用,在虚拟机退出时,将RAM内容转到FSDirectory
案例一 : 使用RAMDirectory ,当虚拟机退出,索引库数据丢失

案例二: JVM运行时,读取FSDirectory中索引 ---- RAMDirectory 操作RAMDirectory
在JVM 停止之前,将RAMDirectory 数据写入 FSDirectory
注意:必须设置 OpenMode.CREATE,否则会多出分词数据。















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









