







LruCache是Android3.1提供的一个缓冲类,support包中也有。它对数据的存储采用了近期最少使用算法。
Android开发中,如网络加载图片,如果不进行缓存,那么流量的消耗和体验是很差的。并且Android系统有对每个应用施加了内存限制,一旦超出限制,就看见了常见的OOM的报错。所以我们需要一个有缓存策略的类LruCache,来存放这些图片。
我们从源码来看看,这个高大上的东西如何实现的。
一:看LruCache一般的用法:
int maxMemory = (int) (Runtime.getRuntime().maxMemory()/1024);
int cacheSize = maxMemory/8;
LruCache<String, Bitmap> mCache = new LruCache<String, Bitmap>(cacheSize){
protected int sizeOf(String key, Bitmap value) {
return value.getRowBytes()*value.getHeight()/1024;
};
};这是一般缓存图片时的写法。其中有一个点,为什么重写sizeOf方法?下面分析源码就明白了~
二:源码分析
1.先看看它的成员变量:
private final LinkedHashMap<K, V> map;
/** Size of this cache in units. Not necessarily the number of elements. */
private int size;//当前内存大小
private int maxSize;//最大内存大小
private int putCount;//加入成功就加一,一下的count,分析源码发现没用到,就只是记录一下
private int createCount;//创建成功加一
private int evictionCount;//清除一次加一
private int hitCount;//成功查找到一次加一
private int missCount;//get但不存在2.先看看它的构造器:
/**
* @param maxSize for caches that do not override {@link #sizeOf}, this is
* the maximum number of entries in the cache. For all other caches,
* this is the maximum sum of the sizes of the entries in this cache.
*/
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, <span style="color:#ff0000;">true</span>);
} 。。
。。
3.看看我们常用的put方法:
/**
* Caches {@code value} for {@code key}. The value is moved to the head of
* the queue.
*
* @return the previous value mapped by {@code key}.
*/
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
<span style="color:#ff0000;">size += safeSizeOf(key, value);</span>
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
<span style="color:#ff0000;"> entryRemoved(false, key, previous, value);</span>
}
<span style="color:#ff0000;">trimToSize(maxSize);</span>
return previous;
}
safeSizeOf():其中会为了安全判断参数是否合法,然后调用sizeOf()方法。sizeOf()!我们经常会重写的方法。该方法会返回子项的大小。当put 新数据时,当前大小增加新数据大小,发现有老数据存在,linkedHashMap会覆盖老数据,所以减去老数据大小。
entryRemoved():这个方法也可以选择重写,它会通知删除项的信息。
trimTosize():这个方法很关键,这个方法会判断当前大小是否超出限制,如果超出则删除一些数据。具体看下面。
4.get方法:
public final V get(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
mapValue = map.get(key);
if (mapValue != null) {
hitCount++;
return mapValue;
}
missCount++;
}
/*
* Attempt to create a value. This may take a long time, and the map
* may be different when create() returns. If a conflicting value was
* added to the map while create() was working, we leave that value in
* the map and release the created value.
*/
<span style="color:#ff0000;">V createdValue = create(key);</span>
if (createdValue == null) {
return null;
}
synchronized (this) {
createCount++;
mapValue = map.put(key, createdValue);
if (mapValue != null) {
// There was a conflict so undo that last put
map.put(key, mapValue);
} else {
size += safeSizeOf(key, createdValue);
}
}
if (mapValue != null) {
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
<span style="color:#ff0000;"> trimToSize(maxSize);</span>
return createdValue;
}
}5.trimTosize()
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
<span style="color:#ff0000;"> if (size <= maxSize) {
break;
}</span>
<span style="color:#ff0000;">Map.Entry<K, V> toEvict = map.eldest();</span>
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
<span style="color:#ff0000;">map.remove(key);
size -= safeSizeOf(key, value);</span>
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
可是就实现了LRU呢?那么LruCache就算分析完了,要把重心移到LinkedHashMap了。
6.LinkedHashMap get和put
LinkedHashMap继承HashMap。它自己维护了一个双向循环链表。它没有重写put方法,但是重写了put'方法调用的addNewEntry。这个方法会把最新的放在链表的header项的前面。get方法我们看一下:
@Override public V get(Object key) {
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
if (e == null)
return null;
if (accessOrder)
makeTail((LinkedEntry<K, V>) e);
return e.value;
}
int hash = secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - 1)];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
if (<span style="color:#ff0000;">accessOrder)</span>
<span style="color:#ff0000;">makeTail((LinkedEntry<K, V>) e);</span>
return e.value;
}
}
return null;
}7.makeTail()
private void makeTail(LinkedEntry<K, V> e) {
// Unlink e
e.prv.nxt = e.nxt;
e.nxt.prv = e.prv;
// Relink e as tail
LinkedEntry<K, V> header = this.header;
LinkedEntry<K, V> oldTail = header.prv;
e.nxt = header;
e.prv = oldTail;
oldTail.nxt = header.prv = e;
modCount++;
} 了。目的就是,切断原链表的header和tail,
插入新的entry到header 的前面,就是说是循环链表的尾部。
了。目的就是,切断原链表的header和tail,
插入新的entry到header 的前面,就是说是循环链表的尾部。
下面来个相关的链表图,应该就清晰很多了。网上引用个图:
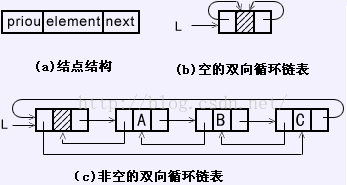
插入新的entry到header的前面,就是说循环链表的尾部:
1.将要插入的entry断开:
e.prv.nxt = e.nxt:将e的前一项的next指向,e的下一项。
e.nxt.prv = e.prv:将e的下一项的pre指向,e的前一项。
2.插入:
LinkedEntry<K, V> header = this.header:获取到此时的header
LinkedEntry<K, V> oldTail = header.prv;:获取到此时的tail
e.nxt = header:将e的next指向header
e.prv = oldTail:将e的pre指向tail。闭环
oldTail.nxt = header.prv = e; header的前一项指向e,tail的下一项指向e。
最后再看一下LruCache中到底删除的是链表的哪个地方。
8.eldest
public Entry<K, V> eldest() {
LinkedEntry<K, V> eldest = header.nxt;
return eldest != header ? eldest : null;
}三.总结
LruCache只是来控制大小不超过限制,从而操作LinkedHashMap执行删除。重点都在LinkedHashMap。
LruCache优先删除的是LinkedHashMap中循环双向链表中 :Header 的下一项!当我们调用get,put方法操作某一项的时候,会将此项放在header 的前面,那么此项被删除的优先级是最低的,从而实现了LRU!
希望可以对大家有所帮助,大家发现问题欢迎指正!















 100
100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









