







一、CSA-GAN:基于条件语义增强的文本到图像生成
文章来源:软件学报 2023年11月
引用格式:余凯;宾燚;郑自强;杨阳.基于条件语义增强的文本到图像生成[J/OL].软件学报,1-15[2023-11-26]https://doi.org/10.13328/j.cnki.jos.007024.
1.1、主要创新
文本生成图像在视觉上取得了优异效果,但是仍然存在细节表达不足等问题。基于以上问题,文章提出基于条件语义增强的生成方法CSA-GAN,创新点如下:
- 在文本编码后进行条件语义增强,以在给定少量的文本图像数据对的情况下能提供更多的增强数据。提高小扰动在语义空间的鲁棒性以达到更准确得图像生成效果并为后续的细节场景提供潜在信息
- 通过对中间层特征进行上采样生成图像掩码,并与增强后的条件语义进行空间-语义融合,以更好地适配生成符合文本描述的内容, 从而生成具有更丰富、准确细节的图像。
- 针对细节表达问题,使用残差生成器 G0 对其中细节进行补充。
1.2、主要框架
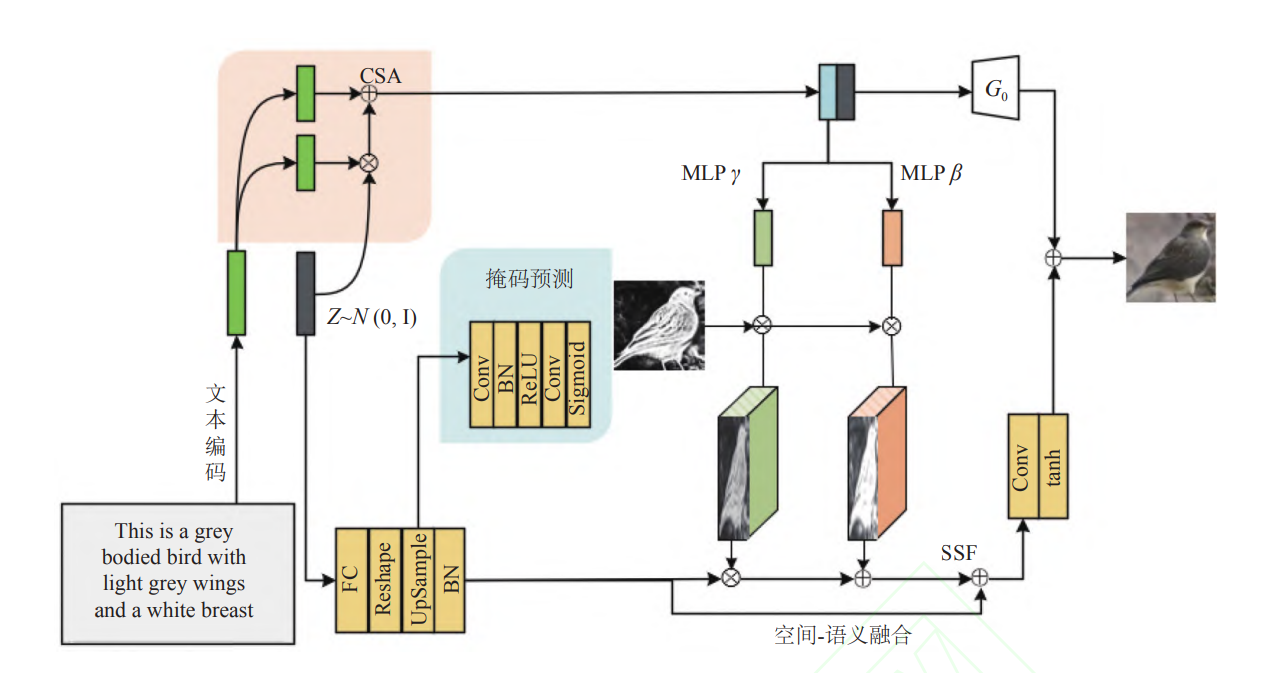
其中条件语义增强在传统的批量归一化的基础上引入了一个新的变量 c c c作为条件约束,具体来讲,文章将文本嵌入得到相应的特征进行随机采样得到 c c c, 具体体现为从一个独立的高斯分布 N ( μ ( ϕ t ) , ∑ ( ϕ t ) ) \mathcal{N}\left(\mu\left(\phi_{t}\right), \sum\left(\phi_{t}\right)\right) N(μ(ϕt),∑(ϕt))进行随机采样:
上述的条件语义增强在给定少量的文本图像数据对的情况下能提供更多的增强数据, 从而提高生成器对于语义空间流形上小扰动的鲁棒性, 提高了模型的性能。
为了进一步增强语义空间流形的连续性, 同时为了避免模型过拟合的情况发生, 在目标函数中增加了一项在模型训练时针对生成器的正则化:
D
K
L
(
N
(
μ
(
ϕ
t
)
,
∑
(
ϕ
t
)
)
∥
N
(
0
,
I
)
)
D_{K L}\left(\mathcal{N}\left(\mu\left(\phi_{t}\right), \sum\left(\phi_{t}\right)\right) \| \mathcal{N}(0, I)\right)
DKL(N(μ(ϕt),∑(ϕt))∥N(0,I))
其中 N ( 0 , I ) \mathcal{N}(0, I) N(0,I)为采样分布, N ( μ ( ϕ t ) , ∑ ( ϕ t ) ) \mathcal{N}\left(\mu\left(\phi_{t}\right), \sum\left(\phi_{t}\right)\right) N(μ(ϕt),∑(ϕt))为语义空间分布,条件语义增强引入细微语义扰动, 从而学习更加稳健鲁棒, 语义更加丰富, 能够生成不同外观和姿态的图像, 而不是仅重复生成同一种图像。
1.3、 实验
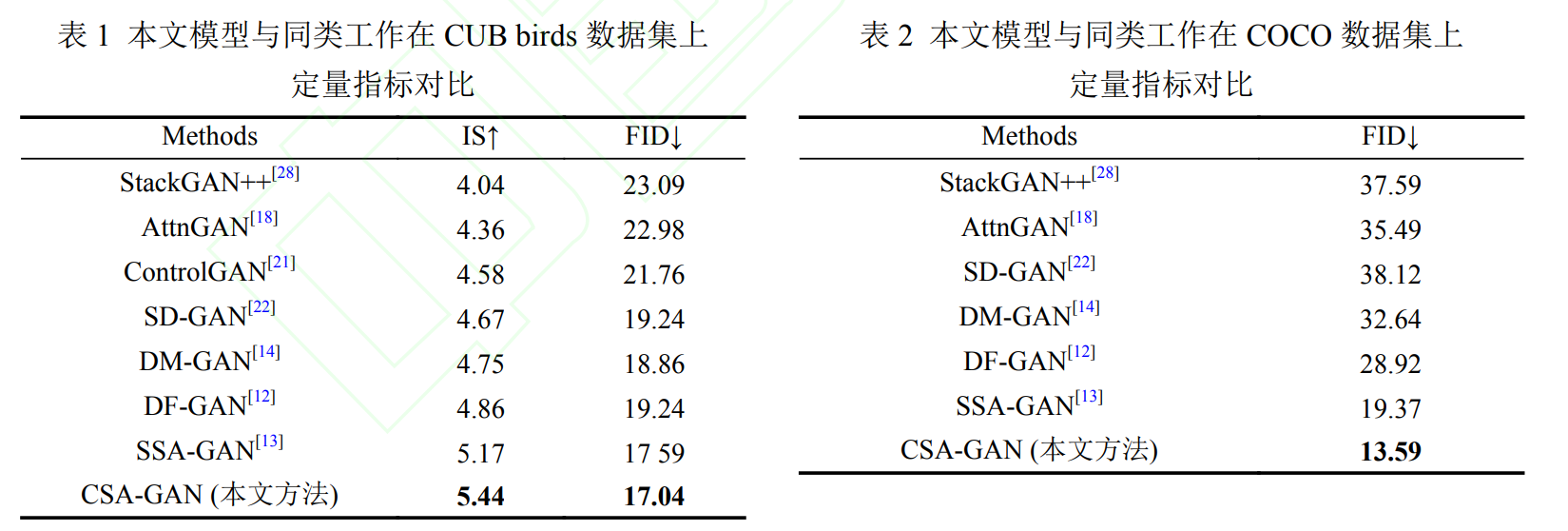
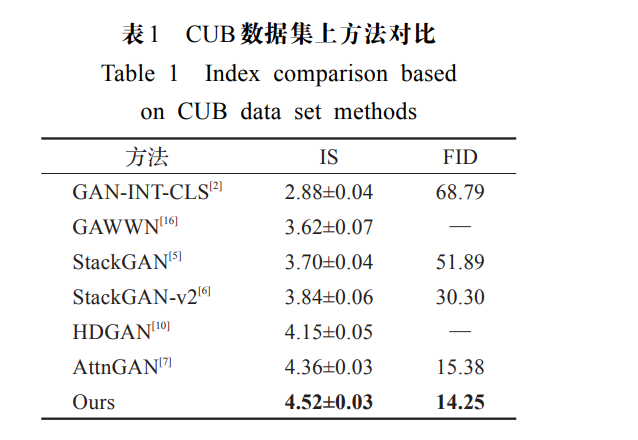
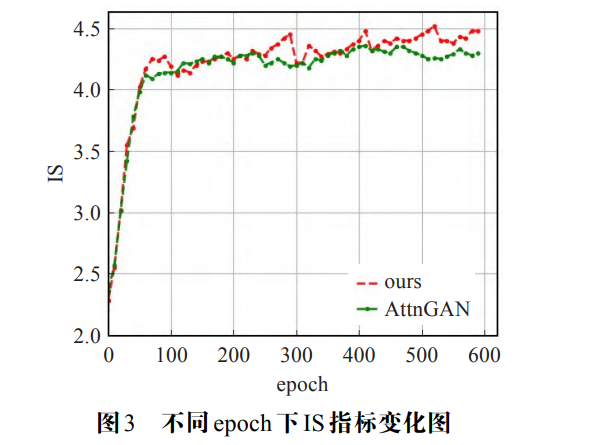
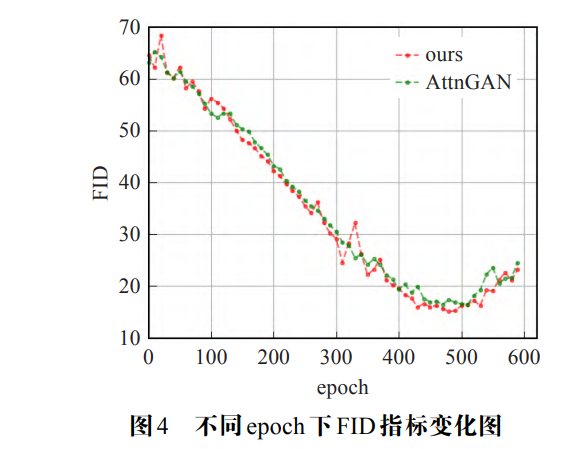
模型在 IS 指标上取得了 5.44, 在 FID 指标上取得了 17.04. 即本文提出的模型比基线模型生成质量更佳, 多样性更优秀。


相对 DF-GAN 和 SSA-GAN, 本模型产生的可视化图结果的细节表现得更好. 主要体现在主体和背景交融处显得更加自然和谐。
二、SA-AttnGAN:基于自注意力机制的文本生成单目标图像方法
文章来源:计算机工程与应用 2022年2月
引用格式:鞠思博,徐晶,李岩芳.基于自注意力机制的文本生成单目标图像方法[J].计算机工程与应用,2022,58(03):249-258.
2.1、主要创新
合成单目标图像在真实性上仍存在一定缺陷,如针对鸟类图形合成时,会出现“多头”“多嘴”等异常情况,基于上述问题本文提出SA-AttnGAN,创新点如下:
- 在初始阶段增加自注意力模块,改善原模型生成不符合常态的鸟类图片;
- 还制作了文本生成图像服装数据集,为其他研究者扩展了t2i技术的应用领域,奠定了数据基础。
2.2、主要框架
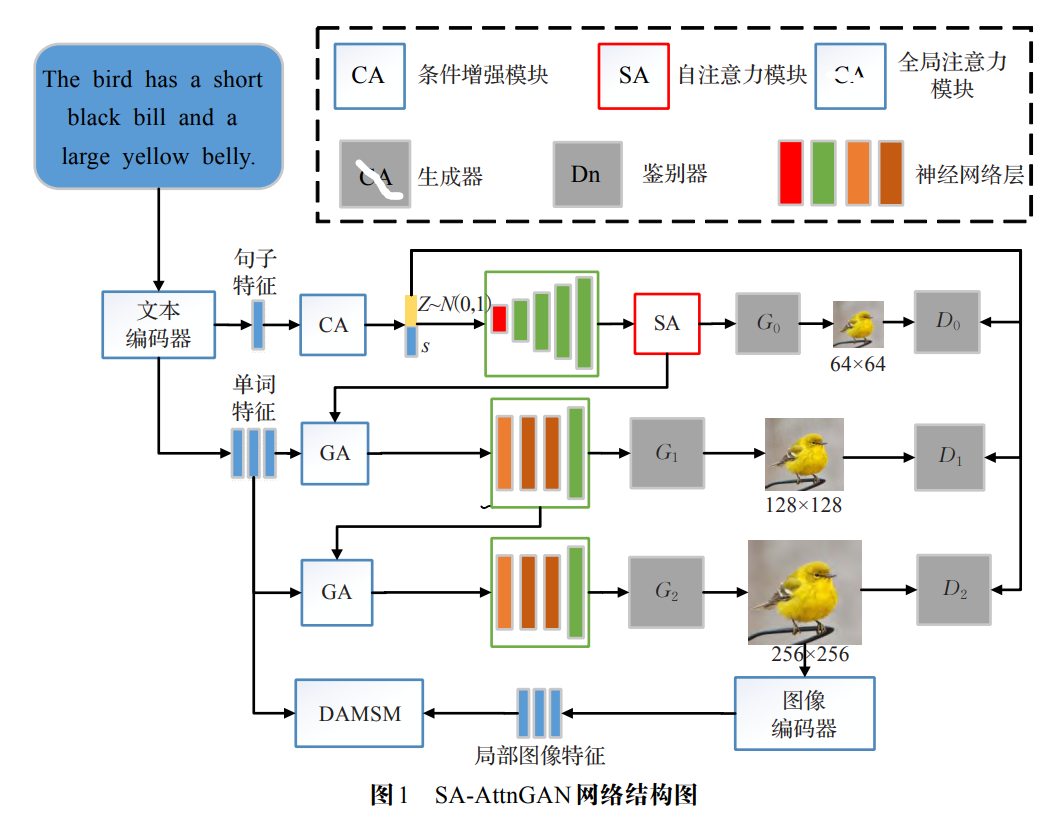
结构大致与AttnGAN相似,文本被编码成句子特征和单词特征分别代入三个阶段生成器和鉴别器当中生成图像,原理类似的地方不再赘述。创新的地方就是其在初始阶段加入了红框所示的自注意力模块。
2.2.1、自注意力模块
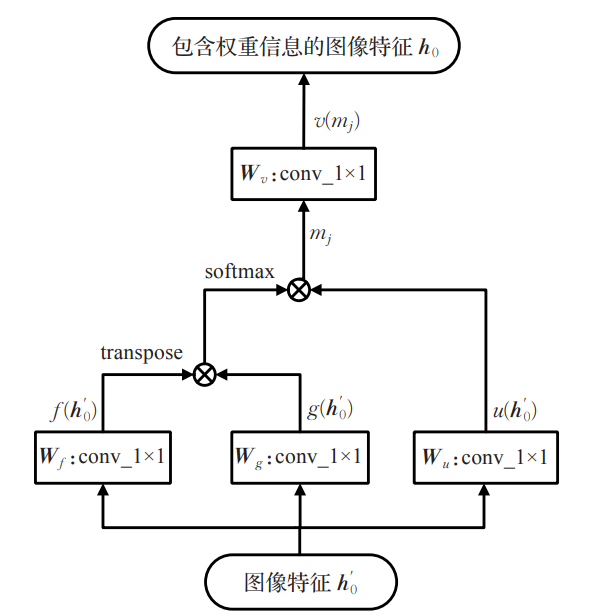
引入自注意力机制,通过对图像特征映射间的自主学习,分配不同的权重信息,使最终得到的特征图包含更多的空间与位置信息,进一步提升高分辨率图像合成的效果,降低模型生成崩溃的可能。如上图所示,其首先使用三个1×1卷积核,将图像特征转化到特征空间f,g,u,然后将三者通过自注意力机制进行相乘计算合成图像的第j个区域时的第i个位置的权重信息。
经过自注意力学习到特征图中空间与位置的关系,为图像中重要细节信息赋予更大权重,有利于初始阶段生成更有意义的图像。
2.2.2、t2i技术服装领域扩展应用
本文方法在服装数据集上也进行了测试,服装数据集中的图片是由 cp-vton提供[34],包含 14 000多张照片,其中涵盖 T恤、连衣裙、背心等 6种女士服装,在此基础上为每张图片添加了一句中文文本描述,共计14000余条文本。

2.3、实验

最后
声明:本博客所涉及的论文摘读、引用、速览和精读等系列内容仅用于学术研究、评论和个人笔记等非商业性目的,论文的引用内容均来自于出版机构或者网络,并尽力标明了出处和来源。 如果您觉得本博客中有任何侵犯您合法权益的内容,请私信联系我,一旦确认存在侵权行为,我将立即删除相关内容。
💖 个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
📝 个人主页:中杯可乐多加冰
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝
另外,我们已经建立了微信T2I学习交流群,如果你也是T2I方面的爱好者或研究者可以私信我加入。

















 1828
1828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











