







 本文介绍了数据库切分的背景,包括OLTP与OLAP的区别,关系型与NoSQL数据库的选择,以及数据切分的两种模式。接着详细讲解了Mycat数据库中间件,它的原理、应用场景及核心功能。Mycat拦截SQL并根据分片规则路由到正确节点,解决了数据切分后带来的挑战,如跨节点join和多数据源管理。此外,还阐述了Mycat中的重要概念,如逻辑库、逻辑表、分片节点和全局序列号。最后,文章提到了Mycat的安装配置和分片join的处理策略。
本文介绍了数据库切分的背景,包括OLTP与OLAP的区别,关系型与NoSQL数据库的选择,以及数据切分的两种模式。接着详细讲解了Mycat数据库中间件,它的原理、应用场景及核心功能。Mycat拦截SQL并根据分片规则路由到正确节点,解决了数据切分后带来的挑战,如跨节点join和多数据源管理。此外,还阐述了Mycat中的重要概念,如逻辑库、逻辑表、分片节点和全局序列号。最后,文章提到了Mycat的安装配置和分片join的处理策略。
第一章 概述
11 数据库切分概述
1-1-1 OLTP和OLAP
联机事务处理(OLTP)也称为面向交易的处理系统,其基本特征是原始数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果。
联机分析处理(OLAP)是指通过多维的方式对数据进行分析、查询和报表,可以同数据挖掘工具、统计分析
工具配合使用,增强决策分析功能。
1-1-2 关系型数据库和NoSQL数据库
| 0 | 关系型数据库 | NoSQL 数据库 |
|---|---|---|
| 特点 | -数据关系模型基于关系模型,结构化存储,完整性约束。-基于二维表及其之间的联系,需要连接、并、交、差、除等数据操作。-采用结构化的查询语言(SQL)做数据读写。-操作需要数据的一致性,需要事务甚至是强一致性。 |
|
| 优点 |
|
|
| 缺点 |
|
|
1-1-3 数据切分
数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。一种是按照不同的表(或者
Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据
表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
垂直切分优缺点:
| 优点 | 缺点 |
|---|---|
|
|
水平切分优缺点:
| 优点 | 缺点 |
|---|---|
|
|
共同的缺点:
- 引入分布式事物的问题。
- 跨节点join的问题。
- 跨节点合并排序分页问题。
- 多数据源管理问题。
针对数据源管理,目前有两种思路:
1. 客户端模式,在每个应用程序模块中配置管理自己需要的一个(或者多个)数据源,直接访问各个数据库,在模块内完成数据的整合。
2. 通过中间代理层来统一管理所有的数据源,后端数据库集群对前端应用程序透明。
由于数据切分后数据join的难度,关于数据切分的经验:
- 第一原则:能不切分尽量不要切分
- 第二原则:如果要切分一定要选择合适的切分规则,提前规划好。
- 第三原则:数据切分尽量通过数据冗余或表分组(Table Group)来降低跨库join的可能。
- 第四原则:由于数据库中间件对数据join实现的优劣难以把握,而且实现高性能难度极大,业务读取尽量少使用多表join。
第二章 MyCat简介
2-1 MyCat概述
Mycat 背后是阿里曾经开源的知名产品——Cobar。Cobar 的核心功能和优势是 MySQL 数据库分片。
2-1-1 MyCat原理
Mycat 的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的 SQL 语句,首先对 SQL 语句做了
一些特定的分析:如分片分析、路由分析、读写分离分析、缓存分析等,然后将此 SQL 发往后端的真实数据库,
并将返回的结果做适当的处理,最终再返回给用户。
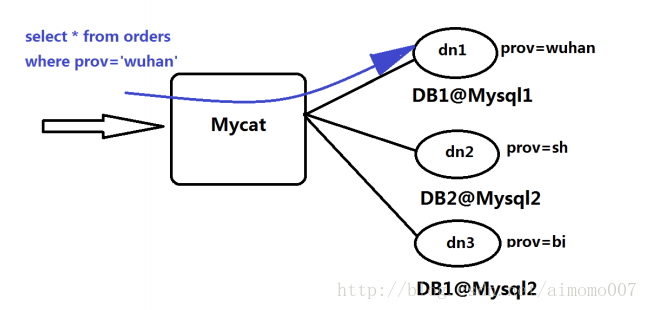
执行过程:
上述图片里,Orders 表被分为三个分片 datanode(简称 dn),这三个分片是分布在两台 MySQL Server 上
(DataHost),即 datanode=database@datahost 方式,因此你可以用一台到 N 台服务器来分片,分片规则为
(sharding rule)典型的字符串枚举分片规则,一个规则的定义是分片字段(sharding column)+分片函数(rule
function),这里的分片字段为 prov 而分片函数为字符串枚举方式。
当 Mycat 收到一个 SQL 时,会先解析这个 SQL,查找涉及到的表,然后看此表的定义,如果有分片规则,
则获取到 SQL 里分片字段的值,并匹配分片函数,得到该 SQL 对应的分片列表,然后将 SQL 发往这些分片去执
行,最后收集和处理所有分片返回的结果数据,并输出到客户端。以 select * from Orders where prov=?语句为
例,查到 prov=wuhan,按照分片函数,wuhan 返回 dn1,于是 SQL 就发给了 MySQL1,去取 DB1 上的查询
结果,并返回给用户。
如果上述 SQL 改为 select * from Orders where prov in (‘wuhan’,‘beijing’),那么,SQL 就会发给
MySQL1与MySQL2 去执行,然后结果集合并后输出给用户。但通常业务中我们的 SQL 会有Order By 以及Limit 翻页语法,此时就涉及到结果集在 Mycat 端的二次处理,这部分的代码也比较复杂,而最复杂的则属两个表的 Jion 问题,
为此,Mycat 提出了创新性的 ER 分片
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









