






MapReduce 原理与 Python 实践
1. MapReduce 原理
以下是个人在MongoDB和Redis实际应用中总结的Map-Reduce的理解
Hadoop 的 MapReduce 是基于 Google - MapReduce: Simplified Data Processing on Large Clusters 的一种实现。对 MapReduce 的基本介绍如下:
MapReduce is a programming model and an associated implementation for processing and generating large data sets. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.
MapReduce 是一种编程模型,用于处理大规模的数据。用户主要通过指定一个 map 函数和一个 reduce 函数来处理一个基于key/value pair的数据集合,输出中间的基于key/value pair的数据集合;然后 再创建一个Reduce函数用来合并所有的具有相同中间key值的中间value值。看到 map/reduce 很容易就联想到函数式编程,而实际上论文中也提到确实受到 Lisp 和其它函数式编程语言的启发。以 Python 为例,map/reduce 的用法如下:
from functools import reduce
from operator import add
ls = map(lambda x: len(x), ["ana", "bob", "catty", "dogge"])
# print(list(ls))
# => [3, 3, 5, 5]
reduce(add, ls)
# => 16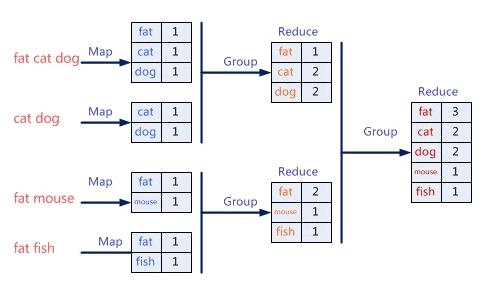
MapReduce 的优势在于对大规模数据进行切分(split),并在分布式集群上分别运行 map/reduce 并行加工,而用户只需要针对数据处理逻辑编写简单的 map/reduce 函数,MapReduce 则负责保证分布式运行和容错机制。Hadoop 的 MapReduce 虽然由 Java 实现,但同时提供 Streaming API 可以通过标准化输入/输出允许我们使用任何编程语言来实现 map/reduce。
以官方提供的 WordCount 为例,输入为两个文件:
hadoop fs -cat file0
# Hello World Bye World
hadoop fs -cat file1
# Hello Hadoop Goodbye Hadoop利用 MapReduce 来计算所有文件中单词出现数量的统计。MapReduce 的运行过程如下图所示:
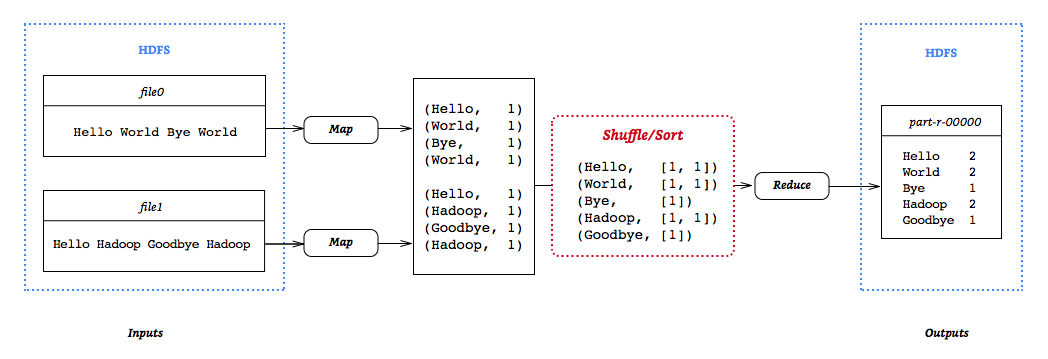
2.Python map/reduce
Hadoop 的 Streaming API 通过 STDIN/STDOUT 传递数据,因此 Python 版本的 map 可以写作:
#!/usr/bin/env python3
import sys
def read_inputs(file):
for line in file:
line = line.strip()
yield line.split()
def main():
file = sys.stdin
lines = read_inputs(file)
for words in lines:
for word in words:
print("{}\t{}".format(word, 1))
if __name__ == "__main__":
main()
运行一下:
chmod +x map.py
echo "Hello World Bye World" | ./map.py
Hello 1
#World 1
#Bye 1
#World 1
reduce 函数以此读取经过排序之后的 map 函数的输出,并统计单词的次数:
#!/usr/bin/env python3
import sys
def read_map_outputs(file):
for line in file:
yield line.strip().split("\t", 1)
def main():
current_word = None
word_count = 0
lines = read_map_outputs(sys.stdin)
for word, count in lines:
try:
count = int(count)
except ValueError:
continue
if current_word == word:
word_count += count
else:
if current_word:
print("{}\t{}".format(current_word, word_count))
current_word = word
word_count = count
if current_word:
print("{}\t{}".format(current_word, word_count))
if __name__ == "__main__":
main()
reduce 的输入是排序后的 map 输出:
chmod +x reduce.py
echo "Hello World Bye World" | ./map.py | sort | ./reduce.py
# Bye 1
# Hello 1
# World 2
这其实与 MapReduce 的执行流程是一致的,下面我们通过 MapReduce 来执行(已启动 Hadoop),需要用到 hadoop-streaming-2.6.4.jar,不同的 Hadoop 版本位置可能不同:
cd $HADOOP_INSTALL && find ./ -name "hadoop-streaming*.jar"
# ./share/hadoop/tools/lib/hadoop-streaming-2.6.4.jar
mkdir wordcount -p wordcount/input
cd wordcount
echo "Hello World Bye World" >> input/file0
echo "Hello Hadoop Goodbye Hadoop" >> input/file1
hadoop jar $HADOOP_INSTALL/share/hadoop/tools/lib/hadoop-streaming-2.6.4.jar \
-input $(pwd)/input \
-output output \
-mapper $(pwd)/map.py \
-reducer $(pwd)/reduce.py
执行完成之后会在 output 目录产生结果:
hadoop fs -ls output
# Found 2 items
# -rw-r--r-- 1 rainy rainy 0 2016-03-13 02:15 output/_SUCCESS
# -rw-r--r-- 1 rainy rainy 41 2016-03-13 02:15 output/part-00000
hadoop fs -cat output/part-00000
# Bye 1
# Goodbye 1
# Hadoop 2
# Hello 2
# World 2
3. 总结
Hadoop 的架构让 MapReduce 的实际执行过程简化了许多,但这里省略了很多细节的内容,尤其是针对完全分布式模式,并且要在输入文件足够大的情况下才能体现出优势。这里处理纯文本文档作为示例,但我想要做的是通过连接 MongoDB 直接读取数据到 HDFS 然后进行 MapReduce 处理,但考虑到数据量仍然不是很大(700,000条记录)的情况,不知道是否会比直接 Python + MongoDB 更快。














 1724
1724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









