







简单线性回归
相关定义
- 所谓简单,是指只有一个样本特征,即只有一个自变量;所谓线性,是指方程线性;所谓回归,是指可以用方程模拟自变量和因变量如何关联- 简单线性回归属于回归算法,即lablel(标签列)为连续性数值
- 数学思想,通过线性方程来预测因变量与自变量的关系
y为预测标签值, x为样本特征变量, b为截距项(调整预测值与实际值的误差) Y=ax+b
求解思路
-
确定一条直线,最大程度来拟合样本特征和样本标签值之间的关系。在二维平面,这条线就是y=ax+b

-
最佳拟合直线方程:y=ax+b。对于每个样本点,预测方程
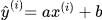
-
误差统计,计算所有样本点的真实值和y(i)和预测值y^(i)的差值作为预测误差,误差都小,证明我们找出的线程方程拟合性好
- 1.防止正误差值与负误差值相抵,使用绝对值来表示距离:
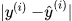
- 2.样本总误差:
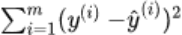
- 1.防止正误差值与负误差值相抵,使用绝对值来表示距离:
-
使用训练数据样本x,y,找到斜率和截距,是样本总误差尽可能小,得出最佳拟合方程

推导过程
- 简单来说,就是找到一组参数,是真实值与预测值的差距尽可能减小,尽可能跟你和我们的数据,这是典型机器学习算法的推到思路- 简单线性回归问题中,模型就是y = ax + b
- 损失函数(loss function):模型无法100%拟合数据,因此需要将未拟合的部分,损失降到最小。标示模型拟合程度,亦称效用函数(utility function)
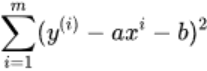
- 推导思路
1.分析问题,确定问题的损失函数 2.通过最优化损失函数,获得机器学习模型 3.对于简单线性回归问题,目标就是降低样本实际值和预测值得误差 - 最小二乘法(最小误差的平方),将线性回归损失函数的误差优化到最低,并通过其求出关于a,b线性方程的表达式
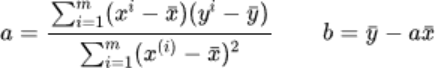
最小二乘法
- 损失函数作用,所有算法模型都依赖于最小化和最大化某一个函数,我们称之为”目标函数”
- 损失函数描述了单个样本预测值和实际值之间的误差程度。用来度量模型一次预测的好坏
- 损失函数越小,模型鲁棒性越好,亦即模型泛化能力越强,对大部分数据集都有较好预测效果
- 常用损失函数
- 0-1损失函数:用来表达分类问题,当预测分类错误时,损失值为1,正确为0
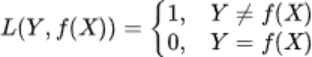
- 平方损失函数:用来描述回归问题,用来表示连续性变量,为预测值与真实值差值的的平方
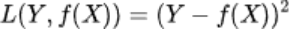
- 绝对损失函数:用在回归模型,用距离的绝对值来衡量
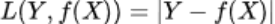
- 对数损失函数:预测值Y和条件概率之间的衡量。该函数用到极大似然估计的思想。P(Y|X):在当前模型基础上,对于样本X,其预测值为Y,也就是预测正确的概率。由于概率之间同时满足需要用乘法,为了将其转换为甲方,将其取对数。预测正确率越高,其损失值(对数值)越小,在取个反号(小于1的对数为负值)

- 0-1损失函数:用来表达分类问题,当预测分类错误时,损失值为1,正确为0
- 损失函数针对于单个样本的,但是一个训练数据集中存在N个样本,N个样本给出N个损失值,需要通过风险函数
- 期望风险,又叫损失函数的期望,用来表达理论上模型f(x)关于联合分布P(X,Y)的平均意义下的损失,又叫期望损失/风险函数
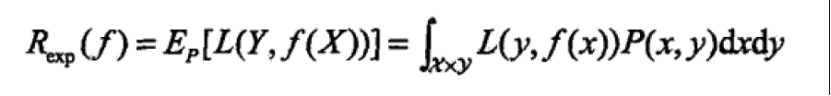
- 经验风险,将训练集的总损失定义为经验风险
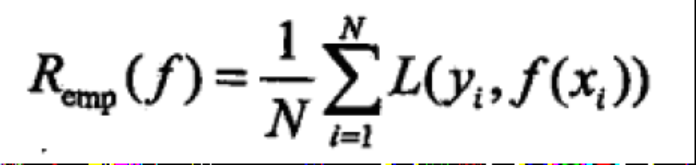
- 结构风险,其等价于正则化,环境数据集过小导致的过拟合现象,本质反应的模型复杂度,经验风险越小,参数越多,模型越复杂。虽然可以经验损失近似估计期望风险,但是大数定理的前提是N无穷大,然而实际上,训练集不会特别大,此时需要适当调整经验风险来进行近似估计。 ## 小结- 损失函数:单个样本预测值和真实值之间的误差(值)程度- 期望风险:是损失函数的期望,理论上模型f(X)关于联合分布P(X,Y)的平均意义的损失- 经验风险:模型关于训练集(所有样本实际值和预测值的误差值的平均值)得平均损失,即每个样本损失加起来,再平均一下- 结构风险: 在经验风险加一个正则化像做惩罚项,防止数据分布、数量小等原因引起的过拟合
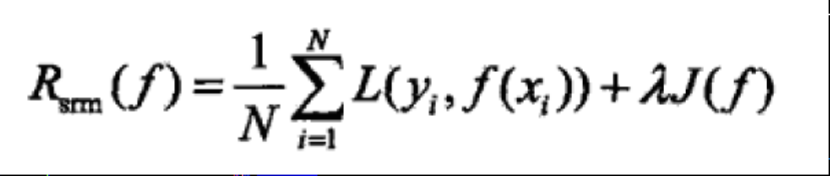
最小二乘法
-
所谓二乘,就是平方的意思。高斯证明过:如果误差分布是正太分布,那么最小二乘法得到就是最有可能的值
-
最小二乘法来自数学家阿德里安的猜想: 对于测量值来说,让总的误差平方最小就是真实值。这是基于,如果误差是随机的,应该围绕真值上下波动。因为误差为确定值,还要去绝对值,计算麻烦,故用平方代表误差。
- 单个样本误差
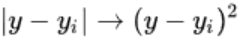
- 训练集总的误差

- 单个样本误差
-
数学猜想符合直觉,其为一个二次函数,对其求导,导数为0时取得最小(高数中范围内判断极最值的定理)
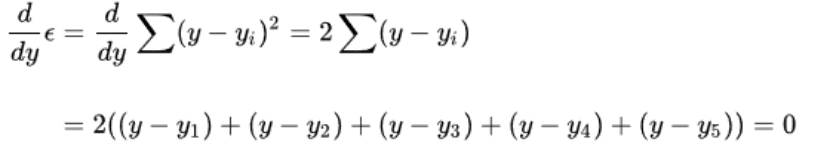
-
继而有,正好是算术平均数,可以让误差最小
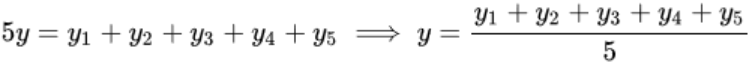
-
算术平均数只是最小二乘法的特例,使用范围较窄,而最小二乘法应用广泛,如温度与冰激凌的销量之间的关系- 冰激凌与温度的关系

-
如用线性关系去刻画,会有如下结果,可以假设该线性关系为:f(x)=ax+b

-
如用最小二乘法来表示

-
上图i,x,y分别为

- 总误差的平方为
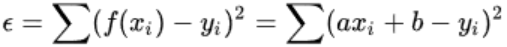
- 通过多元微积分对a,b(不同a,b会导致不同误差)求偏导得
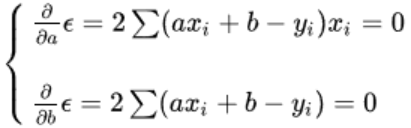
- 这时候误差取最小值,通过解得上述方程组,得出a=7.2,b=-73,为近似值。刻画关系为:

- 总误差的平方为
简单逻辑回归代码实现
- python实现
import numpy as np
class SimpleLogisticRegression:
def __init__(self):
pass
@staticmethod
def get_input_data():
x = np.array([1., 2., 3., 4., 5.])
y = np.array([1., 3., 2., 3., 5])
return x,y
def get_a_b(self, x, y):
"""
根据训练集,和标签值计算线性关系的斜率和截距
使用直线关系去拟合,根据最小二乘法推到求出a,b表达式
a = all( Xi- avg(x)) /all(Xi-avg(x))^2 b = avg(y) - a*avg(x)
:param x:
:param y:
:return:
"""
x_mean = np.mean(x)
y_mean = np.mean(y)
# a的分子num,分母d
num = 0.0
d = 0.0
# zip将集合x,y按原始排列顺序合并在一起
# 打包成[(x_1,y_1),(x_2,y_2),...,(x_n,y_n)]
for x_i, y_i in zip(x, y):
num = num + (x_i - x_mean)*(y_i - y_mean)
d = d + (x_i - x_mean) ** 2
a = num / d
b = y_mean - a * x_mean
return a, b
@staticmethod
def get_linear_function(a,b,x):
y_hat = a * x + b
return y_hat
if __name__ == '__main__':
demo = SimpleLogisticRegression()
x,y = SimpleLogisticRegression.get_input_data()
a,b = demo.get_a_b(x,y)
# 预测标签值
predict_value = demo.get_linear_function(a,b,3.0)
"{}的值为{}".format(3.0,predict_value) ````














 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









