




 本文探讨了数据挖掘的概念、流程,包括数据预处理、分类、聚类、关联规则和回归等方法,强调了国际会议和期刊的重要性。同时,提及了大数据时代的特点以及隐私保护和云计算在数据处理中的角色。
本文探讨了数据挖掘的概念、流程,包括数据预处理、分类、聚类、关联规则和回归等方法,强调了国际会议和期刊的重要性。同时,提及了大数据时代的特点以及隐私保护和云计算在数据处理中的角色。
数据挖掘:
(又名:知识发现)
Mining?Warehousing?
怎么做数据挖掘?
【数据+数据处理(模型、公式、算法)+高性能计算】–>数据挖掘
–>才能实现数据的价值
一些相关的重要的国际会议:
International Conference on Data Mining
International Conference on Data Engineering
International Conference on Machine Learning
International Joint Conference on Artificial Intelligence
Pacific-Asia Conference on Knowledge Discovery and Data Mining
ACM SIGKDD Conference on Knowledge Discovery and Data Mining
一些相关的重要的期刊:
Data Mining and Knowledge Discovery
Neural Networks and Learning systems
Knowledge and Data engineering
Information science
IEEE Computation Intelligence society
IEEE computer society
Big Data:
Volume层面:Terabytes—>Zettabytes (Tb–Zb)
Variety:Stuctured—>Stuctured&Unstructured (结构化数据–非结构化数据)
Velocity:Batch—>Streaming Data (对算法处理流数据的能力提出更高的要求)
From Data To Intelligence
dataBase–Information–Knowledge–Decision Support
数据分析的流程
1、数据存放在不同的数据源:文本文件Flat Files、CRM系统、ERP系统、或其他的数据库中
2、对所有的数据进行融合(融合的过程被称为“ETL”:提取、转换、装载)
3、装在数据仓库中(包含元(原)数据、真实数据)
4、最后对数据进行各种各样的分析(Data Analysis、Reporting、Data Mining)
数据挖掘流程抽象理解:
Define problem、Data Collection、Data Preparation、Data modelling、Interpretation/evaluation、Implement/deploy model
一、分类
(类似机器学习的分类,通过一些已知标签的对象去学习,然后判断新的对象,进行分类)
数据分为训练集和测试集,训练集用来生成模型、测试集用来评估模型。
(1)Confusion Matrix(混淆矩阵)
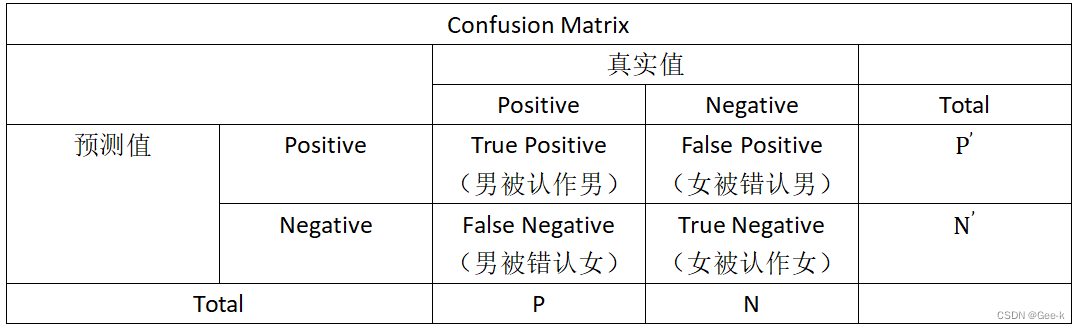
TPR=TP/(TP+FN)
TNR=TN/(TN+FP)
Accuracy=(TP+TN)/(P+N)
(2)Receiver Operating Characteristic
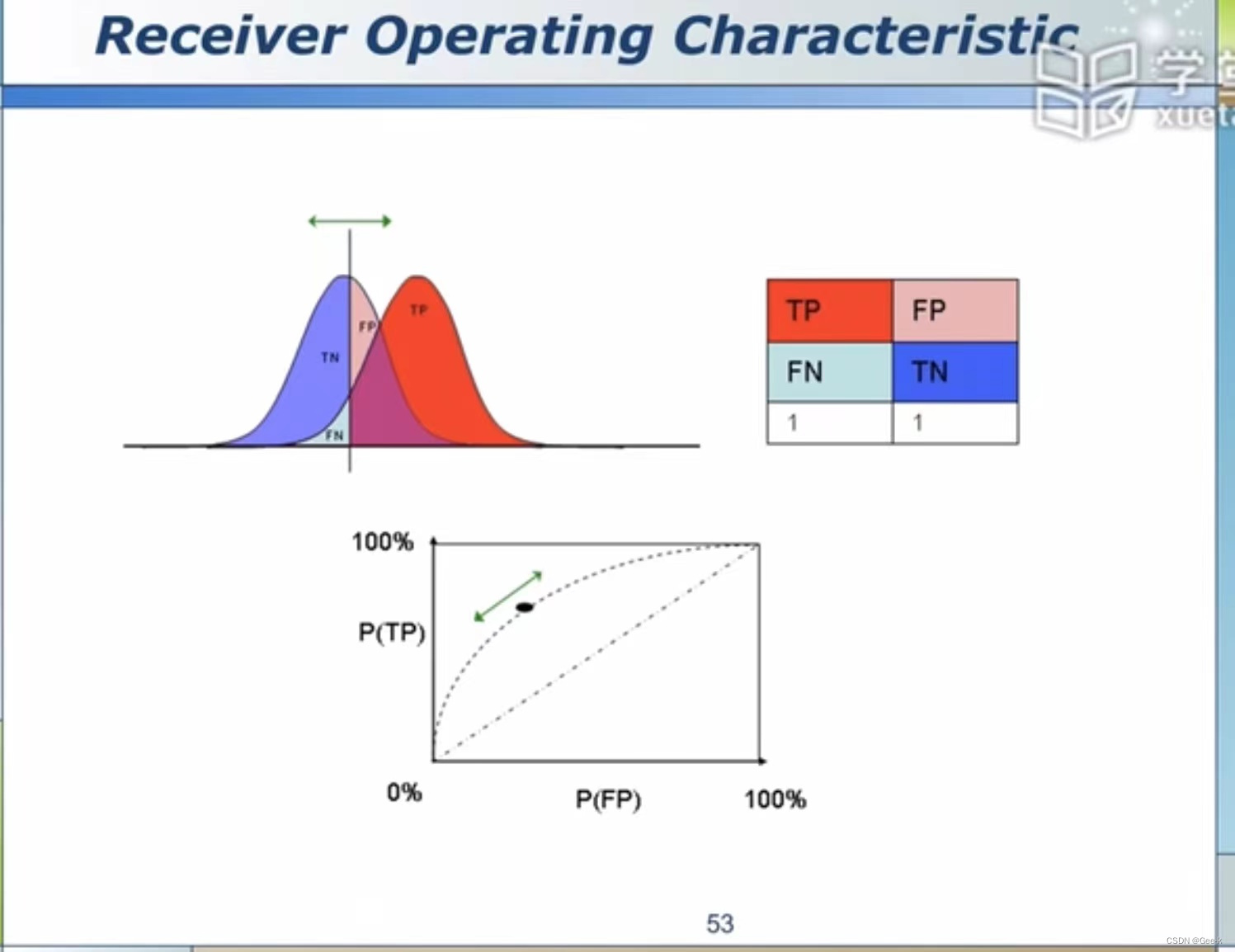
横坐标为身高;两个高斯代表男、女;中间这条线为阈值
超过阈值的话,所有的男人会被判断为男人,所有女人也会被判断为男人
Lift Analysis:用来评价模型在实际使用中的效果
二、聚类Clustering和其他数据挖掘问题
聚类是没有事先人为标签的(无监督)
距离度量:欧氏距离、曼哈顿距离、马氏距离
常用聚类算法:K-Means、Sequential Leader、Affinity Propagation
应用:客户划分、图像分割、社交网络分析
一些其他数据挖掘问题
(1)关联规则Association Rule
譬如通过一个人的购物记录,学习各个商品之间的关系,某些商品会被关联购买
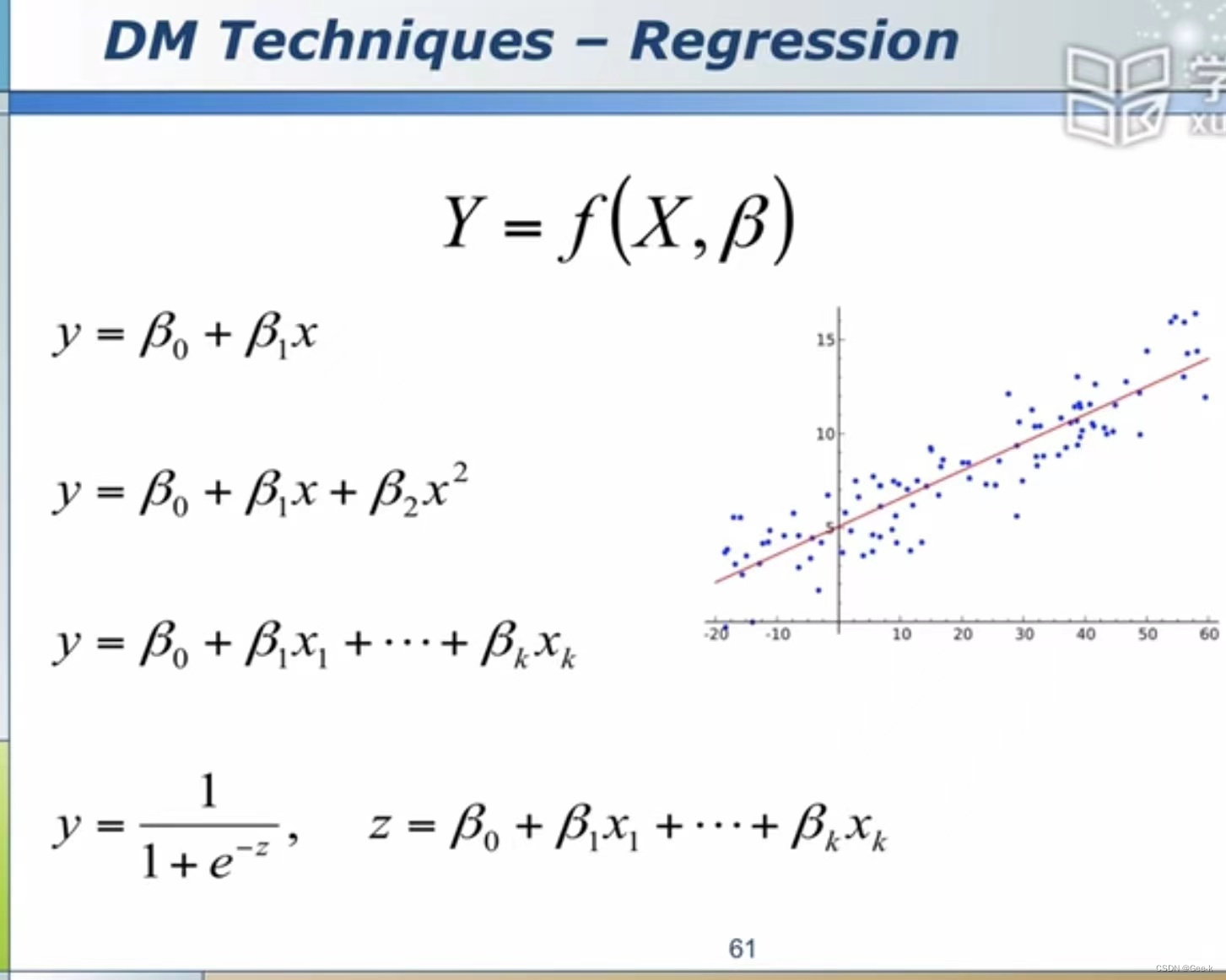
(2)Regression回归
线性回归(拟合后可能是直线或曲线)、
多项式的表达方式(Y=βX)中的β和x是线性相关的
三、隐私保护和并行计算
隐私保护:譬如针对一些设计隐私的问题,一般情况下大多数人不会提交真实回答,这样就导致做数据分析数据挖掘的人得不到真实的结果。
Question1:你是否食用毒品
Question2:你是否不食用毒品
计算得到真实反馈:(注意区分大小写P)

云计算:
很多人会将云计算错认为网络服务
把服务器当做资源,在网站使用高峰时期租云服务器,提升资源的利用率。
把计算或者软件、硬件当做一种服务,像付水费电费一样,用的时候再买。


















 2189
2189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









