







VLMGAN,提出一种新的文本到图像合成的视觉语言匹配策略,模型引入了双视觉语言匹配机制,以增强图像质量和语义一致性,另外其提出了一种新的度量指标:VLMS(视觉语言匹配分数)来评估文本到图像合成的性能。文章于22年8月发表于arxiv。
论文地址:https://arxiv.org/abs/2208.09596
一、原文摘要
文本到图像合成是一项有吸引力但具有挑战性的任务,其目的是从特定的文本描述生成照片真实和语义一致的图像。与相应的图像和文本描述相比,由现成模型合成的图像通常包含有限的成分,这降低了图像质量和文本视觉一致性。为了解决这个问题,我们提出了一种新的文本到图像合成的视觉语言匹配策略,名为VLMGAN*,该策略引入了双视觉语言匹配机制,以增强图像质量和语义一致性。双视觉语言匹配机制考虑生成的图像和对应的文本描述之间的文本视觉匹配,以及合成图像和真实图像之间的视觉一致性约束。给定特定的文本描述,VLMGAN*首先将其编码为文本特征,然后将其馈送到基于双视觉语言匹配的生成模型,以合成照片逼真和文本语义一致的图像。此外,流行的文本到图像合成的评估指标借鉴了简单的图像生成,主要评估合成图像的真实性和多样性。因此,我们引入了一个名为视觉语言匹配分数(VLMS)的度量来评估文本到图像合成的性能,该度量可以同时考虑图像质量和合成图像与描述之间的语义一致性。所提出的双层次视觉语言匹配策略可以应用于其他文本到图像的合成方法。我们在标记为VLMGAN+AttnGAN和VLMGAN+DFGAN的两个流行基线上实现了该策略。在两个广泛使用的数据集上的实验结果表明,该模型比其他最先进的方法实现了显著的改进。
二、为什么提出VLMGAN ?
文本到图像合成旨在基于特定的文本描述生成真实感和文本一致的图像。
文本到图像的合成与简单的图像合成有着显著的不同,它包含两个挑战,即视觉真实性和文本-视觉语义一致性。目前视觉真实性的方向已经得到了充分研究,一些方法可以生成高度逼真的图像,但是视觉文本语义一致性依然是文本图像合成的关键挑战。
尽管许多方法能够合成相对细粒度和真实的图像,但它们很少关注生成的图像和相应文本之间的多级语义一致性。他们可以合成相对真实的图像,但可能无法生成与文本语义一致的图像特别是对于CUB数据集等简单数据集,例如,对于描述:small bird, with white breast,red head and black wings and back,其他模型(AttnGAN、DMGAN)可以生成逼真的图像,但是细节与文本描述不一致。

在保证图像的逼真性条件下,文本到图像合成应同时关注:
- 文本视觉匹配:文本视觉匹配可以保持图像内容与文本描述一致。
- 视觉视觉匹配:视觉视觉匹配考虑图像质量和图像内容的语义。
此外,如何公平地评估文本到图像合成的性能是一个需要处理的重要问题。文本生成图像是一项配对翻译任务,它应该考虑合成图像的质量以及与文本描述的语义一致性。然而,FID和IS都只考虑合成图像,而忽略文本描述。因此,文本到图像的合成需要一种新的评估度量,该度量考虑了描述和合成图像之间的一致性,以弥补FID和IS的不足
基于以上启发,作者首先提出了一种新的视觉语言匹配模型(VLM),该模型可以基于度量学习有效地探索图像和文本之间的相似性。然后,作者将所提出的VLM视为一个额外的约束块,并将其插入基于多级GAN的文本到图像合成框架中,并考虑了合成图像与真实图像之间的多级匹配。
根据这一基本思想,作者还提出了一种新的度量方法VLMS,用于从另一个角度评估文本到图像的合成性能,称为视觉语言匹配分数。
三、图像-文本匹配
跨模态理解是一项有吸引力但具有挑战性的任务,包括跨模态检索、图像字幕生成和语义基础,图像-文本匹配模型是跨模态理解其中的一项子任务,其旨在使用对比学习将视觉图像和文本描述投影到语义共享空间,具体而言,视觉和文本特征被分别编码到同一子空间中,在该子空间中计算相似度值,方法可分为三种:全局匹配方法、区域匹配方法和多级匹配方法。
- 全局匹配方法:全局匹配就是把图像和文本的特征同时嵌入到一个潜在空间当中计算匹配度,图像和文本使用CNN或LSTM以全局方式编码。然后将视觉特征和文本特征嵌入子空间,在子空间中可以计算它们的全局相似性并通过三元组排序损失进行优化(比如CLIP)然而,这些方法无法匹配原始图像中的具体对象和句子中的单词,这可以通过区域匹配方法来解决。
- 区域匹配方法:区域匹配计算图像子区域和文本单词的关系,SCAN使用预训练的Faster RCNN来检测具体对象,并设计堆叠的交叉注意力机制来对齐对象和单词,VSRN采用图卷积来学习对应于文本关系的区域关系。
- 多级匹配方法:多级匹配方法同时学习图像子区域-单词对齐和全局语义对齐。GSLS设计了一种多路径结构,以获得全局和局部相似性。CRAN设计了一种多路径结构,用于同时学习全局、局部和关系对齐。Wen等人利用GAT学习图像对象和背景与句子中短语对齐的双重关系。
为了更全面地计算生成的图像与原始句子之间的相似度,作者也设计了多级匹配模型VLM。
四、视觉语言匹配VLM模型
4.1、VLM模型
视觉语言匹配(VLM)模型学习文本和图像模态的多级相似性,包括局部级匹配、全局级匹配和通用级匹配。
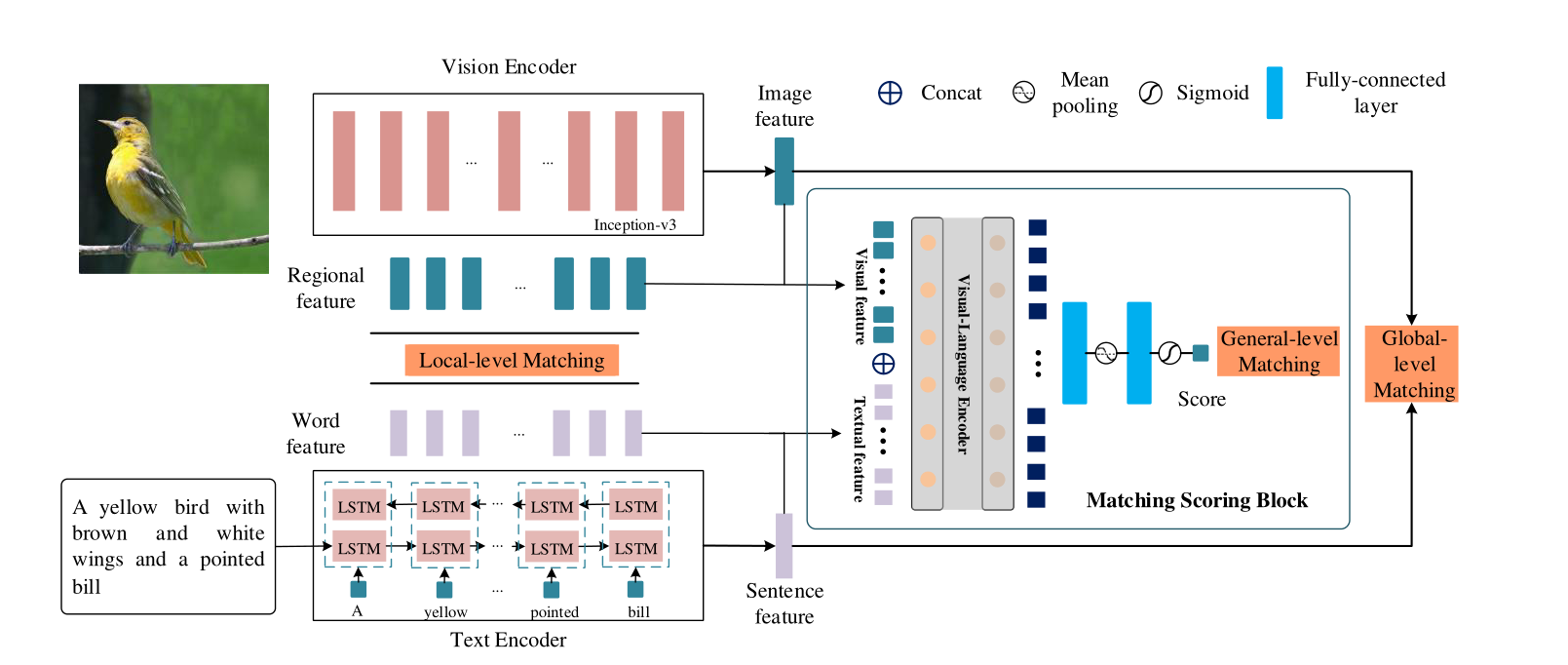
VLM模型包含三个子模型:视觉编码器、文本编码器和匹配评分块(MSB)。
视觉编码器和文本编码器旨在将图像和文本嵌入到语义对齐的向量中,连接视觉和语言领域。而所提出的匹配评分块MSB通过Transformer编码器为图像和文本生成匹配分数。
- 文本编码器:主网络使用的是LSTM。对于句子的第i个单词,嵌入层将其嵌入到语义向量wi中,然后输入LSTM。具体而言,单词特征由隐藏状态表示,而句子特征由最后一个隐藏状态表示: φ , φ ˉ = F Text-Encoder ( w 1 , w 2 , … , w n ) \varphi, \bar{\varphi}=F_{\text {Text-Encoder }}\left(w_{1}, w_{2}, \ldots, w_{n}\right) φ,φˉ=FText-Encoder (w1,w2,…,wn), φ表示的是单词特征, φ − φ^- φ−表示的是句子特征。
- 视觉编码器:主网络使用的是Inception-v3。视觉特征由卷积神经网络提取,命名为Inception-v3。根据之前的工作,CNN的中间特征可以呈现图像的局部区域特征,而最后一层的特征是图像的全局特征,Inception-v3模型在ImageNet上进行了预训练。局部区域特征f(768×17×17)由混合6e层的输出表示,全局特征 f − f^- f−(2048×1)由混合7b层表示。 ϕ = F 1 × 1 conv ( f ) , ϕ ˉ = W f ˉ \phi=F_{1 \times 1 \operatorname{conv}}(f), \bar{\phi}=W \bar{f} ϕ=F1×1conv(f),ϕˉ=Wfˉ,ϕ表示的是局部区域特征, ϕ − ϕ^- ϕ−表示的是全局特征。
- 匹配评分块VLMS:视觉语言匹配评分块旨在产生通用匹配评分,以评估图像和文本之间的匹配程度。作者使用采用Transformer机制来学习图像和文本之间的匹配分数。计算一般级别匹配时考虑图像的全局特征和局部特征以及文本的句子特征和单词特征。具体而言,首先联合特征为
ψ
=
F
c
a
t
(
φ
,
φ
ˉ
,
ϕ
,
ϕ
ˉ
)
\psi=F_{c a t}(\varphi, \bar{\varphi}, \phi, \bar{\phi})
ψ=Fcat(φ,φˉ,ϕ,ϕˉ),然后输入到基于Transformer的视觉语言编码器中
ψ
^
=
F
Transformer
(
ψ
)
\hat{\psi}=F_{\text {Transformer }}(\psi)
ψ^=FTransformer (ψ),在获得视觉文本潜在特征之后,选择完全连接的层将特征投影到隐藏空间中
ψ
^
=
W
0
ψ
^
+
b
0
\hat{\psi}=W_{0} \hat{\psi}+b_{0}
ψ^=W0ψ^+b0,最后输入池化层和
sigmoid层,最终生成Score分数。匹配评分块主要用于计算General-level matching(可以见后文)
而可以看到,视觉语言匹配VLM模型同时考虑了文本-视觉匹配和视觉-视觉匹配,其中有三处匹配度的计算,第一处是局部级的匹配Local-level matching,第二处是全局级别的匹配Global-level matching,第三处是通用级的匹配General-level matching:
4.2、匹配度的计算
4.2.1、Local-level matching
Local-level matching表示局部匹配度,局部匹配考虑了单词特征和图像局部区域特征之间的语义一致性。
首先计算具有289个局部区域特征的特定图像和具有T0个单词特征的文本描述的相似度矩阵: s ( ϕ i , φ j ) = ϕ i T φ j ∥ ϕ i ∥ ∥ φ j ∥ , i ∈ [ 1 , 2 , … , 289 ] , j ∈ [ 1 , 2 , … , T 0 ] s\left(\phi_{i}, \varphi_{j}\right)=\frac{\phi_{i}^{\mathrm{T}} \varphi_{j}}{\left\|\phi_{i}\right\|\left\|\varphi_{j}\right\|}, i \in[1,2, \ldots, 289], j \in\left[1,2, \ldots, T_{0}\right] s(ϕi,φj)=∥ϕi∥∥φj∥ϕiTφj,i∈[1,2,…,289],j∈[1,2,…,T0],我们采用S作为单词特征和图像局部特征之间的相似度矩阵。 c i = ∑ j = 0 288 α i j ϕ j c_{i}=\sum_{j=0}^{288} \alpha_{i j} \phi_{j} ci=∑j=0288αijϕj,其中 α i j = exp ( γ 1 s i , j ) ∑ k = 0 288 exp ( γ 1 s i , k ) \alpha_{i j}=\frac{\exp \left(\gamma_{1} s_{i, j}\right)}{\sum_{k=0}^{288} \exp \left(\gamma_{1} s_{i, k}\right)} αij=∑k=0288exp(γ1si,k)exp(γ1si,j)。
根据最小分类误差公式,通过LogSumExp池计算图像和文本描述之间的局部水平匹配分数,如下所示: S local ( I , T ) = log ( ∑ i = 1 T − 1 exp ( γ 2 S ( c i , φ i ) ) ) 1 γ 2 S_{\text {local }}(I, T)=\log \left(\sum_{i=1}^{T-1} \exp \left(\gamma_{2} S\left(c_{i}, \varphi_{i}\right)\right)\right)^{\frac{1}{\gamma_{2}}} Slocal (I,T)=log(∑i=1T−1exp(γ2S(ci,φi)))γ21,其中 S ( c i , φ i ) = c i T φ i ∥ c i ∥ ∥ φ i ∥ S\left(c_{i}, \varphi_{i}\right)=\frac{c_{i}^{\mathrm{T}} \varphi_{i}}{\left\|c_{i}\right\|\left\|\varphi_{i}\right\|} S(ci,φi)=∥ci∥∥φi∥ciTφi
4.2.2、Global-level matching
Global-level matching表示全局级匹配度,全局级匹配度考虑视觉全局特征和全局文本特征。类似地,对于全局视觉特征φ和句子特征φ,匹配分数直接通过余弦相似度计算: S global ( I , T ) = φ ˉ T ϕ ˉ ∥ φ ˉ ∥ ∥ ϕ ˉ ∥ S_{\text {global }}(I, T)=\frac{\bar{\varphi}^{\mathrm{T}} \bar{\phi}}{\|\bar{\varphi}\|\|\bar{\phi}\|} Sglobal (I,T)=∥φˉ∥∥ϕˉ∥φˉTϕˉ
4.2.3、General-level matching
General-level matching表示常规级匹配度,常规级匹配度由预先训练的视觉语言匹配评分块产生。计算如下: S general ( I , T ) = F M S B ( ϕ , ϕ ˉ , φ , φ ˉ ) S_{\text {general }}(I, T)=F_{\mathrm{MSB}}(\phi, \bar{\phi}, \varphi, \bar{\varphi}) Sgeneral (I,T)=FMSB(ϕ,ϕˉ,φ,φˉ)(见四)。
五、VLMGAN
5.1、框架结构
作者以AttnGAN为基准模型,设计了VLMGAN,是一个多阶段模型,框架如下图所示,也可以大致分为文本编码器、生成器、鉴别器三大部分:
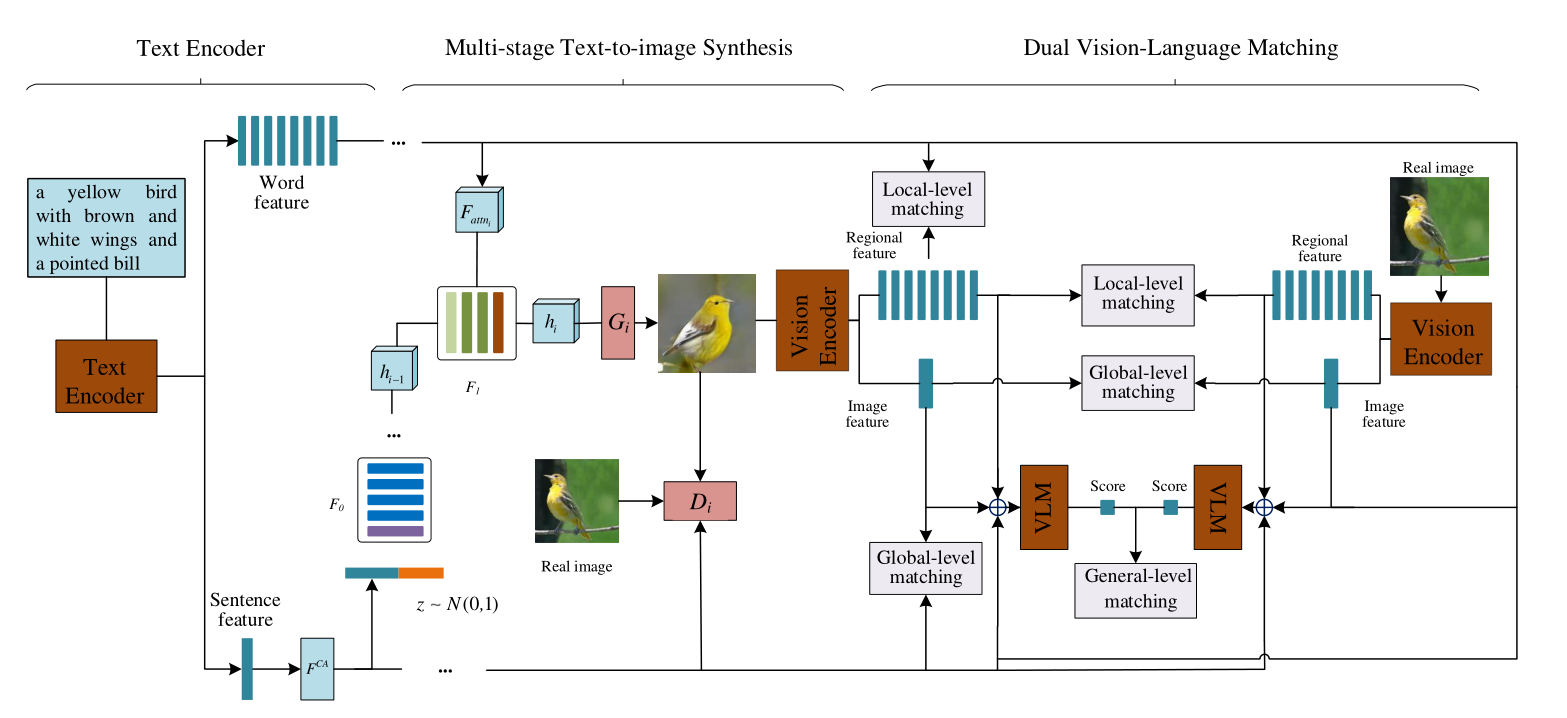
文本经过文本编码器进行编码,形成句子特征和单词特征,句子特征经过CA变换输入到生成器部分当中,单词特征使用到单词级别注意力机制将单词特征与视觉特征做融合(这一步就是AttnGAN当中的方法),然后经过多个生成器(一般为3个)堆叠形成图像。
图像之后通过视觉编码器编码形成图像特征和区域特征,之后分别计算 Global-level matching和 Local-level matching,真实图像也同时计算Global-level matching和 Local-level matching,然后两者比较General-level matching。
5.2、损失函数
总的损失函数为: L G = ∑ i = 0 2 L G i + λ 1 L V V M + λ 2 L V L M \mathcal{L}_{G}=\sum_{i=0}^{2} \mathcal{L}_{G_{i}}+\lambda_{1} \mathcal{L}_{V V M}+\lambda_{2} \mathcal{L}_{V L M} LG=∑i=02LGi+λ1LVVM+λ2LVLM,其中 L G L_G LG表示生成对抗损失, L V V M L_{VVM} LVVM表示文本-视觉匹配损失, L V L M L_{VLM} LVLM表示的是视觉-视觉损失。
5.2.1、对抗损失
多级阶段的 L G L_G LG损失有三层,因为有三层生成器,第i层的生成器的损失为: L G i = − 1 2 E x ^ i ∼ P G i [ log ( D i ( x ^ i ) ) ] − 1 2 E x ^ i ∼ P G i [ log ( D i ( x ^ i , φ ˉ ) ) ] \mathcal{L}_{G_{i}}=-\frac{1}{2} E_{\hat{x}_{i} \sim P_{G_{i}}}\left[\log \left(D_{i}\left(\hat{x}_{i}\right)\right)\right]-\frac{1}{2} E_{\hat{x}_{i} \sim P_{G_{i}}}\left[\log \left(D_{i}\left(\hat{x}_{i}, \bar{\varphi}\right)\right)\right] LGi=−21Ex^i∼PGi[log(Di(x^i))]−21Ex^i∼PGi[log(Di(x^i,φˉ))]。目标函数中,前半部分是无条件损失,它决定了合成图像是真实的还是假的。后半部分是条件损失,它确定图像内容是否与文本描述匹配。生成损失函数迫使模型合成照片逼真和文本语义一致的图像。
5.2.2、文本-视觉匹配损失VLM
L V L M = L l o c a l + L g l o b a l + L g e n e r a l \mathcal{L}_{VLM}= \mathcal{L}_{local} +\mathcal{L}_{global} +\mathcal{L}_{general} LVLM=Llocal+Lglobal+Lgeneral,其中 L l o c a l \mathcal{L}_{local} Llocal表示局部级匹配损失, L g l o b a l \mathcal{L}_{global} Lglobal表示全局级匹配损失, L g e n e r a l \mathcal{L}_{general} Lgeneral表示常规级损失。在四种已经详细介绍,不再赘述。其中局部级匹配损失类似5.2.1方法计算,全局级匹配损失类似5.2.2方法计算,常规级损失类似5.2.3方法计算。
具体计算方法比较复杂,请看原文。
5.2.3、视觉-视觉匹配损失VVM
视觉-视觉全局级匹配损失旨在最大化真实图像和合成假图像之间的全局匹配分数。损失函数为: L V V M = L V G + L V L + L V G E N . \mathcal{L}_{V V M}=\mathcal{L}_{V G}+\mathcal{L}_{V L}+\mathcal{L}_{V G E N} . LVVM=LVG+LVL+LVGEN.,相同原理, L V G \mathcal{L}_{V G} LVG表示全局级视觉匹配损失, L V L \mathcal{L}_{V L} LVL表示局部级视觉匹配损失, L V G E N \mathcal{L}_{V G E N} LVGEN表示常规级视觉匹配损失。
具体计算方法比较复杂,请看原文。
六、实验
6.1、实验设置
数据集:CUB、MSCOCO;
评估指标:FID、IS、R-precision和本文提出的VLM Score;
实验设置:8个NVIDIA GeForce GTX2080ti GPU,对于视觉编码器、文本编码器和视觉语言匹配评分模型,batchsize设置为64。对于VLMGAN+AttnGAN模型,batchsize设置为24,生成器的学习率为0.0001,鉴别器为0.0004。生成网络和鉴别网络的参数交替优化。
伪代码:

6.2、定量评估
所提出的双视觉语言匹配模块VLM可以应用于其他各种文本到图像合成架构,作者在实验中首先是以AttnGAN作为基准模型进行了改进,后续也将其扩展用到了DF-GAN框架上,实验效果如下:


6.3、实验效果


七、总结与创新
文章设计了一个双重语义一致的文本到图像合成框架,该框架可以增强视觉内容和文本描述之间的文本-视觉一致性,以及合成图像和真实图像之间的视觉-视觉一致性。文章设计的这个模块即插即用,可以应用于任何其他文本到图像任务。
另外,作者提出了一种新的多层次视觉语言匹配模型来学习图像和文本之间的相似性,该模型可以考虑全局级匹配、细粒度局部级匹配和通用级匹配,引出一种新的评估度量(视觉语言匹配分数,VLMS)用于来评估文本生图像的性能,VLMS可以同时考虑生成图像的视觉真实性和生成图像与文本描述之间的语义一致性。
本文通过增强合成图像与真实数据之间的语义和视觉匹配,解决了文本到图像的合成问题,提出的双层次视觉语言匹配同时考虑了文本-视觉匹配和视觉-视觉匹配,其同时考虑了图像质量和图像语义来测量图像和文本之间的匹配分数,更符合人类感知。
💡 最后
我们已经建立了🏤T2I研学社群,如果你对🎓文本生成图像很感兴趣,可以私信我加入社群。
📝 加入社群 抱团学习:中杯可乐多加冰-采苓AI研习社
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝

















 4478
4478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











