







维特比算法
术语“维特比路径”和“维特比算法”也被用于寻找观察结果最有可能解释相关的动态规划算法。例如在统计句法分析中动态规划算法可以被用于发现最可能的上下文无关的派生(解析)的字符串,有时被称为“维特比分析”。
维特比算法由安德鲁·维特比(Andrew Viterbi)于1967年提出,用于在数字通信链路中解卷积以消除噪音。[1] 此算法被广泛应用于CDMA和GSM数字蜂窝网络、拨号调制解调器、卫星、深空通信和802.11无线网络中解卷积码。现今也被常常用于语音识别、关键字识别、计算语言学和生物信息学中。例如在语音(语音识别)中,声音信号做为观察到的事件序列,而文本字符串,被看作是隐含的产生声音信号的原因,因此可对声音信号应用维特比算法寻找最有可能的文本字符串。
算法
假设给定隐式马尔可夫模型(HMM)状态空间 ,初始状态
,初始状态 的概率为
的概率为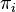 ,从状态 到状态
,从状态 到状态 的转移概率为
的转移概率为 。 令观察到的输出为
。 令观察到的输出为 。 产生观察结果的最有可能的状态序列
。 产生观察结果的最有可能的状态序列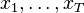 由递推关系给出:[2]
由递推关系给出:[2]
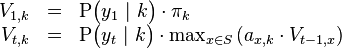
此处 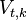 是前
是前 个最终状态为
个最终状态为 的观测结果最有可能对应的状态序列的概率。 通过保存向后指针记住在第二个等式中用到的状态
的观测结果最有可能对应的状态序列的概率。 通过保存向后指针记住在第二个等式中用到的状态 可以获得维特比路径。声明一个函数
可以获得维特比路径。声明一个函数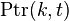 ,它返回若
,它返回若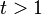 时计算 用到的 值 或若
时计算 用到的 值 或若 时的 . 这样:
时的 . 这样:
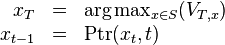
这里我们使用了arg max的标准定义。
算法复杂度为 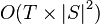
伪代码
首先是一些问题必要的设置。 设观察值空间为  、 状态空间为
、 状态空间为 、 观察值序列为
、 观察值序列为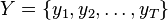 ,
, 为
为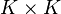 转移矩阵 ,其中
转移矩阵 ,其中 为从状态
为从状态 转移到
转移到 的转移概率、
的转移概率、 为
为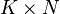 放射矩阵(emission matrix),其中
放射矩阵(emission matrix),其中 为在状态 观察到
为在状态 观察到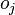 的概率、 大小为
的概率、 大小为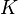 的初始概率数组
的初始概率数组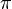 , 为
, 为 的概率。 我们称路径
的概率。 我们称路径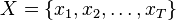 为生成观察值 的状态序列。
为生成观察值 的状态序列。
在这个动态规划问题中, 我们构造了两个大小为 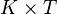 的二维表
的二维表 。
。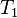 的每个元素,
的每个元素,![T_1[i,j]](http://upload.wikimedia.org/math/1/4/5/145921562569266e962da115c49711d0.png) ,保存生成
,保存生成 时最有可能的路径
时最有可能的路径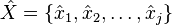 ,
, 的概率。
的概率。 的每个元素,
的每个元素,![T_2[i,j]](http://upload.wikimedia.org/math/f/b/9/fb945d40a0bfde3b05741736be37a8bf.png) , 保存最有可能路径
, 保存最有可能路径 ,
,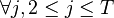 的
的 。
。
我们按  增序填充两个表
增序填充两个表![T_1[i,j],T_2[i,j]](http://upload.wikimedia.org/math/5/6/d/56de792d9c03670c514c98c949ece706.png) 。
。
-
![T_1[i,j]=\max_{k}{(T_1[k,j-1]\cdot A_{ki}\cdot B_{ij})}](http://upload.wikimedia.org/math/6/6/3/663035997c88de15c2b32559a10c4267.png) ,
,
-
![T_2[i,j]=\arg\max_{k}{(T_1[k,j-1]\cdot A_{ki}\cdot B_{ij})}](http://upload.wikimedia.org/math/7/6/6/7664d7c9db6fa3dbc933cd19983e6f35.png)
输入: 观察空间,则
, 大小为
的转移矩阵
的放射矩阵
Bi
A04 T2[i,1]←0 A05 end for A06 for i←2,3,...,T do A07 for each state sj do A08 T1[j,i]←
A09 T2[j,i]←
A10 end for A11 end for A12 zT←
A13 xT←szT A14 for i←T,T-1,...,2 do A15 zi-1←T2[zi,i] A16 xi-1←szi-1 A17 end for A18 return X A19 end function
例子
想象一个乡村诊所。村民有着非常理想化的特性,要么健康要么发烧。他们只有问诊所的医生的才能知道是否发烧。 聪明的医生通过询问病人的感觉诊断他们是否发烧。村民只回答他们感觉正常、头晕或冷。
假设一个病人每天来到诊所并告诉医生他的感觉。医生相信病人的健康状况如同一个离散马尔可夫链。病人的状态有两种“健康”和“发烧”,但医生不能直接观察到,这意味着状态对他是“隐含”的。每天病人会告诉医生自己有以下几种由他的健康状态决定的感觉的一种:正常、冷或头晕。这些是观察结果。 整个系统为一个隐马尔可夫模型(HMM)。
医生知道村民的总体健康状况,还知道发烧和没发烧的病人通常会抱怨什么症状。 换句话说,医生知道隐马尔可夫模型的参数。 这可以用Python语言表示如下:
states = ('Healthy', 'Fever') observations = ('normal', 'cold', 'dizzy') start_probability = {'Healthy': 0.6, 'Fever': 0.4} transition_probability = { 'Healthy' : {'Healthy': 0.7, 'Fever': 0.3}, 'Fever' : {'Healthy': 0.4, 'Fever': 0.6}, } emission_probability = { 'Healthy' : {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1}, 'Fever' : {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6}, }
在这段代码中, 起始概率start_probability 表示病人第一次到访时医生认为其所处的HMM状态,他唯一知道的是病人倾向于是健康的。这里用到的特定概率分布不是均衡的,如转移概率大约是{'Healthy': 0.57, 'Fever': 0.43}。 转移概率transition_probability表示潜在的马尔可夫链中健康状态的变化。在这个例子中,当天健康的病人仅有30%的机会第二天会发烧。放射概率emission_probability表示每天病人感觉的可能性。假如他是健康的,50%会感觉正常。如果他发烧了,有60%的可能感觉到头晕。

病人连续三天看医生,医生发现第一天他感觉正常,第二天感觉冷,第三天感觉头晕。 于是医生产生了一个问题:怎样的健康状态序列最能够解释这些观察结果。维特比算法解答了这个问题。
# Helps visualize the steps of Viterbi. def print_dptable(V): print " ", for i in range(len(V)): print "%7d" % i, print for y in V[0].keys(): print "%.5s: " % y, for t in range(len(V)): print "%.7s" % ("%f" % V[t][y]), print def viterbi(obs, states, start_p, trans_p, emit_p): V = [{}] path = {} # Initialize base cases (t == 0) for y in states: V[0][y] = start_p[y] * emit_p[y][obs[0]] path[y] = [y] # Run Viterbi for t > 0 for t in range(1,len(obs)): V.append({}) newpath = {} for y in states: (prob, state) = max([(V[t-1][y0] * trans_p[y0][y] * emit_p[y][obs[t]], y0) for y0 in states]) V[t][y] = prob newpath[y] = path[state] + [y] # Don't need to remember the old paths path = newpath print_dptable(V) (prob, state) = max([(V[len(obs) - 1][y], y) for y in states]) return (prob, path[state])
函数viterbi 具有以下参数: obs 为观察结果序列, 例如 ['normal', 'cold', 'dizzy'];states 为一组隐含状态; start_p 为起始状态概率; trans_p 为转移概率; 而emit_p 为放射概率。 为了简化代码,我们假设观察序列 obs 非空且 trans_p[i][j] 和emit_p[i][j] 对所以状态 i,j 有定义。
在运行的例子中正向/维特比算法使用如下:
def example(): return viterbi(observations, states, start_probability, transition_probability, emission_probability) print example()
维特比算法揭示了观察结果 ['normal', 'cold', 'dizzy'] 最有可能由状态序列 ['Healthy', 'Healthy', 'Fever']产生。 换句话说,对于观察到的活动, 病人第一天感到正常,第二天感到冷时都是健康的,而第三天发烧了。
维特比算法的计算过程可以直观地由格图表示。 维特比路径本质上是穿过格式结构的最短路径。 诊所例子的格式结构如下, 黑色加粗的是维特比路径:
![Animation of the trellis diagram for the Viterbi algorithm. After Day 3, the most likely path is ['Healthy', 'Healthy', 'Fever']](http://zh.wikipedia.org/wiki/File:Viterbi_animated_demo.gif)
在实现维特比算法时需注意许多编程语言使用浮点数计算,当 p 很小时可能会导致结果下溢。 避免这一问题的常用技巧是在整个计算过程中使用对数概率,在对数系统中也使用了同样的技巧。 当算法结束时,可以通过适当的幂运算获得精确结果。
注
参考资料
- Viterbi AJ. Error bounds for convolutional codes and an asymptotically optimum decoding algorithm. IEEE Transactions on Information Theory. 1967.April,13 (2): 260–269. doi:10.1109/TIT.1967.1054010. (note: the Viterbi decoding algorithm is described in section IV.) Subscription required.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









