







 文章介绍了在机器学习中评估模型性能的方法,包括训练集、测试集和验证集的划分,以及如何利用验证集选择模型的超参数。此外,还讨论了偏差和方差的概念,正则化对模型的影响,以及如何通过学习曲线来判断模型是高偏差还是高方差。
文章介绍了在机器学习中评估模型性能的方法,包括训练集、测试集和验证集的划分,以及如何利用验证集选择模型的超参数。此外,还讨论了偏差和方差的概念,正则化对模型的影响,以及如何通过学习曲线来判断模型是高偏差还是高方差。
2022吴恩达机器学习(Deep learning)课程对应笔记27
评估模型的方法

更新时间:2023/03/22
在训练了一个模型后,我们需要一个系统的方法来评估模型的性能。如下图

不要把所有的数据都用做训练集,要划分成训练集 测试集和验证集,部分数据用来训练模型,部分数据用来测试模型的性能

下面是一个对线性回归模型训练和测试过程的例子,说明模型表现的往往是模型在测试集上的表现。注意在模型计算测试集的代价函数时,是不需要加正则化项的。

下面是分类问题的例子

模型选择和交叉验证

如下图的例子, 通过测试集俩检测模型的泛化性能是一个不错的想法

但是如下面这个例子,当用测试集来选择模型的其他参数时,比如多项的维度d,可能会丢失测试集检测泛化性的能力。

改进方法是重新切分数据集:切分为训练集测试集和验证集。

那么对应的训练测试验证误差如下所示:
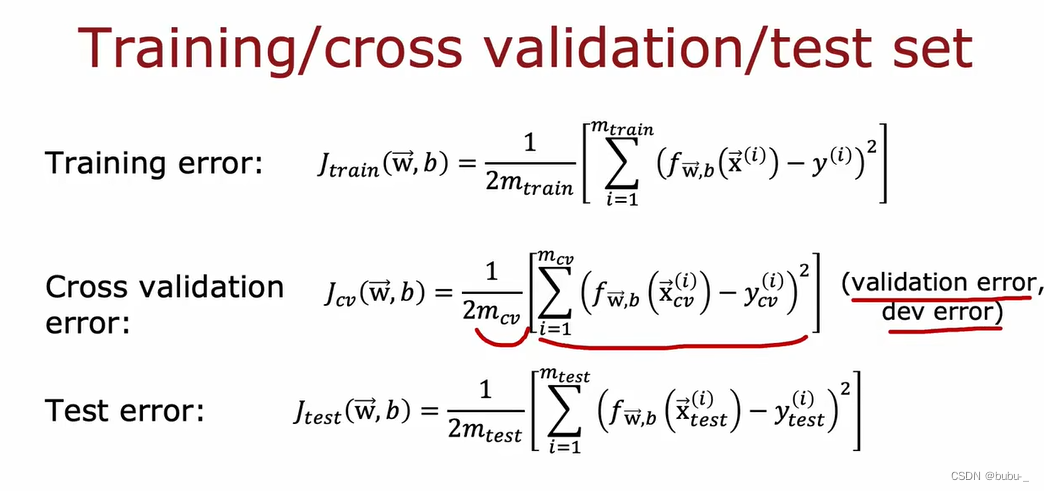
那么在模型选择其它超参数时就可以用验证集来选择超参数了,而不是测试集,测试集只用来评估模型的泛化性,这样做的目的就是不能让测试集提前暴露给模型。

偏差和方差

偏差和方差的例子如下
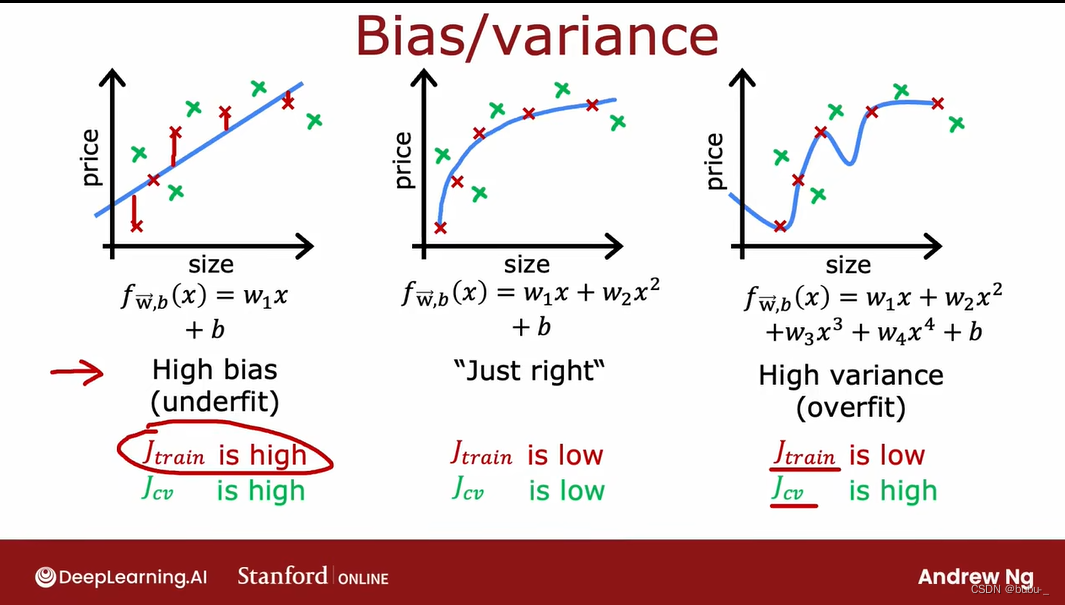
理解偏差和方差

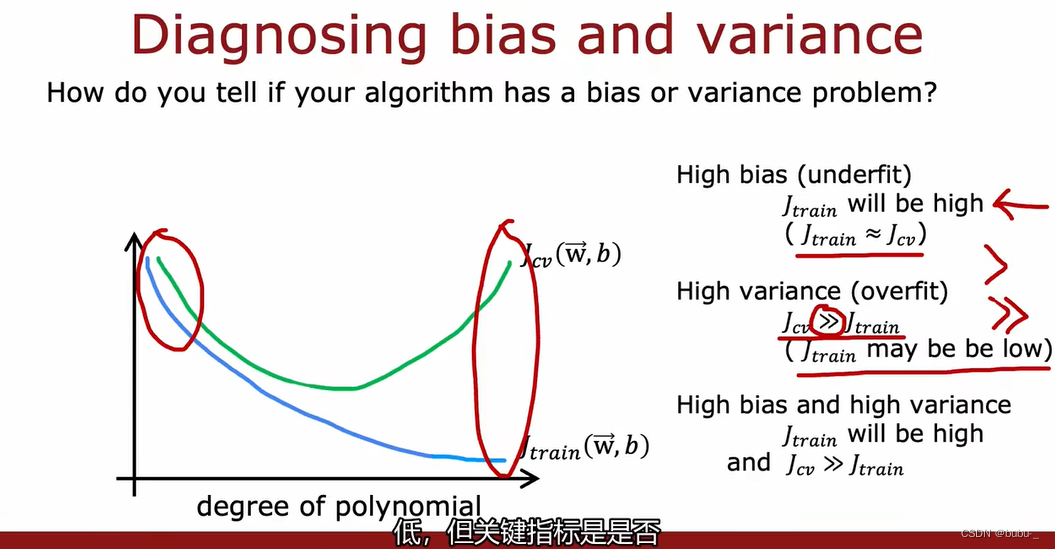
诊断偏差和方差
- 高偏差(欠拟合), J t r a i n J_{train} Jtrain将会很高,并且 J t r a i n ≈ J c v J_{train} \approx J_{cv} Jtrain≈Jcv。
- 高方差(过拟合), J c v ≫ J t r a i n J_{cv}\gg J_{train} Jcv≫Jtrain,但是 J t r a i n J_{train} Jtrain将会很低。
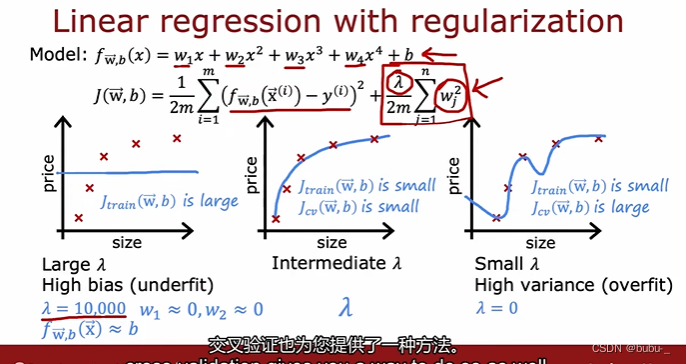
正则化对模型偏差和方差的影响

在正则化项中的正则化系数 l a m b d a lambda lambda对模型的影响也很大,
- 如果 l a m b d a lambda lambda过大,会导致 w ⃗ \vec{w} w过小,那么模型预测结果基本就是b,
- 如果 l a m b d a lambda lambda过小,会导致 w ⃗ \vec{w} w过大,那么模型很容易过拟合
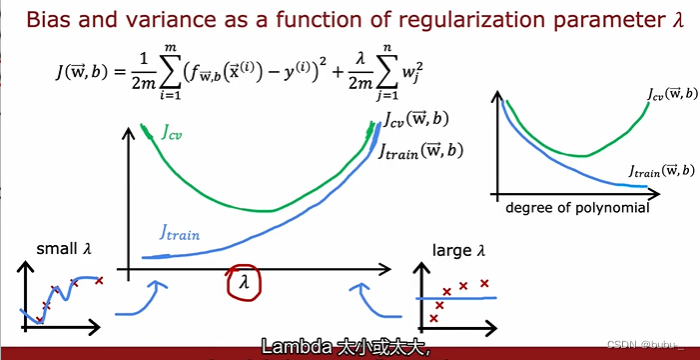
选择合适的正则化参数 l a m b d a lambda lambda
用验证集的结果来选择合适的 l a m b d a lambda lambda

验证集和训练集的代价函数值随着 l a m b d a lambda lambda的增加而变化的曲线如下
判断一个模型的表现


我们要找到一个合理的baseline才能够判断我们模型到底是高偏差还是高方差

下面是有了基线实验之后,根据模型的训练集和验证集变现,来判断模型是高偏差还是方差的方案

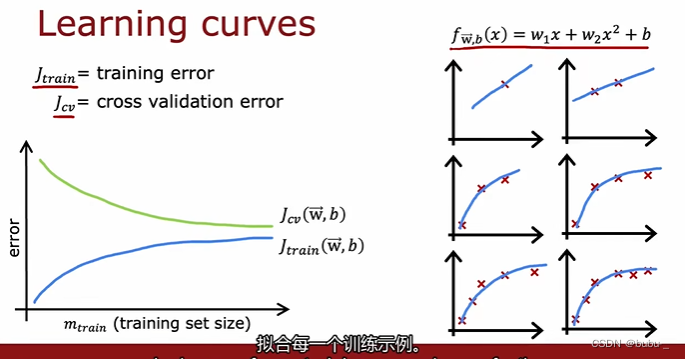
学习曲线

学习曲线是一种帮助你了解学习算法性能如何的方式,曲线随着训练集的数量发生变化。
high bias的学习曲线
当模型本身就是高偏差时,丢进更多的训练集是没有作用的

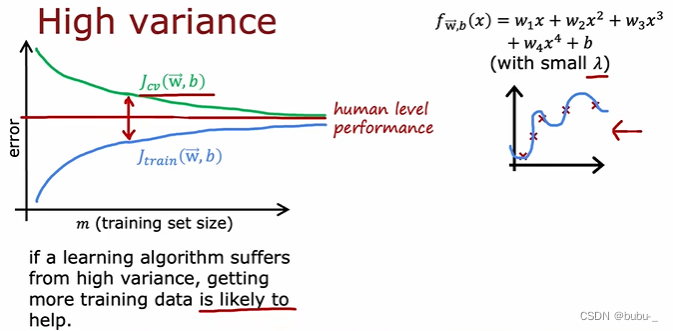
high variance的学习曲线
当模型是高方差时,获得更多的训练集可能会有用
下面这几种情况可以记一下


我们要 在模型复杂度和偏差方差之间做一个权衡

方差与偏差
事实证明,在中小型规模的数据集上训练的大规模神经网络模型都是低偏差模型。下面是训练流程

一个大型的神经网络通常比小网络做得更好,只有它足够正则化。下面代码



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









