







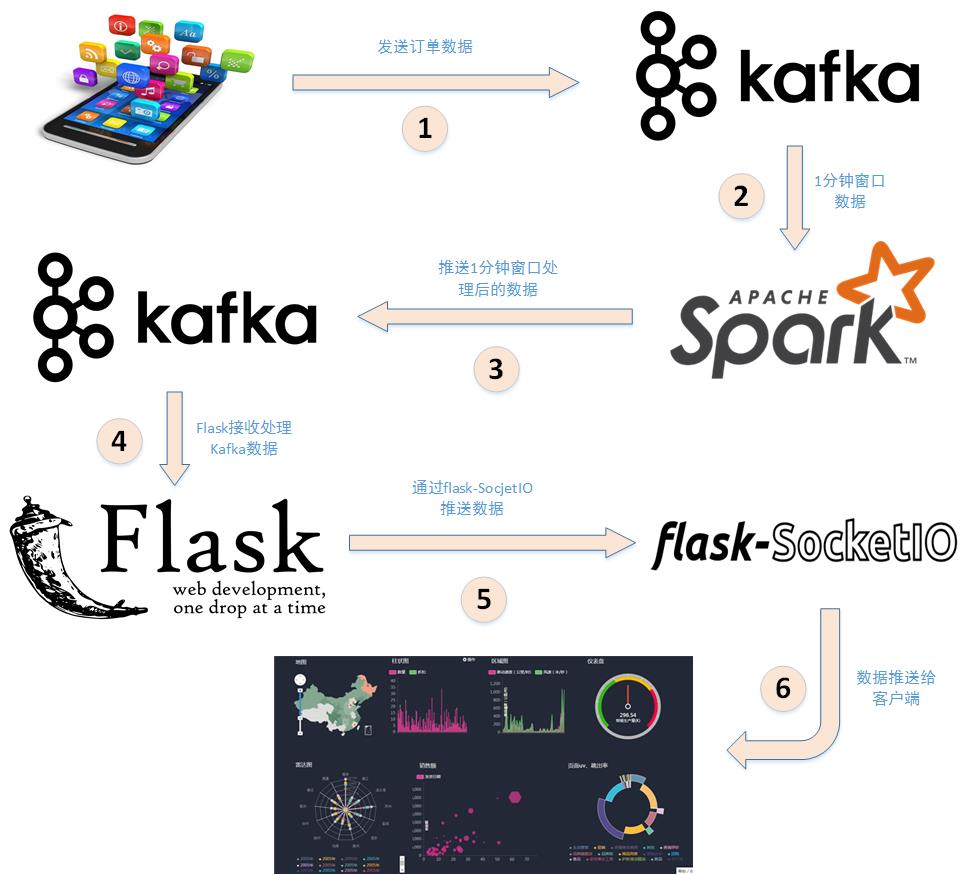
下面分析详细分析下上述步骤:
- 应用程序将购物日志发送给Kafka,topic为”sex”,因为这里只是统计购物男女生人数,所以只需要发送购物日志中性别属性即可。这里采用模拟的方式发送购物日志,即读取购物日志数据,每间隔相同的时间发送给Kafka。
- 接着利用Spark Streaming从Kafka主题”sex”读取并处理消息。这里按滑动窗口的大小按顺序读取数据,例如可以按每5秒作为窗口大小读取一次数据,然后再处理数据。
- Spark将处理后的数据发送给Kafka,topic为”result”。
- 然后利用Flask搭建一个web应用程序,接收Kafka主题为”result”的消息。
- 利用Flask-SocketIO将数据实时推送给客户端。
- 客户端浏览器利用js框架socketio实时接收数据,然后利用js可视化库hightlights.js库动态展示。
至此,本案例的整体架构已介绍完毕。
一、实验环境准备
实验系统和软件要求
Ubuntu: 16.04
Spark: 2.1.0
Scala: 2.11.8
kafka: 0.8.2.2
Python: 3.x(3.0以上版本)
Flask: 0.12.1
Flask-SocketIO: 2.8.6
kafka-python: 1.3.3
系统和软件的安装
Spark安装(前续文档已经安装)
Kafka安装
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群机来提供实时的消费。下面介绍有关Kafka的简单安装和使用, 简单介绍参考KAFKA简介, 想全面了解Kafka,请访问Kafka的官方博客。
我选择的是kafka_2.11-0.10.1.0.tgz(注意,此处版本号,在后面spark使用时是有要求的,见集成指南)版本。
sudo tar -zxf kafka_2.11-0.10.1.0.tgz -C /usr/local cd /usr/local sudo mv kafka_2.11-0.10.1.0/ ./kafka sudo chown -R hadoop ./kafka接下来在Ubuntu系统环境下测试简单的实例。Mac系统请自己按照安装的位置,切换到相应的指令。按顺序执行如下命令:
cd /usr/local/kafka # 进入kafka所在的目录
bin/zookeeper-server-start.sh config/zookeeper.properties命令执行后不会返回Shell命令输入状态,zookeeper就会按照默认的配置文件启动服务,请千万不要关闭当前终端.启动新的终端,输入如下命令:
cd /usr/local/kafka
bin/kafka-server-start.sh config/server.propertieskafka服务端就启动了,请千万不要关闭当前终端。启动另外一个终端,输入如下命令:
cd /usr/local/kafka
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dblabtopic是发布消息发布的category,以单节点的配置创建了一个叫dblab的topic.可以用list列出所有创建的topics,来查看刚才创建的主题是否存在。
bin/kafka-topics.sh --list --zookeeper localhost:2181 可以在结果中查看到dblab这个topic存在。接下来用producer生产点数据:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dblab并尝试输入如下信息:
hello hadoop
hello xmu
hadoop world然后再次开启新的终端或者直接按CTRL+C退出。然后使用consumer来接收数据,输入如下命令:
cd /usr/local/kafka
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic dblab --from-beginning 便可以看到刚才产生的三条信息。说明kafka安装成功。
Python安装
Ubuntu16.04系统自带Python2.7和Python3.5,本案例直接使用Ubuntu16.04自带Python3.5;
Python依赖库
案例主要使用了两个Python库,Flask和Flask-SocketIO,这两个库的安装非常简单,请启动进入Ubuntu系统,打开一个命令行终端。
Python之所以强大,其中一个原因是其丰富的第三方库。pip则是python第三方库的包管理工具。Python3对应的包管理工具是pip3。因此,需要首先在Ubuntu系统中安装pip3,命令如下:
sudo apt-get install python3-pip安装完pip3以后,可以使用如下Shell命令完成Flask和Flask-SocketIO这两个Python第三方库的安装以及与Kafka相关的Python库的安装:
pip3 install flask
pip3 install flask-socketio
pip3 install kafka-python这些安装好的库在我们的程序文件的开头可以直接用来引用。比如下面的例子。
from flask import Flask
from flask_socketio import SocketIO
from kafka import KafkaConsumerfrom import 跟直接import的区别举个例子来说明。
import socket的话,要用socket.AF_INET,因为AF_INET这个值在socket的名称空间下。
from socket import* 是把socket下的所有名字引入当前名称空间。
二、数据处理和Python操作Kafka
本案例采用的数据集压缩包为data_format.zip点击这里下载data_format.zip数据集,该数据集压缩包是淘宝2015年双11前6个月(包含双11)的交易数据(交易数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9422
9422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









