







现在是在学习吴恩达的深度学习课程,这个就当做每周的总结吧。
1 简介
据线性可分可以使用线性分类器,如果数据线性不可分,可以使用非线性分类器,这里似乎没有逻辑回归什么事情。但是如果我们想知道对于一个二元分类问题,对于具体的一个样例,我们不仅想知道该类属于某一类,而且还想知道该类属于某一类的概率多大,有什么办法呢?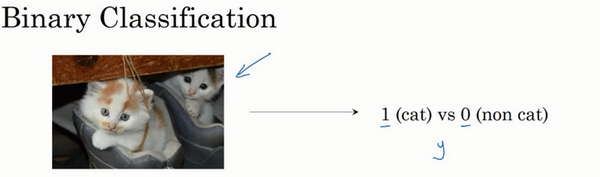
逻辑回归是一个用于二元分类(binary classification)的算法,逻辑回归假设数据服从伯努利分布,通过极大化似然函数的方法,运用梯度下降来求解参数,达到将数据二元分类的目的。二元分类可以用于多个方面: 垃圾邮件分类、判断肿瘤是否良性、预测某人信用是否良好等等,这里有一个二元分类问题的例子,假如你有一张图片作为输入,比如这有只猫,如果识别这张图片为猫,则输出标签1作为结果;如果识别出不是猫,那么输出标签0作为结果。
2 技术原理
对于一张图片的分类,首先我们看一张图片在计算机中是如何表示的,为了保存一张图片,需要保存三个矩阵,它们分别对应图片中的红、绿、蓝三种颜色通道,如果你的图片大小为64x64像素,那么你就有三个规模为64x64的矩阵,分别对应图片中红、绿、蓝三种像素的强度值,如下图为5x4的像素矩阵:
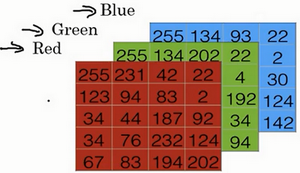
为了把这些像素值转换为特征向量 x利与计算,我们需要像下面这样定义一个特征向量 x 来表示这张图片,我们把所有的像素都取出来,直到得到一个特征向量,把图片中所有的红、绿、蓝像素值都列出来。如果图片的大小为64x64像素,那么向量 x 的总维度,将是64乘以64乘以3,这是三个像素矩阵中像素的总量。

所以在二分类问题中,我们的目标就是习得一个分类器,它以图片的特征向量作为输入,然后预测输出结果y为1还是0,也就是预测图片中是否有猫。
2.1 流程

(1)提取图片特征值,作为输入,(2)在隐藏层计算线性回归,并通过非线性激活函数tanh使得神经网络具有非线性拟合能力,(3)计算损失函数并通过梯度下降优化,(4)输出预测值。
2.1.1 前向传播
在单隐层神经网络中,前向传播即将参数进行计算预测,然后将结果传入下一层。
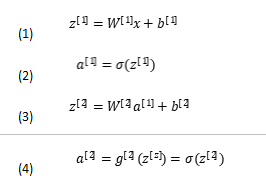
2.1.2 逻辑损失函数
损失函数又叫做误差函数,用来衡量算法的运行情况,损失函数一般有四种,平方损失函数,对数损失函数,HingeLoss0-1损失函数,绝对值损失函数。将极大似然函数取对数以后等同于对数损失函数。在逻辑回归这个模型下,对数损失函数的训练求解参数的速度是比较快的Loss function
L
(
y
^
,
y
)
L(\hat y,y)
L(y^,y):
:
我们通过这个L称为的损失函数,来衡量预测输出值和实际值有多接近。一般我们用预测值和实际值的平方差或者它们平方差的一半,但是通常在逻辑回归中我们不这么做,因为当我们在学习逻辑回归参数的时候,会发现我们的优化目标不是凸优化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值。
当 y = 1 y=1 y=1时损失函数 L = − l o g ( y ^ ) L=-log(\hat y) L=−log(y^),如果想要损失函数 L L L尽可能得小,那么 y ^ \hat y y^就要尽可能大,因为 s i g m o i d sigmoid sigmoid函数取值为 [ 0 , 1 ] [0,1] [0,1],所以 y ^ \hat y y^会无限接近于1。
当 y = 0 y=0 y=0时损失函数 L = − l o g ( 1 − y ^ ) L=-log(1-\hat y) L=−log(1−y^),如果想要损失函数 L L L尽可能得小,那么就要尽可能小,因为 s i g m o i d sigmoid sigmoid函数取值 [ 0 , 1 ] [0,1] [0,1],所以 y ^ \hat y y^会无限接近于0。
而为什么不选平方损失函数的呢?其一是因为如果使用平方损失函数,会发现梯度更新的速度和sigmod函数本身的梯度是很相关的。sigmod函数在它在定义域内的梯度都不大于0.25,这样训练会非常的慢。对数损失函数则和sigmod函数本身的梯度是无关的。这样更新的速度是可以自始至终都比较的稳定。
2.1.3 反向传播

反向传播主要用于计算梯度和导数的,用于实现梯度下降,矩阵的导数要用链式法则来求,还有一点,就是初始化神经网络的权重,不要都是0,而是随机初始化。如果把权重或者参数都初始化为0,那么梯度下降将不会起作用。
2.1.4 梯度下降
由于损失函数为凸函数,可以梯度下降通过最小化代价函数(成本函数)J(w,b)来训练的参数w和b,取得最小值。通过梯度下降求最小值,即朝最陡的下坡方向再走一步,如图所示。

实际上,沿斜坡方向向下就是通过计算导数,而每次计算完以后,需要更新参数w和b。
然后不断迭代,即重复下面的公式,然后获得最小值。
w
=
w
−
α
∂
J
(
w
)
∂
w
w=w-\alpha\frac {\partial J(w)}{\partial w}
w=w−α∂w∂J(w)
b
=
b
−
α
∂
J
(
b
)
∂
b
b=b-\alpha\frac {\partial J(b)}{\partial b}
b=b−α∂b∂J(b)
α
\alpha
α表示学习率(learning rate),用来控制步长(step),即向下走一步的长度 就是函数对 求导(derivative)。而关于学习率的选择,太慢会导致学习速度过慢,而太快会导致多次错过最优解而导致学习曲线震荡,如下图所示。

2.3 总结
(1) 逻辑回归中主要重点在于损失函数,梯度下降,反向传播,以及激活函数。
(2) 隐藏层的激活函数选择tanh函数或relu函数,使用sigmoid函数,容易出现数据过大或过小梯度趋于0的问题。
(3)梯度下降后,需要反向传播更新参数,不断迭代。
(3)学习率的选取要合适,否则会导致学习曲线震荡,同时隐藏层的节点数也需要合适,否则会出现过度拟合的现象。















 1447
1447











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









