







ConcurrentHashMap原理,以及在jdk7和jdk8版本的区别
-
ConcurrentHashMap是线程安全的数组,是HashTable的替代品,同为线程安全,其性能要比HashTable更好
-
HashMap不是线程安全:
在并发环境下,可能会形成环状链表(扩容时可能造成,具体原因自行百度google或查看源码分析),导致get操作时,cpu空转,所以,在并发环境中使用HashMap是非常危险的 -
HashTable是线程安全的:
HashTable和HashMap的实现原理几乎一样,
差别:
HashTable不允许key和value为null;
HashTable是线程安全的。HashTable线程安全的策略实现代价却比较大,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞,见下图:
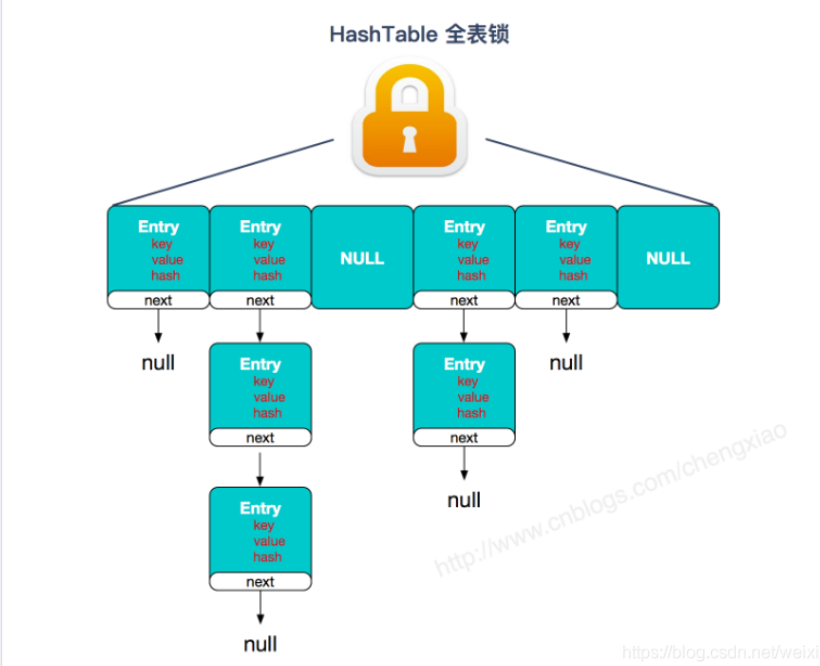
这个时候,ConcurrentHashMap诞生了,不但是线程安全的,而且由于分段锁的存在, 性能上也很非常优秀
JDK7 :
数据结构: ReentrantLock + Segment + HashEntry, 一个Segment中包含一个HashEntry数组,每个HashEntry又是一个链表结构
元素查询: 二次hash,第一次定位Segment,第二次定位元素所在的链表的头部
锁 : Segment分段锁, Segment继承了ReentrantLock ,锁定操作的Segment,其他的Segment不受影响,并发度为Segment的个数,
可以通过构造函数指定,数组扩容不会影响其他的segment,get无需加锁,volatile保证内存可见性
使用 volatile 修饰共享变量后,每个线程要操作变量时会从主内存中将变量拷贝到本地内存作为副本,当线程操作变量副本并写回主内存后,会通过 CPU 总线嗅探机制告知其他线程该变量副本已经失效,需要重新从主内存中读取。
volatile 保证了不同线程对共享变量操作的可见性,也就是说一个线程修改了 volatile 修饰的变量,当修改后的变量写回主内存时,其他线程能立即看到最新值。
接下来我们就聊聊一个比较底层的知识点:总线嗅探机制。
总线嗅探机制
在现代计算机中,CPU 的速度是极高的,如果 CPU 需要存取数据时都直接与内存打交道,在存取过程中,CPU 将一直空闲,这是一种极大的浪费,所以,为了提高处理速度,CPU 不直接和内存进行通信,而是在 CPU 与内存之间加入很多寄存器,多级缓存,它们比内存的存取速度高得多,这样就解决了 CPU 运算速度和内存读取速度不一致问题。
由于 CPU 与内存之间加入了缓存,在进行数据操作时,先将数据从内存拷贝到缓存中,CPU 直接操作的是缓存中的数据。但在多处理器下,将可能导致各自的缓存数据不一致(这也是可见性问题的由来),为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,而嗅探是实现缓存一致性的常见机制。
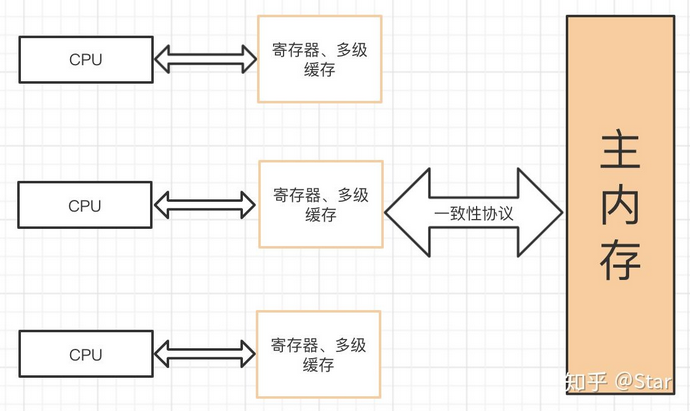
注意,缓存的一致性问题,不是多处理器导致,而是多缓存导致的。
嗅探机制工作原理:每个处理器通过监听在总线上传播的数据来检查自己的缓存值是不是过期了,如果处理器发现自己缓存行对应的内存地址修改,就会将当前处理器的缓存行设置无效状态,当处理器对这个数据进行修改操作的时候,会重新从主内存中把数据读到处理器缓存中。
注意:基于 CPU 缓存一致性协议,JVM 实现了 volatile 的可见性,但由于总线嗅探机制,会不断的监听总线,如果大量使用 volatile 会引起总线风暴。所以,volatile 的使用要适合具体场景。
使用 volatile 和 synchronized 锁都可以保证共享变量的可见性。相比 synchronized 而言,volatile 可以看作是一个轻量级锁,所以使用 volatile 的成本更低,因为它不会引起线程上下文的切换和调度。但 volatile 无法像 synchronized 一样保证操作的原子性。
volatile 的原子性问题
所谓的原子性是指在一次操作或者多次操作中,要么所有的操作全部都得到了执行并且不会受到任何因素的干扰而中断,要么所有的操作都不执行。
在多线程环境下,volatile 关键字可以保证共享数据的可见性,但是并不能保证对数据操作的原子性。也就是说,多线程环境下,使用 volatile 修饰的变量是线程不安全的。
要解决这个问题,我们可以使用锁机制,或者使用原子类(如 AtomicInteger)。
这里特别说一下,对任意单个使用 volatile 修饰的变量的读 / 写是具有原子性,但类似于 flag = !flag 这种复合操作不具有原子性。简单地说就是,单纯的赋值操作是原子性的。
容器中有多把锁,每一把锁锁一段数据,这样在多线程访问时不同段的数据时,就不会存在锁竞争了,这 样便可以有效地提高并发效率。这就是ConcurrentHashMap所采用的”分段锁”思想,见下图:
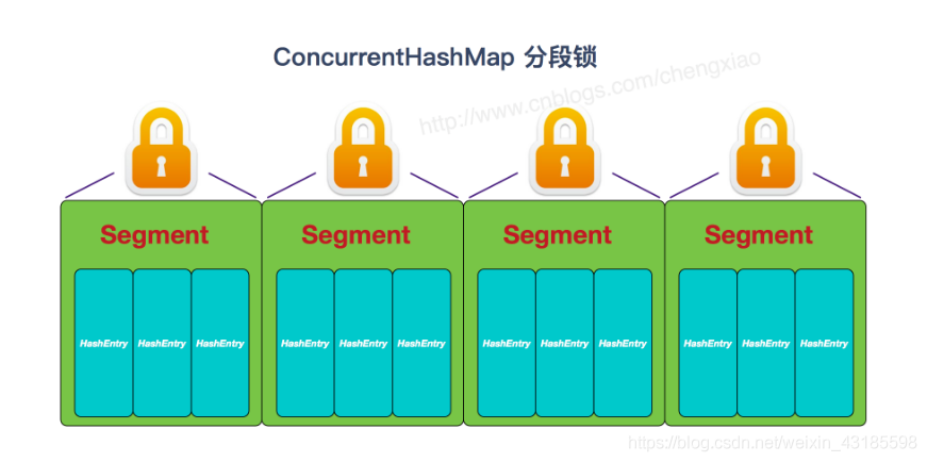
JDK8 :
数据结构: Synchronized + CAS +Node +红黑树.Node的val和next都用volatile保证,保证可见性,查找,替换,赋值操作都使用CAS
为什么在有Synchronized 的情况下还要使用CAS
因为CAS是乐观锁,在一些场景中(并发不激烈的情况下)它比Synchronized和ReentrentLock的效率要高,当CAS保障不了线程安全的情况下(扩容或者hash冲突的情况下)转成Synchronized 来保证线程安全,大大提高了低并发下的性能.
锁 : 锁是锁的链表的head的节点,不影响其他元素的读写,锁粒度更细,效率更高,扩容时,阻塞所有的读写操作(因为扩容的时候使用的是Synchronized锁,锁全表),并发扩容.
读操作无锁 :
- Node的val和next使用volatile修饰,读写线程对该变量互相可见
是Synchronized锁,锁全表),并发扩容.
读操作无锁 :
- Node的val和next使用volatile修饰,读写线程对该变量互相可见
- 数组用volatile修饰,保证扩容时被读线程感知















 1038
1038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









