







在使用JS正则表达式时一直对其中诸多的概念和标识符很混乱,最近看了一个视频课程,对正则表达式总结的非常好,本文记录一下学习笔记。
本文的学习来源:http://www.imooc.com/learn/706
附2个图形化显示正则表达式的网站:
http://regexpress.io/
https://regexper.com/
一 RegExp对象
JS通过内置RegExp对象支持正则表达式,实例化RegExp对象的2种方式(与其他JS对象如String的实例化类似):
字面量
字面量:
var reg = /正则表达式文本字符串/gim;
如下图示例

其中
\bis\b为正则表达式文本字符串,//之间存放该正则表达式文本字符串注:使用字面量实例化正则表达式时,不要加引号。
构造函数
构造函数:
var reg = new RegExp("正则表达式文本字符串","g");
如下图示例

注:使用构造函数实例化正则表达式时,如使用到
\需要转义,即使用\\。
二 修饰符
g ————global 全文搜索并匹配,默认false,即搜索到第一个匹配就停止
i ————ignore case 忽略大小写搜索并匹配,默认false,即大小写敏感
m ————multi line 多行搜索并匹配,默认false,即所有字符串都是一行

三 元字符
JS正则表达式由2种字符类型组成:元字符和原义文本字符
原义文本字符: 表示字符原本含义的字母字符,如a、1等
元字符:是在正则表达式中表示特殊含义的非字母字符,如\t、*等
几个重要的元字符:* + ? $ ^ . | \ () [] {}
注:元字符的含义在不同环境中可能不同
四 类 [ ]
[ ]的作用—— 匹配”[ ]”中的任意一个字符
一般情况下,正则表达式中的一个字符对应字符串中的一个字符。
有些情况下,需要匹配某特征的一类字符而不是特指某个字符,这就用到类。
类是用于匹配某特征的一类字符的一种正则表达式,使用[ ]来创建
4.1 字符类
如表达式
[abc]把字符a或b或c归为一类,用于匹配符合这个类的字符串。
如下示例
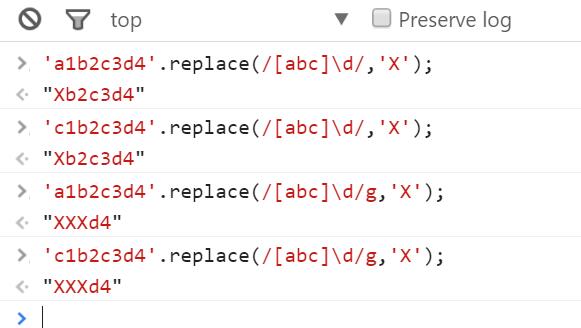
4.2 反向类
在[ ]中使用^创建反向类,表示不属于该类的内容
如表达式[^abc]表示不是字符a或b或c的内容
如下示例

4.3 范围类
在[ ]中使用
-连接2个字符,表示这两个字符范围内的任意一个字符。可以连写多个范围。
如表达式[a-z]表示匹配a到z中任意一个字符
如下示例

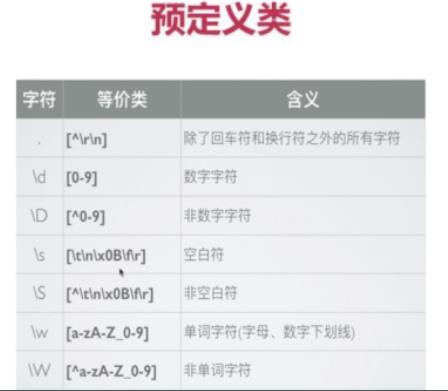
4.4 预定义类
正则表达式中提供了预定义类来匹配常见的字符类 , 如下图
五 边界
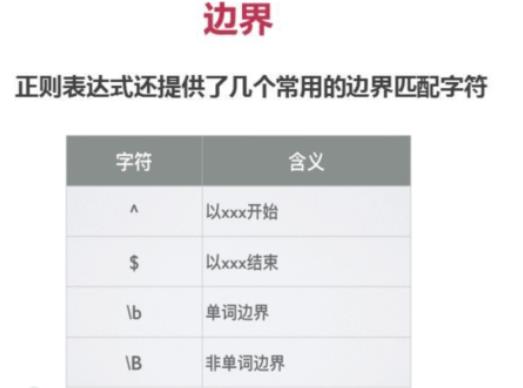
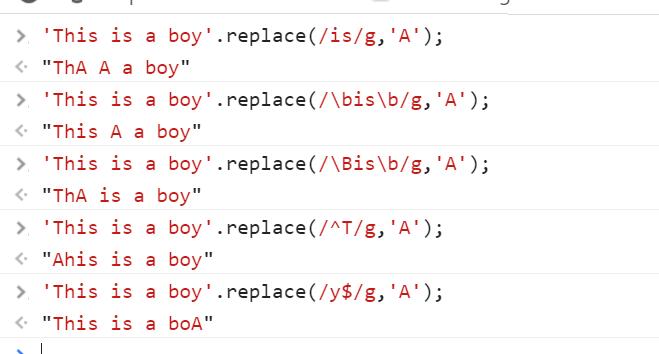
示例如下
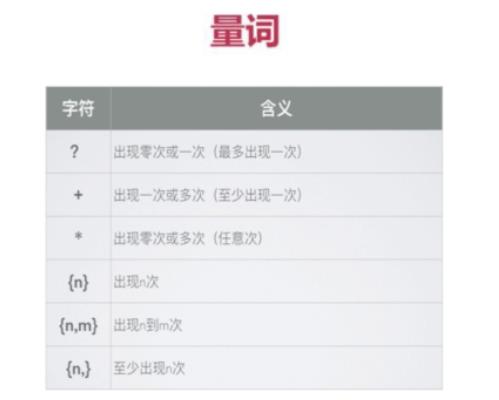
六 量词 {}
量词用于表示重复出现的次数
6.1 贪婪模式与非贪婪模式
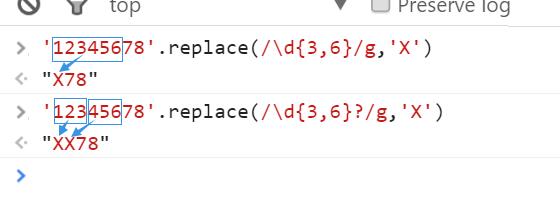
贪婪模式:尽可能多的匹配(默认)
非贪婪模式:尽可能少的匹配,一旦成功匹配不再继续尝试贪婪模式改为非贪婪模式的方法: 在量词后加上
?即可改为非贪婪模式。
示例如下
七 分组 ()
使用()可实现分组的功能
7.1 量词作用于分组
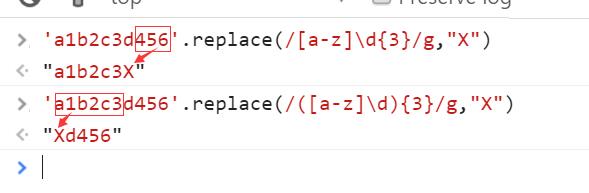
默认情况下,量词只作用于紧挨其前的那一个字符。使用()可实现使量词作用于分组。
如:
Byron{3} —————— 表示字符n重复3次
(Byron){3} —————— 表示Byron整体重复3次
示例如下:
7.2 或
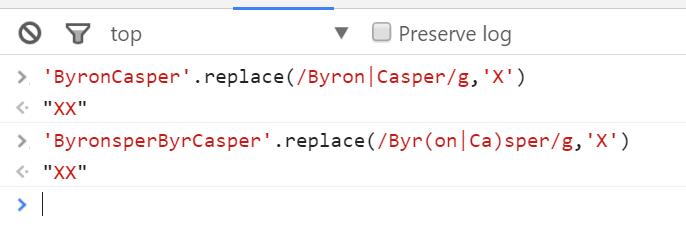
使用
|可达到或的效果
Byron|Casper ——————— 表示匹配Byron或Casper
Byr(on|Ca)sper ——————— 表示匹配Byronsper或ByrCasper
示例如下:
7.3 反向引用
使用
$1、$2、$3等来捕获各分组的内容
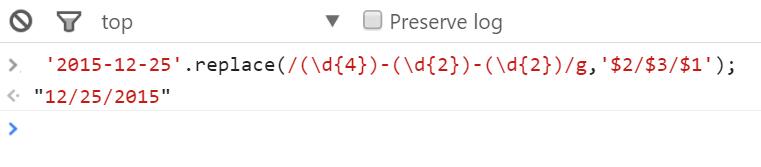
如下示例实现 2015-12-25 转变为 12/25/2015
7.4 忽略分组
不希望捕获某些分组,只需在分组内加上
?:即可
如下示例忽略了2015这个分组

八 前瞻
为是否匹配正则表达式增加一个附加判断条件
正则表达式是从文本头部向尾部开始解析,文本尾部方向称为“前”
前瞻:在正则表达式匹配到规则时,向前检查字符(即其后方、文本尾部方向的字符)是否符合断言。
后顾:方向相反JS正则表达式不支持后顾
符合和不符合特定断言称为肯定/正向匹配和否定/负向匹配
示例如下:
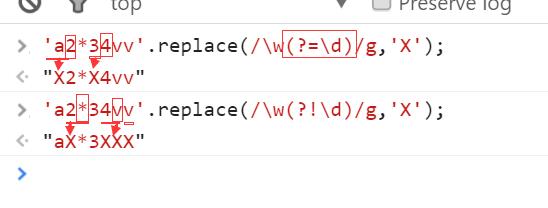
注:只替换\w,(?=\d)或(?!\d)不参与替换,只是一个判断条件
九 正则表达式对象属性
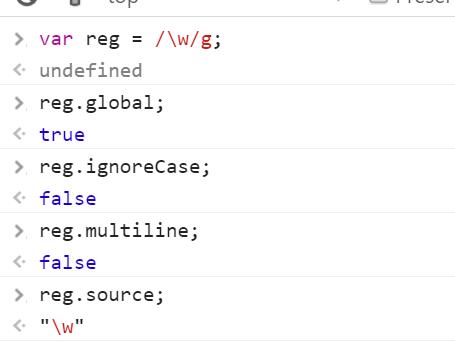
global——是否全文搜索,默认false,只读属性
ignoreCase——是否大小写敏感,默认false,只读属性
multiline ——是否多行搜索,默认false,只读属性
lastIndex ——当前表达式匹配内容的最后一个字符的下一个位置
source——正则表达式的文本字符串
示例如下:
十 正则表达式实例的方法
10.1 RegExp.prototype.test(str)
RegExp.prototype.test(str)
用于测试字符串参数str中是否存在匹配正则表达式模式的字符串。
如果存在返回true,否则返回false
示例如下:
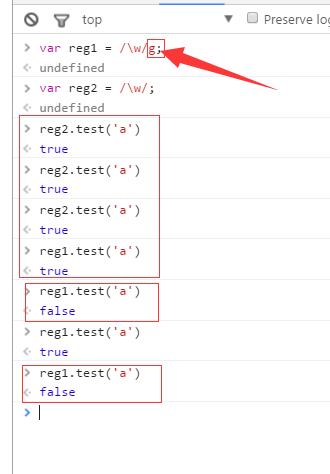
注:如果正则表达式实例中使用了g修饰符,那么其test()方法的多次执行结果不会一致,因受lastIndex影响。如上例中的
reg1.test('a')
如果正则表达式实例中未使用g修饰符,那个其test()方法的多次执行结果永远一致,因lastIndex永远为0。如上例中的reg2.test('a')
解决因受lastIndex影响而多次执行结果出现不一致问题的一种方式是:每次实例化一个新正则表达式,再使用test方法,即使用 如 (/\w/g).test('a')的形式。但不建议使用此方式,因内存开销较大。
10.2 RegExp.prototype.exec(str)
RegExp.prototype.exec(str)
使用正则表达式模式对字符串str执行搜索,并将更新RegExp对象的lastIndex属性以反映匹配结果。
如果没有匹配返回null,否则返回一个结果数组。
这个数组拥有2个属性:
index: 匹配文本的第一个字符的位置
input:存放被检索的字符串参数str
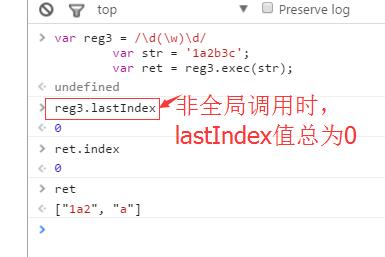
非全局调用exec()时——即不使用g修饰符,返回数组的组成:
- 第一个元素是与正则表达式相匹配的文本
- 第二个元素是与正则表达式对象实例的第一个子表达式(即第一个分组表达式)相匹配的文本(如果有的话)
- 第三个元素是与正则表达式对象实例的第二个子表达式(即第二个分组表达式)相匹配的文本(如果有的话)
- 以此类推
示例如下
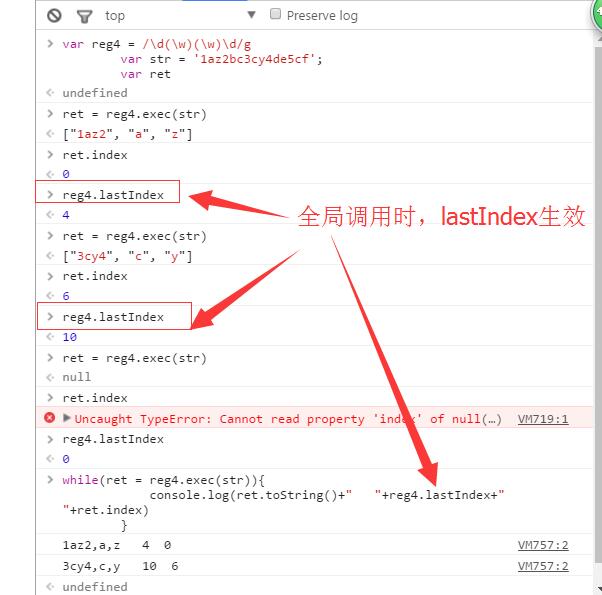
全局调用exec()时——即使用g修饰符,每执行一次返回匹配规则的一个数组,并且每个数组的组成同上,示例如下:
十一 字符串对象方法
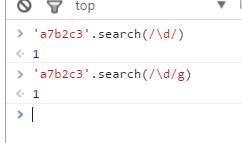
String.prototype.search(reg|str)
search()用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串。返回第一个匹配结果的index,未匹配则返回-1。
注:search()不执行全局匹配,它将忽略g修饰符。并且总从字符串的开始进行检索。
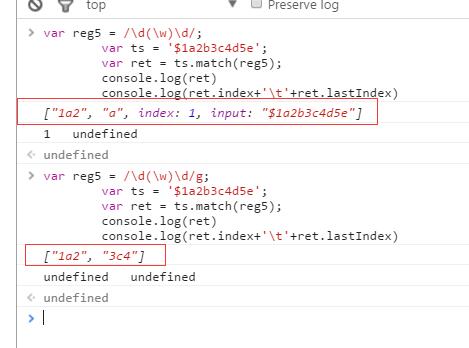
String.prototype.match(reg|str)
match()方法用于检索字符串,以找到一个或多个与正则表达式相匹配的子字符串。
注:参数reg是否有g修饰符对结果影响很大。
非全局调用match():——即参数reg没有g修饰符
- match()方法只在字符串中执行一次匹配;
- 如果找到匹配文本,将返回一个数组,其他存放于找到的匹配文本有关的信息,否则返回null;
- 该数组的组成与非全局调用exec()时返回的数组结构完全相同。
全局调用match():——即参数reg有g修饰符
- match()方法将执行全局检索,找到字符串中的所有匹配的子字符串
- 如果找到一个或多个匹配子串,则返回一个数组;否则返回null
- 数组中存放的是所有匹配的子串,而且没有index和input属性
示例如下
String.prototype.spilt(reg|str)
用于以正则表达式的模式来分隔字符串
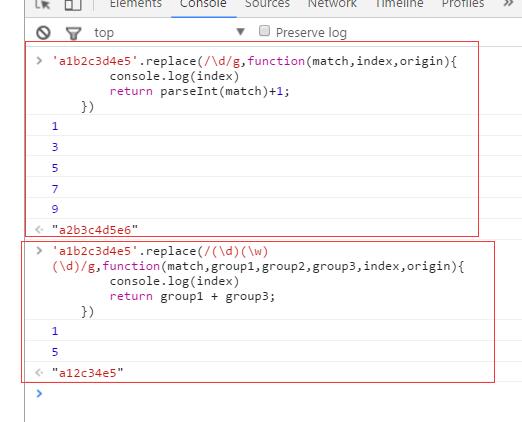
String.prototype.replace()
用于替换字符串,有2中形式:
String.prototype.replace(reg|str,replaceStr)
String.prototype.replace(reg,function)
其中function回调函数参数的含义

示例如下
总结
1、在正则表达式中, \ 与 / 符号的使用场合:
/:仅用于字面量实例化正则表达式,括住正则表达式文本字符串这一种场合。
\:其他情况均使用\。
2、阅读正则表达式的方法——以( )分隔、{}表量词、[ ]表或者
3、量词有? + * {}四类
4、或 |运算符的优先级最低,用于匹配其前或其后的正则表达式。
5、正则表达式实例中的lastIndex属性只有在该实例的global属性为true时才有效。
6、上述的字符串对象方法,在其内部实现上都是将参数转化为正则表达式,如'123'.replace(1,'X')在内部实现上会首先转换为'123'.replace(/1/,'X'),然后进行后续操作。















 242
242











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









